Code 4 San Francisco Hack Nite Highlights
by Jules Damji
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
Try this notebook in Databricks
For a speechwriter, JFK’s words “Ask not what your country can do for you. Ask what you can do for your country” serve as a rhetorical device; for a community organizer, they serve as a spark to ignite change. These immortal words, to some extent, have engendered enduring movements like Peace Corps, Teach for America, and Code for America, with local brigades.
One local brigade, Code 4 San Francisco (C4SF), meets each week where local community of developers work on civic projects, using datasets from SF Open Data, to make local government agencies efficient.
A couple of weeks ago, C4SF had Hack Nite hosted at Microsoft Reactor. And Databricks participated, where over 100 local data scientists gathered to analyze 16 years of San Francisco’s emergency call records during a July 4th weekend, through a hands-on workshop using Databricks Community Edition. SF Open Data Program Manager Jason Lally expressed his thoughts in this tweet about the hack nite.
.@blueplastic of @databricks gives excellent demo of @ApacheSpark using #SF #opendata from the Fire Dept via @DataSF https://www.youtube.com/watch?v=K14plpZgy_c
— Jason Lally (@synchronouscity) July 19, 2016
Led by Sameer Faroqui, Databricks’ senior instructor and client solution engineer, the data science workshop covered core concepts, through interactive sessions using the Databricks Community Edition, followed by step-by-step exploration of a public data set to answer a question: How did the 4th of July holiday affect demand for Firefighters?
Attendees signed up for Databricks Community Edition on spot and uploaded 1.6 GB of fire emergency calls data with over 4 million records from SF OpenData. Following a set of guided queries in their individual Python notebooks, and coding with Apache Spark 2.0’s DataFrame APIs, they extracted, explored and examined fire emergency calls data by executing each query on their provisioned Spark cluster. The exploratory workshop was an exercise in extract, transform, and load (ETL), a typical use case workload, and how to use Apache Spark 2.0 DataFrame’s API in Python.
Exploring Fire Emergency Calls
Let’s consider a few queries we explored during our workshop, revealing unexpected insights on the 4th of July calls.
Q: How many different and distinct types of calls were made to the Fire Department?
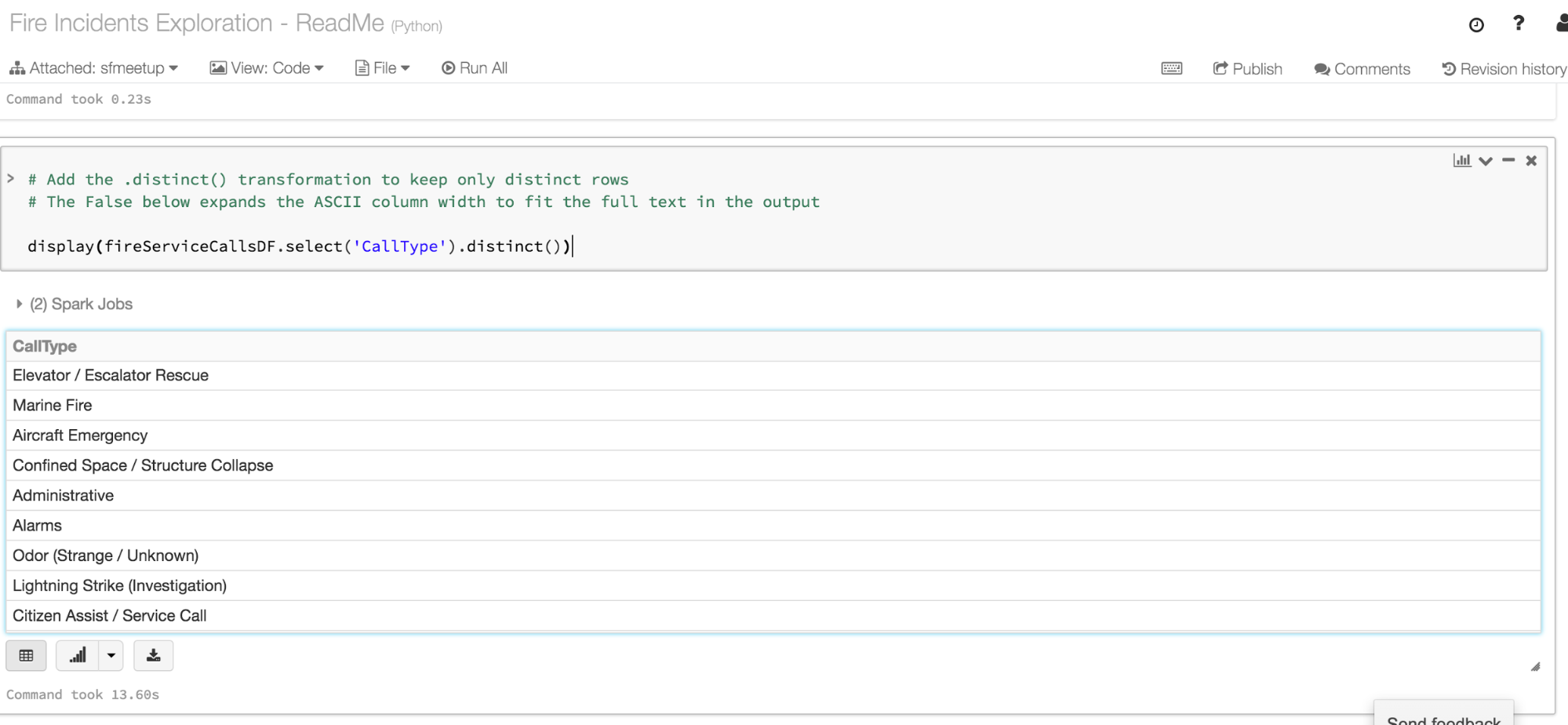
Q: How many incidents of each call type were there?
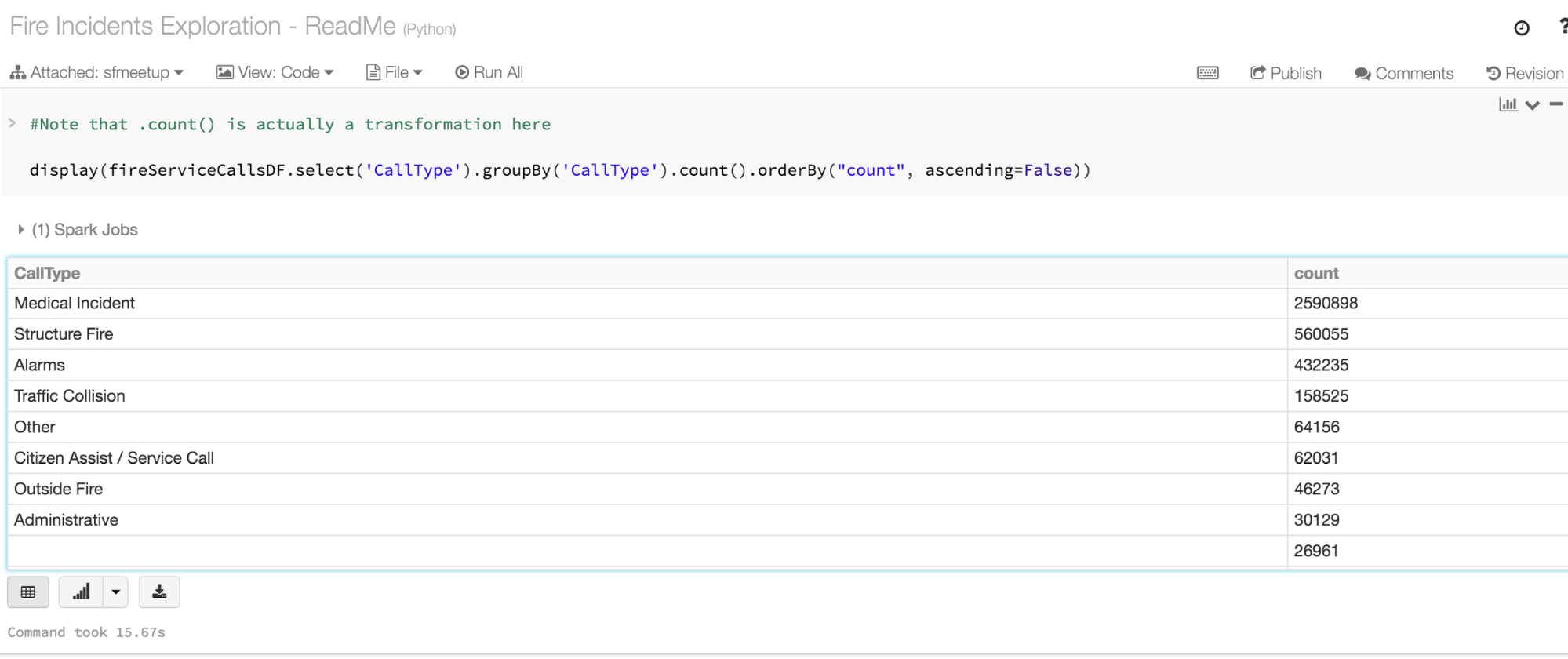
Q: How many service calls were logged in the past 7 days?
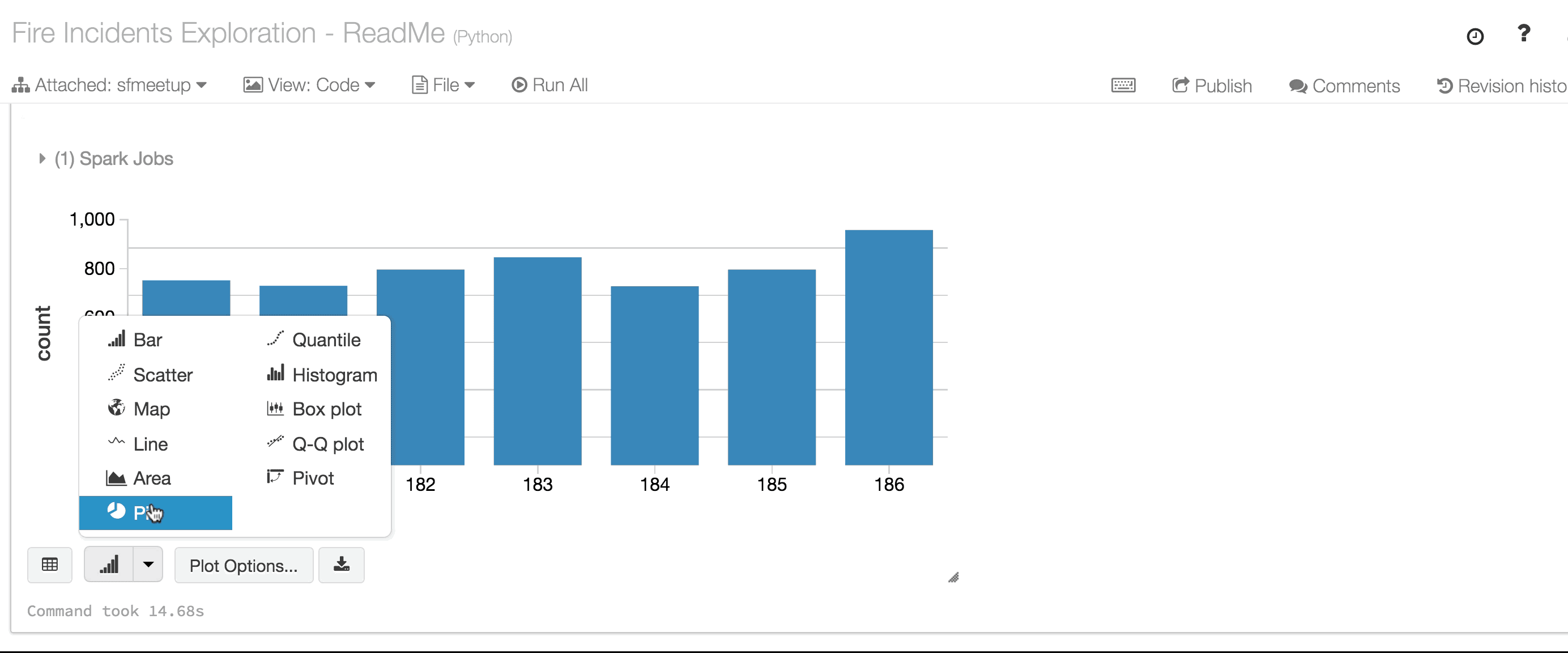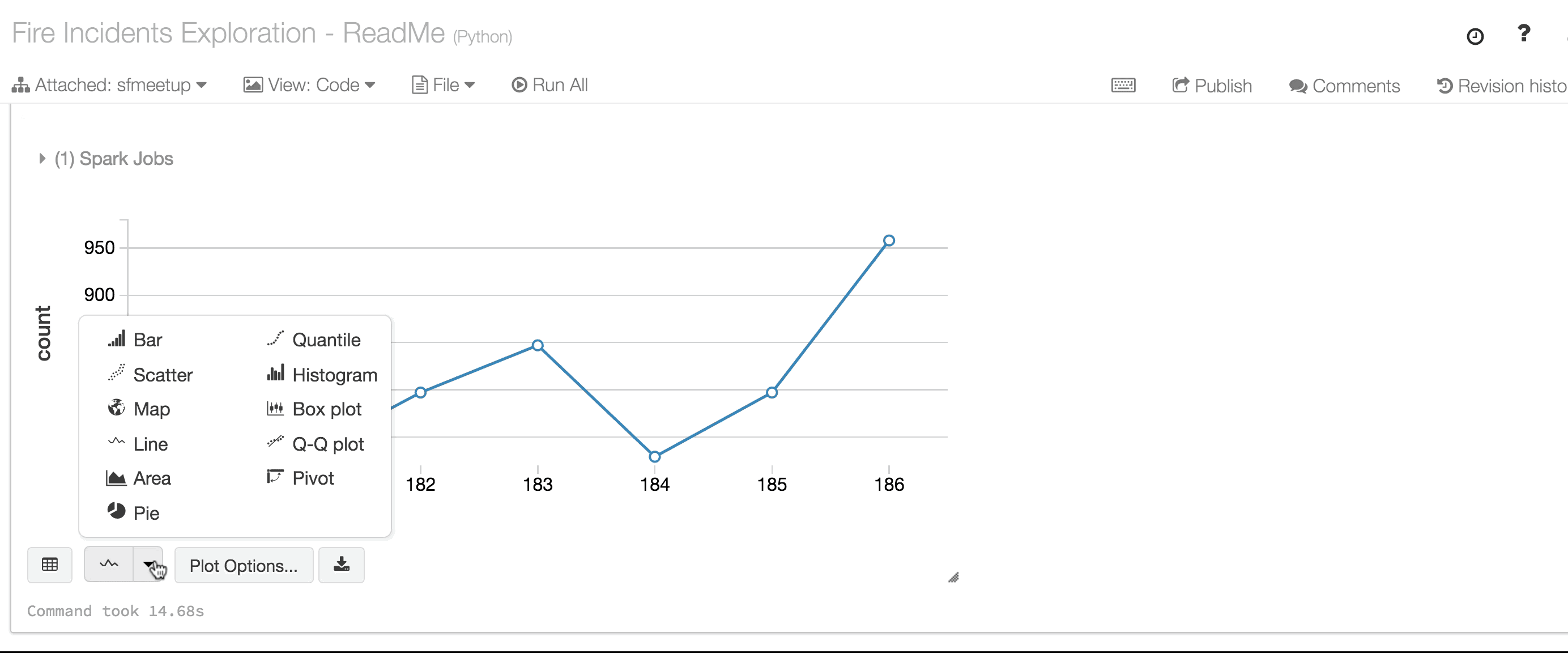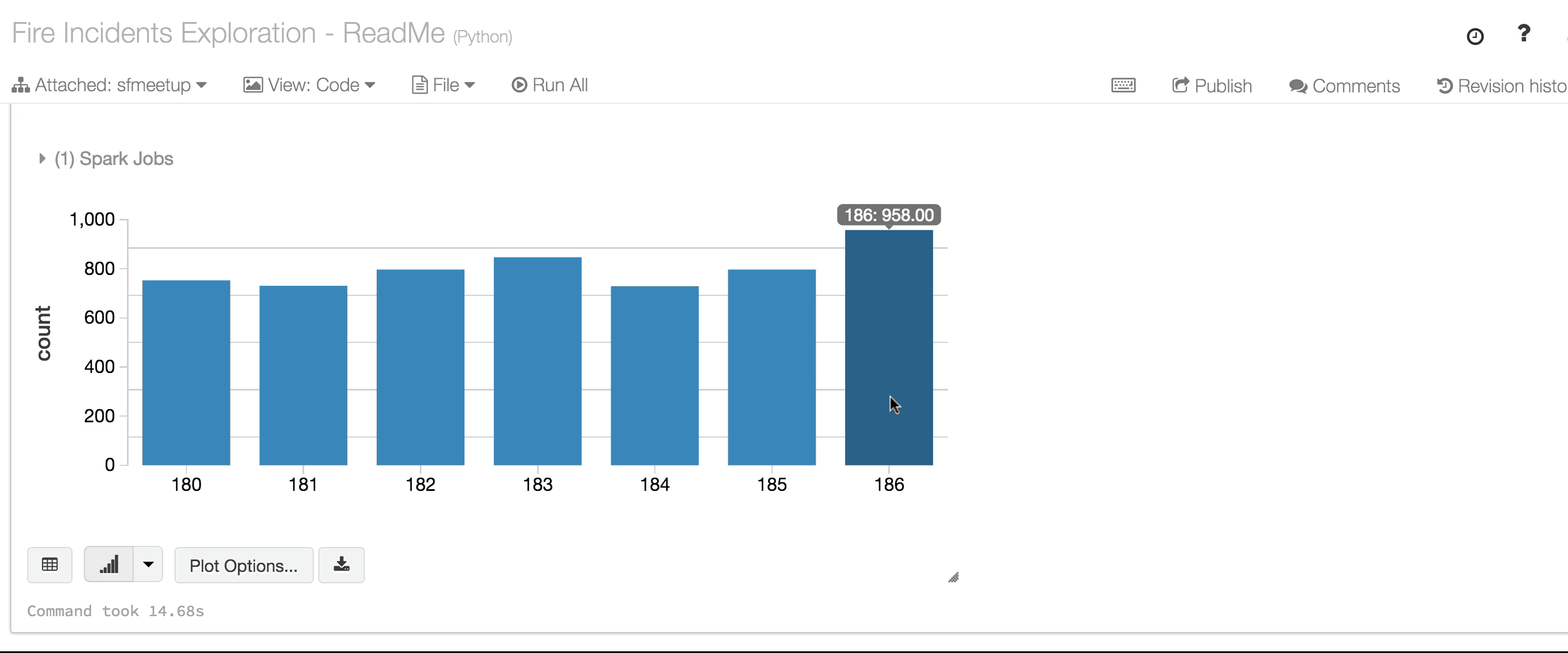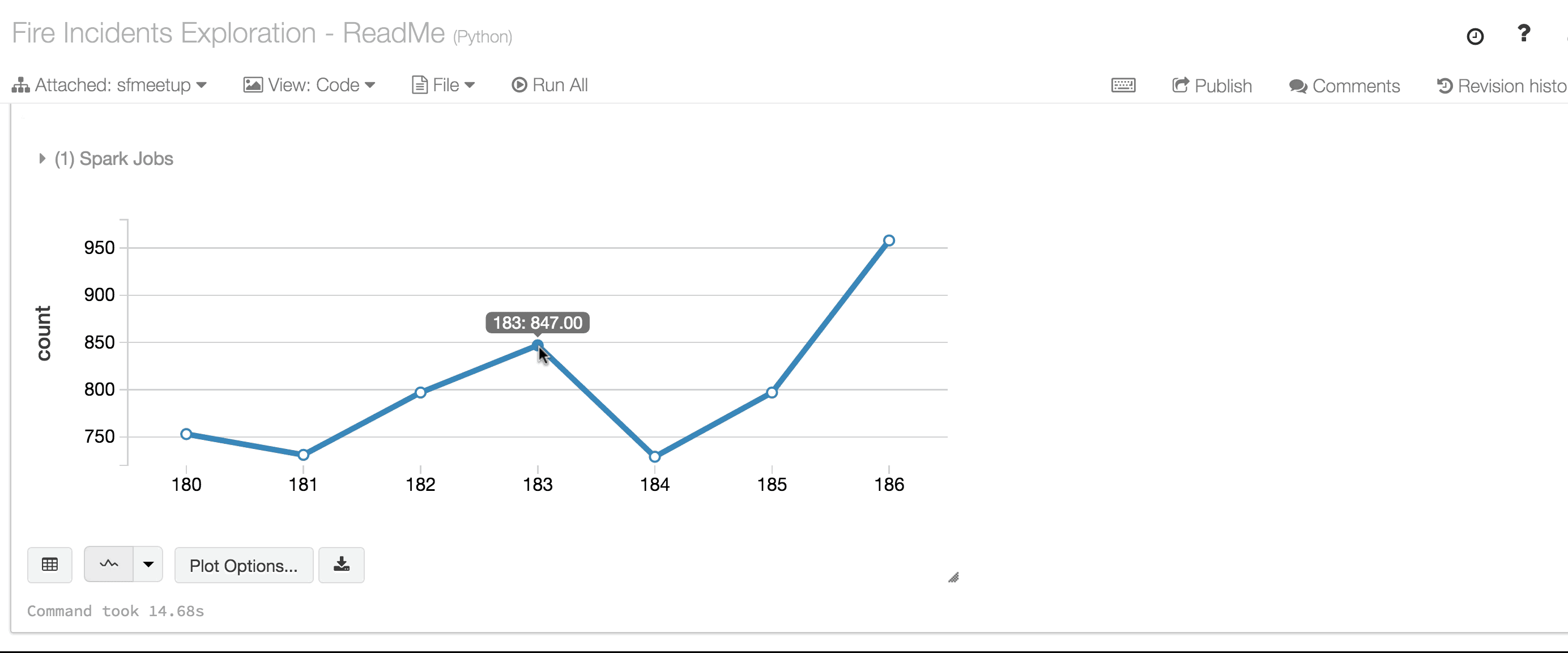
With elaboration on how Spark executes these queries on clusters, the workshop led the participants through further transformation of data, to gain insightful queries using time analysis and visualization.
Data scientists in the crowd learned not only how-to use but also when-to use DataFrames as well as under the hood tips and tricks in performance and optimizing queries. For instance, reading large dataset of parquet files (columnar formatted) is significantly faster than reading CVS or JSON files, and caching DataFrames, once read as parquet files from disk, significantly accelerates the query times.
Switching seamlessly between DataFrames and SQL queries in their notebooks, the attendees explored SF’s Fire calls—and a few notable insights emerged.
Q: Which neighborhood in SF generated the most calls last year?
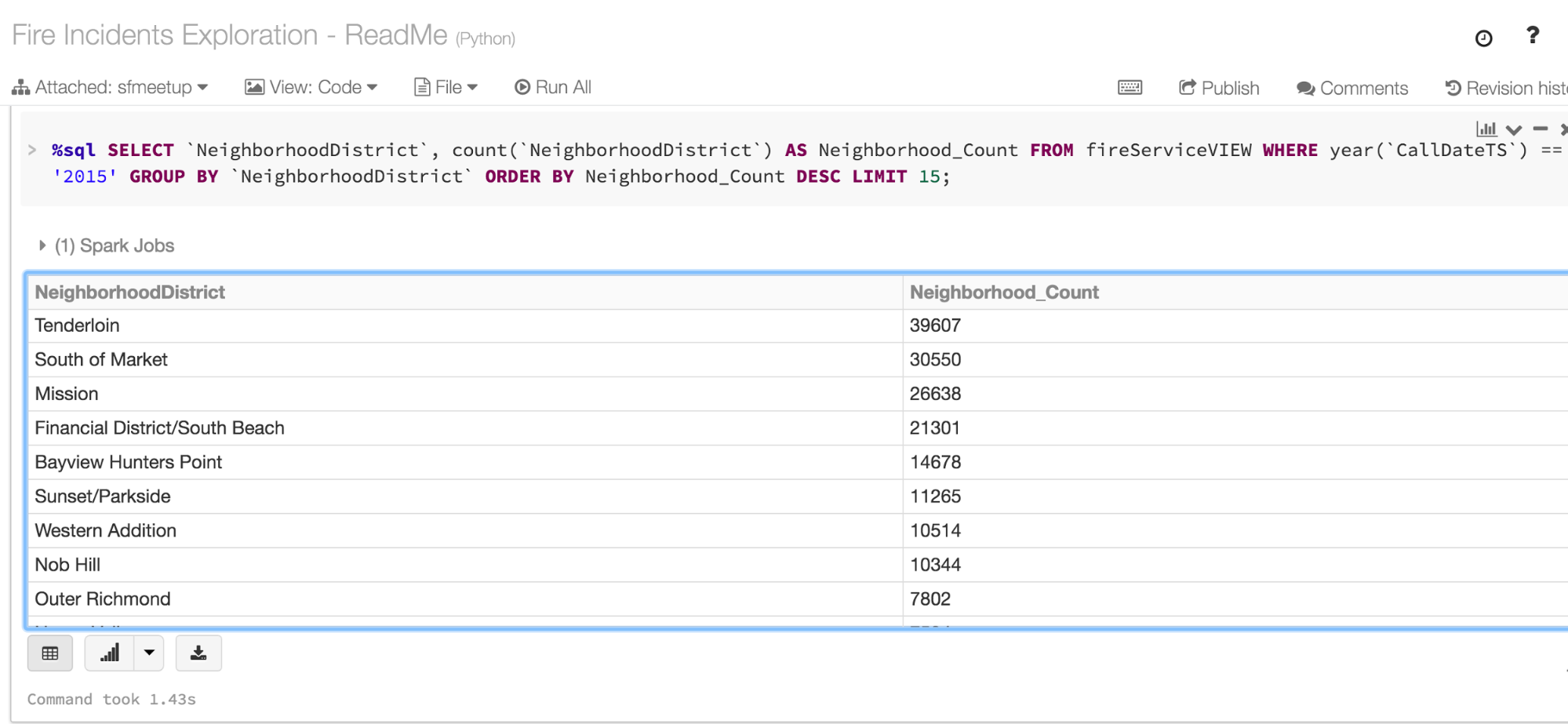
By joining DataFrames from two distinct datasets, we explored how neighborhood type of incidents data and fire calls data were related.
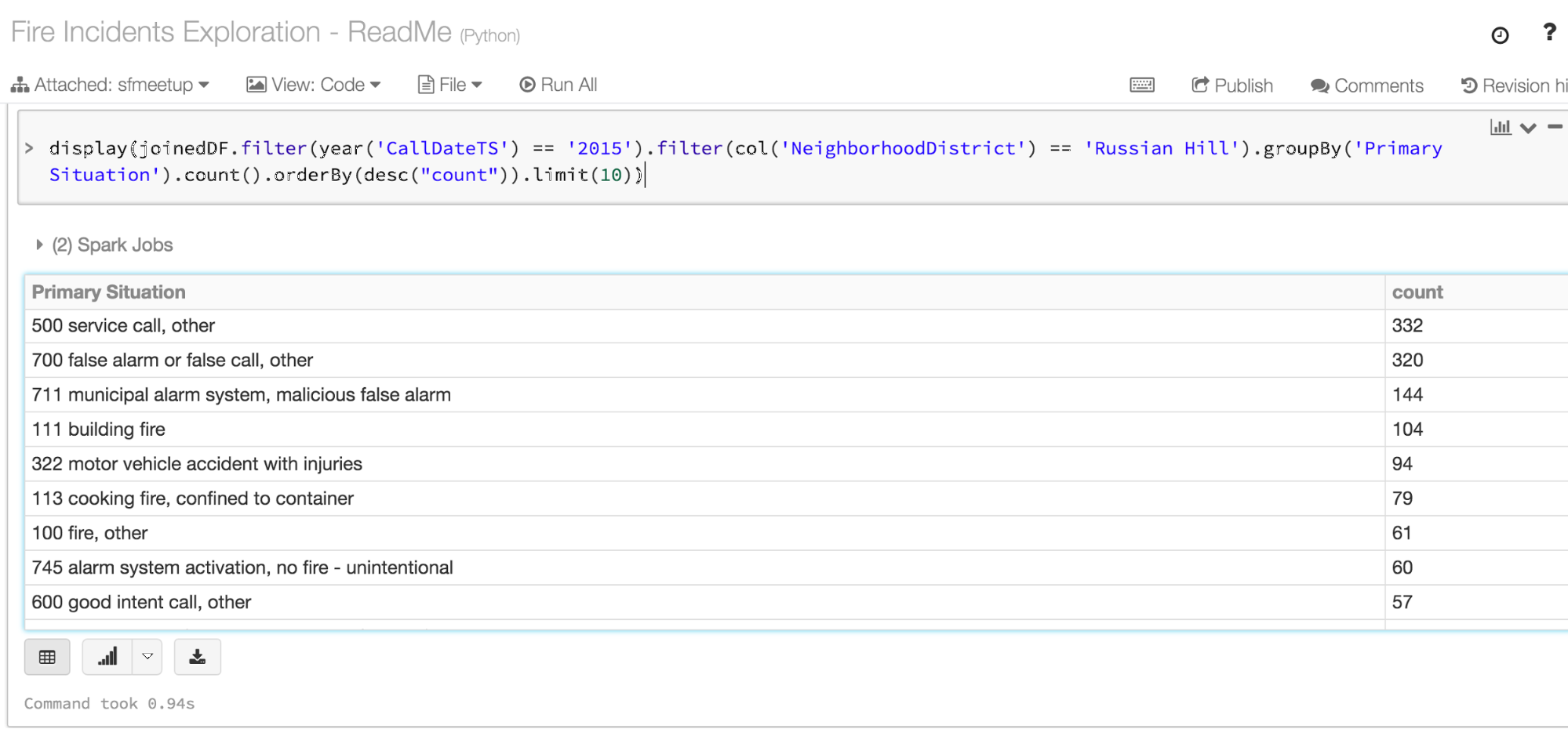
Q: What was the primary non-medical reason most people called the fire department from the Tenderloin and Russian Hill last year?
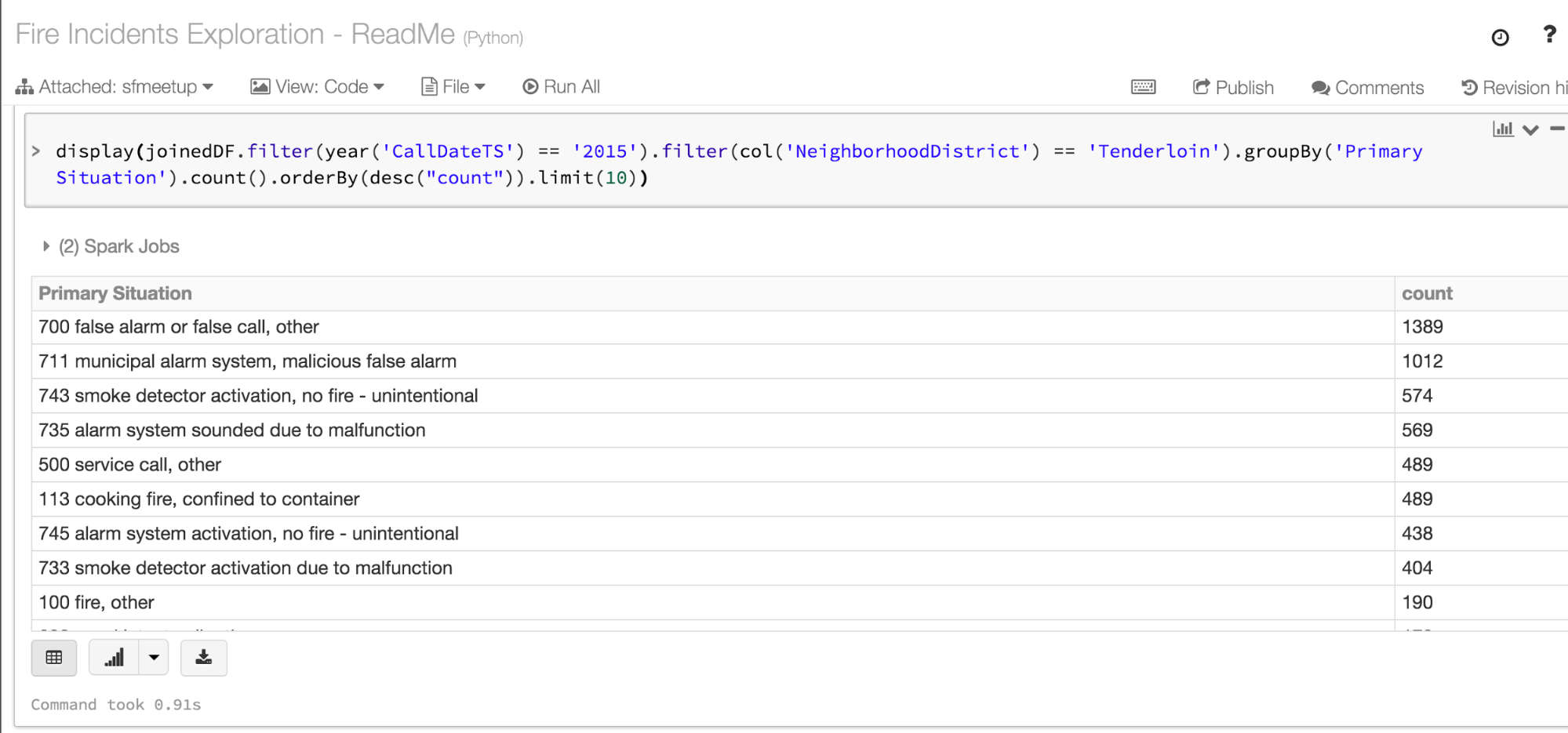
As for the Russian Hill, a good number, as you can observe, were false alarms too, with a fourth less calls than Tenderloin.
Local Projects Making A Difference
Beyond offering workshop about Apache Spark on Databricks and exploring local emergency calls, the camaraderie in sharing with the members of the local SF brigade was rewarding, too. One member commented on the C4SF meetup page: “Great session to get you started with Databrick Community Edition and sources of open data in SF.”
One project, according to C4SF, that emerged from weekly hack nights for the local community is Adopt a Drain, which helps the city avoid flooding by clearing the drains of debris. Pleased with the outcome of the civic project, Jean Walsh of California Public Utilities recognized its merits with this tweet.
Jean Walsh of @SFwater presents certificate of appreciation to @sfbrigade for Adopt-a-Drain: https://adoptadrain.sfwater.org/
— CivicMakers (@CivicMakers) June 5, 2016
Perusing other local civic projects underway that benefit citizenry reassures me that JFK’s immortal words uttered decades ago still inspire many local brigades’ captains, in their purpose and passion to make a difference in their local community—and by extension in their country.
We hope that people who gathered at this meetup who learned Apache Spark using Databricks to explore SF OpenData will employ the knowledge acquired in their civic projects.
We want to thank our co-sponsors Microsoft for hosting us and C4SF’s local brigades for inviting us to be part of this rewarding Hack Nite.
Join the C4SF brigade for their next Hack Nite!
What’s Next?
If you missed the Hack Nite, you can still partake in exploring the City of San Francisco open data with Apache Spark 2.0. Here are the steps:
- Sign up for Databricks Community Edition (DCE)
- Import this Notebook folder into DCE
- Run the dataset_mounts notebook
- Run the File Incident Exploration notebook
- If you want training, visit Databricks Training or our training partners, Newcircle.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.