Voice from CERN: Apache Spark 2.0 Performance Improvements Investigated With Flame Graphs
by Luca Canali
This is a guest post from CERN, the European Organization for Nuclear Research. In this blog, Luca Canali of CERN investigates performance improvements in Apache Spark 2.0 from whole-stage code generation using flame graphs. The blog was originally posted on the CERN website. Luca will be speaking at Spark Summit Europe Oct 25 - 27 on this topic.
Introduction
The idea for this post comes from a performance troubleshooting case that has come up recently at CERN database services. It started with a user reporting slow response time from a query for a custom report in a relational database. After investigations and initial troubleshooting, the query was still running slow (running in about 12 hours). It was understood that the query was mostly running "on CPU" and spending most of its time in evaluating a non-equijoin condition repeated 100s of millions of times. Most importantly it was also found that the query was easily parallelizable, this was good news as it meant that we could simply "throw hardware at it" to make it run faster. One way that the team (see the acknowledgments section at the end of the post) used to parallelize the workload (without affecting the production database), is to export the data to a Hadoop cluster and run the query there using Spark SQL (the cluster used has 14 nodes, installed with CDH 5.7, Spark version 1.6). This way it was possible to bring the execution time down to less than 20 minutes. All this with relatively low effort, as the query could be run basically unchanged.
Apache Spark 2.0 enters the scene
As I write this post, Apache Spark 1.6 is installed in our production clusters and Apache Spark 2.0 is still relatively new (it has been released at the end of July 2016). Notably Spark 2.0 has very interesting improvements over the previous versions, among others improvements in the area of performance that I was eager to test (see this blog post by Databricks)
My first test was to try the query discussed in the previous paragraph on a test server with Spark 2.0 and I found that it was running considerably faster than in the tests with Spark 1.6. The best result I achieved, this time a large box with 60 CPU cores and using Spark 2.0, was an elapsed time of about 2 minutes (to be compared with 20 minutes in Spark 1.6). I have previously noticed Spark 1.6 and Impala 2.5 performed comparably on our workloads, but I’m impressed by Spark 2.0’s speedups over Spark 1.6, so I decided to investigate further.
The test case
Rather than using the original query and data, I will report here on a synthetic test case that hopefully illustrates the main points of the original case and at the same is simple and easy to reproduce on your test systems, if you wish to do so. This test uses pyspark, the Python interface to Spark (if you are not familiar with how to run Spark, see further on in this post some hints on how to build a test system).
The preparation of the test data proceeds as follows: (1) it creates a DataFrame and registers it as table "t0" with 10 million rows. (2) Table t0 is used to create the actual test data, which is composed of an "id" column and three additional columns of randomly generated data, all integers. The resulting DataFrame is cached in memory and "registered" as a temporary table called "t1". Spark SQL interface for DataFrames makes this preparation task straightforward:
The following commands are additional checks to make sure the table t1 has been created correctly and is first read into memory. In particular, note that "t1" has the required test_numrows (10M) rows and the description of its column from the output of the command "desc":
The actual test query is here below. It consists of a join with two conditions: an equality predicate on the column bucket, which becomes an obvious point of where the query can be executed in parallel, and a more resource-intensive non-equality condition. Notably the query has also an aggregation operation. Some additional boilerplate code is added for timing the duration of the query:
Drilling down into the execution plans
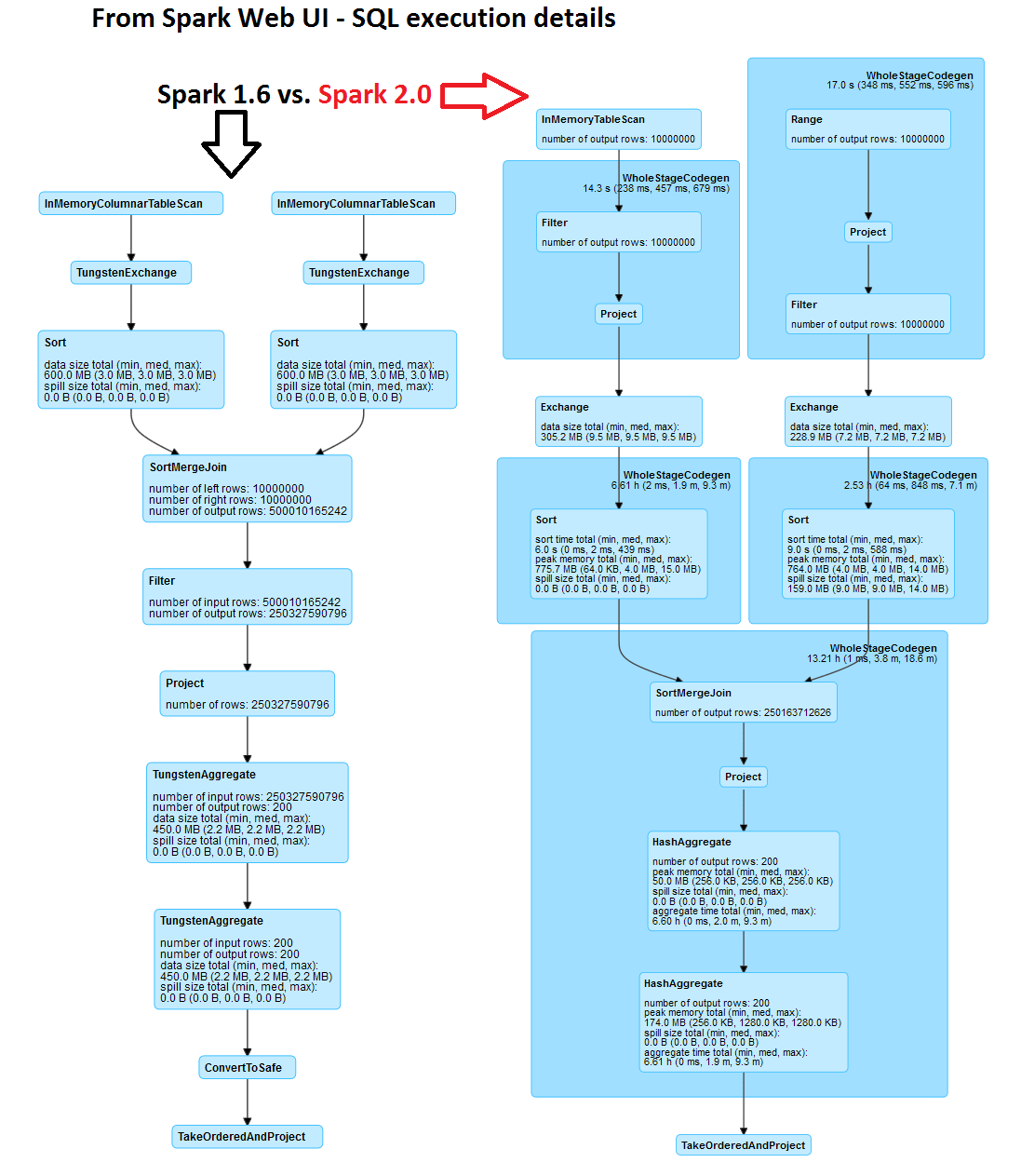
The physical execution plan generated and executed by Spark (in particular by Catalyst, the optimizer and Tungsten, the execution engine) has important differences in Spark 2.0 compared to Spark 1.6. The logical plan for executing the query however deploys a sort merge join in both cases. Please note in the execution plans reported below that in the case of Spark 2.0 several steps in the execution plan are marked with a star (*) around them. This marks steps optimized with whole-stage code generation.
Physical execution plan in Spark 1.6
Note that a sort merge join operation is central to the execution plan of this query. Another important step after the join is the aggregation operation, used to compute "sum(a.val2)" as seen in the query text: 
Physical execution plan in Spark 2.0
Note in particular the steps marked with (*), they are optimized with whole-stage code generation: 
Code generation is the key
The key to understand the improved performance is with the new features in Spark 2.0 for whole-stage code generation. This is expected and detailed for example in the blog post by DataBricks Engineering Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop Deep dive into the new Tungsten execution engine. The main point is that Spark 2.0 compiles query execution into bytecode that is then executed, as opposed to looping with an iterator over result sets. A detailed discussion on the benefits of query compilation and code generation vs. the "traditional approach" to query execution, also called volcano model, can be found in the lecture by Andy Pavlo on Query Compilation.
Runtime investigations with flame graphs
Flame graphs visualization of stack profiles provide additional insights on what part of the code are executed on CPU. The upper layers of the flame graph highlight where CPU cycles are spent. The lower layers add context by detailing the information on the parent functions/methods that called the "upper layers". The idea for this paragraph is to use stack profiles and flame graphs to further drill down on the differences in the execution model between Spark 2.0 and Spark 1.6. To collect and generate the flame graphs I have used the methods described by Kay Ousterhout in "Generating Flame Graphs for Apache Spark using Java Flight Recorder". I have used the Java flight recorder on Oracle's Java 8, starting pyspark with the following options: pyspark --conf "spark.driver.extraJavaOptions"="-XX:+UnlockCommercialFeatures -XX:+FlightRecorder" --conf "spark.executor.extraJavaOptions"="-XX:+UnlockCommercialFeatures -XX:+FlightRecorder" Here below you can find two flame graphs that visualize the stack profiles collected for Spark 1.6 and Spark 2.0 while running the test workload/query. The graphs represent samples collected over 100 seconds. The major differences you should notice between the two flame graphs are that on Spark 1.6 the execution iterates over rows of data, looping on Row Iterator to Scala for example. In the Spark 2.0 example, however, you can see in the flame graph that the methods executing the bulk of the work are built/optimized with whole-stage code generation. For example the method where most time is spent during execution is code-generated and performs operations on Hash Maps in vector form. What you can learn from the flame graphs:
- The flame graph for Spark 1.6 shows that a considerable amount of CPU cycles are spent on the Scala collection iterator. This can be linked with Spark 1.6 using the "traditional volcano model" for SQL execution. This is the part that is optimized in Spark 2.0 (see next bullet points).
- Spark 2.0 is making use of whole-stage code generation and does not use Scala collection iterator.
- Spark 2.0 is also using Vectorized Hash Maps to perform aggregations that are also code generated. The use of vectorized operations is likely introducing further performance improvements.
Spark 1.6:
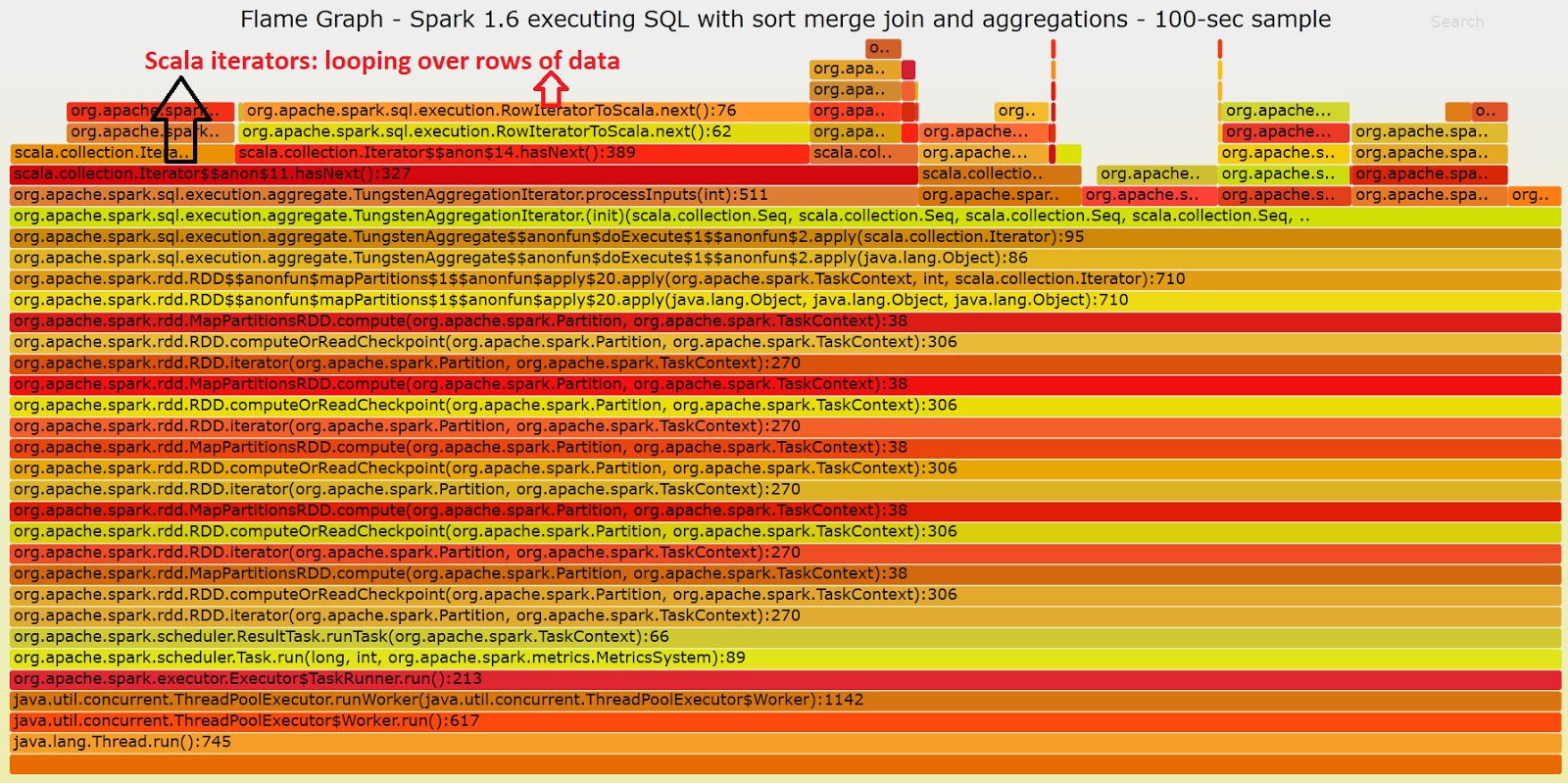
Flame graph for a sample of the execution of the test query using Spark 1.6 in local mode (on a machine with 16 cores). Note that most of the time is spent processing data on a iterative way (which is not optimal). Click on this link for a SVG version of the graph where you can drill down on the details of each step.
Spark 2.0:
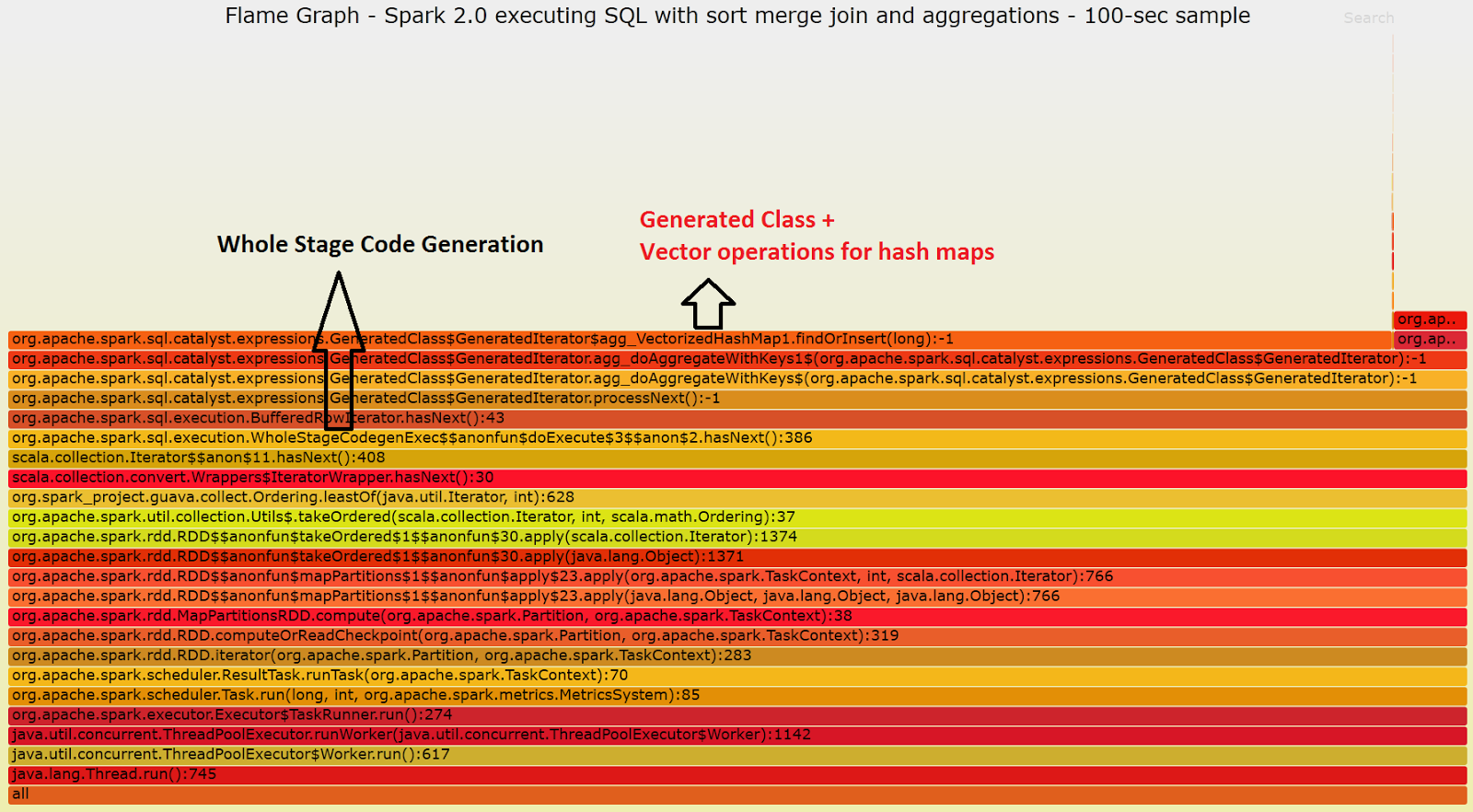
Flame graph for a sample of the execution of the test query using Spark 2.0 in local mode (on a machine with 16 cores). Note that most of the time is spent executing code that is generated dynamically via whole-stage code generation. Click on this link for a SVG version of the graph where you can drill down on the details of each step.
Note: the process of collecting stack profiles for Spark in this test is made easier by the fact that I have used Spark in local mode, which results in only one (multi-threaded) process to trace in a single box . In the general case tracing Spark is more complicated due to the distributed nature of the workload when running on a cluster for example.
Linux Perf stat counters
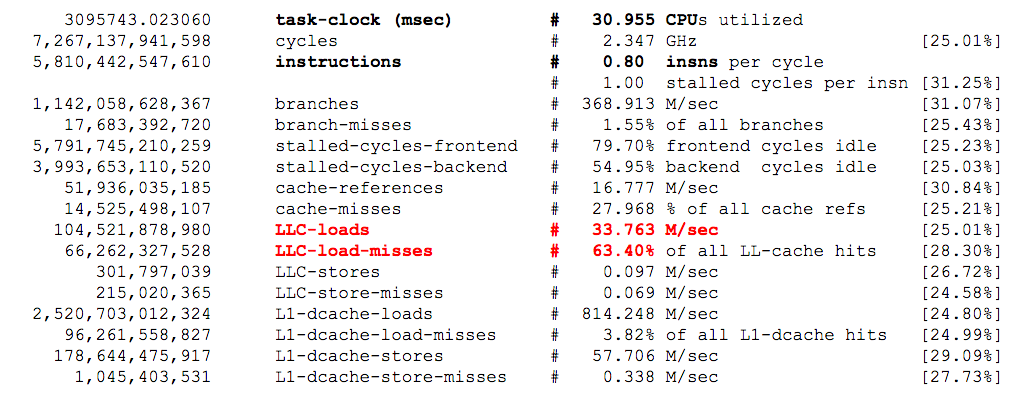
In this paragraph you can find the output of Linux Perf stat counters measured during the execution of the test query. The idea is to find differences in the run-time usage of resources that can further highlight the origin of the performance improvement that was measured in Spark 2.0 compared to Spark 1.6. The selection of stat counters to measure is taken from Tanel Poder's blog post "RAM is the new disk – and how to measure its performance – Part 2 – Tools." Notably you can find there also a short explanation of meaning of the counters.
What you can learn from comparing perf stat counters between Spark 1.6 and Spark 2.0 runs:
- In both cases the workload is CPU-bound. The machine has 16 cores and is configured with multi-threading support (i.e. 32 execution threads). Perf stat counters report an average CPU utilization of about 31 CPU threads in both cases, which confirms the fact that the workload is CPU bound.
- Reading from main memory seems to be key and Spark 2.0 appears to access memory with much higher throughput than Spark 1.6. In particular, I believe it is important to look at the metrics LLC-loads and LLC-load-misses, those count respectively how many time a cache line was requested from last level cache (LLC) and the fraction of those requests that resulted in access from main memory. Notably Spark 2.0 in the given sample reports 33 M/sec LLC-loads with ~63% of loads resulting in misses (reads from main memory) while Spark 1.6 has 0,7 M/sec LLC-loads and also ~60% misses. I have noticed that these values fluctuate over different samples, but Spark 2.0 presents always much higher access rate to LLC and memory than Spark 1.6.
- It is interesting to note that the measurements in the case of Spark 1.6 run present a higher ratio of instructions per cycle than the run with Spark 2.0. Spark 2.0 workload is stalling for memory access more frequently. A higher ratio of instructions per cycle is often an indicator of better performance, however, in this case the opposite appears to be true. I believe a possible interpretation of what is happening is that Spark 2.0 is more efficient at using CPU resources and high throughput to memory, therefore it quickly gets into what appears to be the bottleneck for this workload: stalling for memory access.
This is the output of perf stat while running the test workload with Spark 1.6:
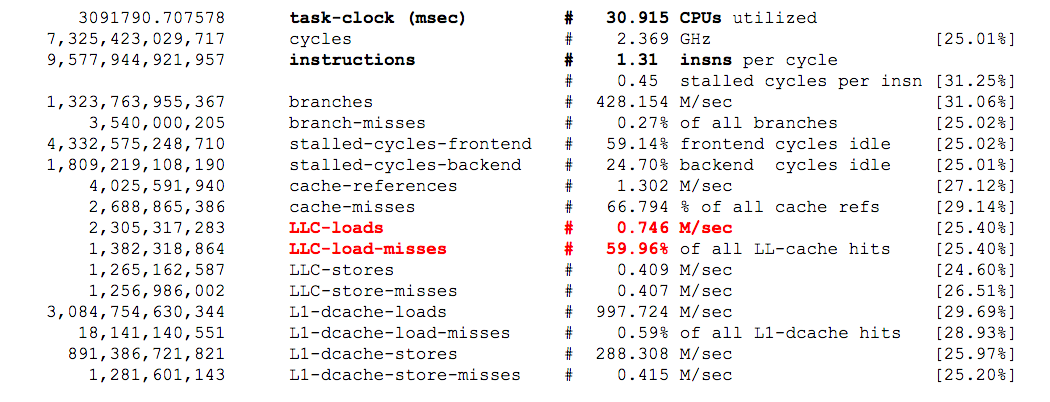
This is the output of perf stat while running the test workload with Spark 2.0:
Source code
If you want to further drill down on the changes in Spark 2.0 that benefit the performance of the test workload you can head to GitHub and browse the source code of Spark. For example from the flame graphs you can find the name of the relevant classes with path and/or you can use the search function in GitHub. So far I have only skimmed through the source code with these methods and found a few links that I believe are interesting as an example of the drill-down analysis that one can do thanks to the fact that Spark is an open source project:
- One link of interest is "org.apache.sql.execution.WholeStageCodegenExec". This is code introduced in the Spark 2.0 branch, you can find there also comments that shed some light on the mechanism used for code generation.
- Another interesting point is about the use of "vectorized hash maps" in Spark 2.0, which appears important as it is on the top line of the Spark 2.0 flame graph: "org.apache.spark.sql.executio.aggregate.VectorizedHashMapGenerator.scala" has additional details about the implementation. You can find there that this is an implementation for fast index lookup, also introduced in the Spark 2.0 branch. It is also mentioned there that the execution can be code generated for boosting its performance, that is what you can see happening in the flame graph of Spark 2.0 workload.
Tips on how to build a test environment
For the readers who are not familiar with running Spark, here some tips on how to build a test environment:
- Download Spark from Spark's website.
- You will not need to have Hadoop and/or a YARN cluster to run the tests described in this post.
- An easy way to install Python 2.7 is by downloading Anaconda.
- You can download Java 8 from Oracle technet.
- Code for generating flame graphs for Spark using Java Flight Recorder (see the recipe at this link) at: https://github.com/brendangregg/FlameGraph and https://github.com/chrishantha/jfr-flame-graph
Summary
Apache Spark 2.0 has important optimizations for performance compared to Spark version 1.6. Notably Spark optimizer and execution engine in version 2.0 can take advantage of whole-stage code generation and of vector operations to make more efficient use of CPU cycles and memory bandwidth for improved performance. This post briefly discusses an example how Spark SQL and its parallel execution engine have been useful to tune a query from a production RDBMS. Moreover an example comparing Spark 1.6 and Spark 2.0 performance has been discussed and drilled-down using execution plan details, flame graphs and Linux Perf stat counters.
Additional comments and my take-away from the tests in this post
The Hadoop ecosystem provides a powerful and easy-to-use environment for running reports and analytics queries. The point is nicely illustrated for me by the fact that we could simply take data and a query from production RDBMS and run it on the Hadoop cluster (with Spark and Impala) to make it run with parallelism and fast. This provides a simple and quick way to throw HW at a performance problem.
I am impressed by the work on Spark 2.0 optimizations for whole-stage code generation, in particular by how these new features address the important point of how to optimize CPU-bound workloads. This makes a great addition to Spark and strengthen its position as a leading player in data processing a scale.
Query compilation and/or code generation for executing SQL has become a common feature for many of the new databases appearing on the market optimized for "in memory" (i.e. processing an important fraction of their workload in main memory). This is implemented in various forms for different products, however it is proven to give significant gains in performance, typically of the order of one order of magnitude, for queries where it is applicable. The test case examined in this post provides an example of this type of optimization.
How are the mainstream RDBMS engines, that typically process result sets in an iterative way (similarly to what was found in this post with Spark 1,6 and often referred to as the volcano model) going to respond to this performance-based challenge?
Acknowledgements and references
This work has been made possible and funded by CERN IT, in particular in the context of the CERN IT Hadoop Service and Database Services. In particular I would like to thanks CERN colleagues who have contributed to the performance troubleshooting case mentioned in this post: Raul Garcia Martinez, Zbigniew Baranowski and Luca Menichetti.
- On the topic of Spark 2.0 improvements for code generation, see the blog post "Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop" and the references therein, notably including "Efficiently compiling efficient query plans for modern hardware" and JIRA ticket SPARK-12795.
- On flame graphs for Spark: Kay Ousterhout in "Generating Flame Graphs for Apache Spark using Java Flight Recorder". See also "Hadoop performance troubleshooting with stack tracing, an introduction."
- On the topic of query compilation on modern database systems vs. the volcano model, see also the lecture by Andy Pavlo on Query Compilation.
- Flame graphs are the brain child of Brendan Gregg.
- Additional links on using Linux Perf to measure performance counters: this article by Brendan Gregg and the 3-part blog posts by Tanel Poder on "RAM is the new disk".
- On the topic of connecting Hadoop and relational databases see also Tanel's presentation "Connecting Hadoop and Oracle".
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.