Databricks Voices From Spark Summit EU 2016 Day 1
by Jules Damji
Update: The videos of the presentations are now available. Find them below.
Spark Summit Keynotes
Brussels’ October morning overcast or morning-commute traffic did not faze more than 1000 Apache Spark enthusiasts to converge at the SQUARE convention center to hear keynote from the Spark creator Matei Zaharia.

Simplifying Big Data Applications with Apache Spark 2.0
Early in the year when Matei Zaharia took the stage at Spark Summit East, he shared his vision where the community was heading with Apache Spark and coined the term continuous applications, as a way for developers to write end-to-end real-time applications that reacts to real-time data. In July 2016, Apache Spark 2.0 was released.
And today in Brussels, in his keynote at Spark Summit, the biggest conference dedicated to Apache Spark, Zaharia shared how all the work that went into Spark 2.0, to unify a single interface based on DataFrames and Datasets, facilitate and simplify not only how to write continuous applications but also simplify how to write big data applications.

Zaharia said that writing big data applications is hard. For one it entails a complex combination of processing tasks, storage systems and modes such as ETL, aggregation, machine learning and streaming. Second, it’s hard to get both the productivity and performance.
Yet he outlined a number of ways in which the Spark 2.0 approach simplifies writing big data applications.
First, Spark’s unified engine allows you to express an entire workflow in a single API, connecting existing libraries and storage. Second, the high-level APIs in DataFrames and ML pipeline result in optimized code. And finally, Structured Streaming APIs enable a developer to write a multi-faceted continuous applications.

Showing what Matei alluded as continuous applications - a way to interact with both batch and streaming data - Databricks software engineer Greg Owen demonstrated how you can combine real-time streaming data aggregation with machine learning models, to garner newer insights. All this is possible because of Structured Streaming.
In his demo, using Sentiment Analysis, Greg showed how real-time tweets related to Brexit affected people's sentiments about Marmite’s rising prices.

In summation, Spark 2.0 lays the foundation for the future of unifying APIs based on DataFrames and Datasets across all Spark components for the aforementioned reasons. In the end big data developers write less code, grapple with fewer concepts, and get better performance.
Update: You can watch the full presentation here.
The Next AMPLab: Real-time Intelligent Secure Execution
Following the Matei’s keynote, Databricks co-founder and executive chairman Ion Stoica shared his vision of what’s the next phase in distributed computing.

An incubator of Apache Spark, Alluxio, and Apache Mesos, AMPLab’s reign ends this year. But it transitions into new phase of innovation: RISELab (Real-time Intelligent Secure Execution).
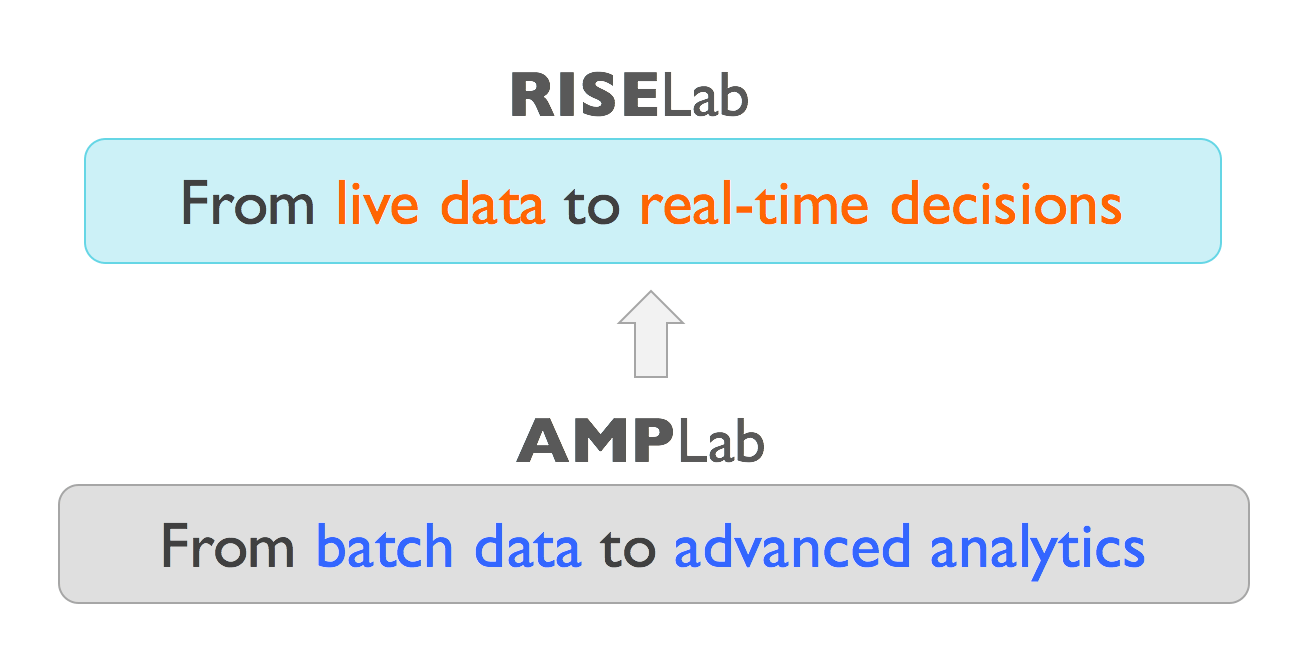
Committed to the goal of building open-source frameworks, tools, and algorithms that make building real-time applications decisions on live data with stronger security, this new phase is set to innovate and enhance Spark with two projects—Drizzle and Opaque—Stoica said.
While Drizzle reduces Apache Spark’s streaming latency by a factor of ten and bolsters fault-tolerance, Opaque enhances Spark’s data encryption at-rest or in-motion, offering stronger protection in cloud or on-premise.
Update: You can watch the full presentation here.
Developer Track Sessions
Spark’s Performance: past, present and future
Kicking off summit’s first day’s developer track, Sameer Agarwal surveyed Apache Spark’s performance—past, present and future. In their short historical exploration of Spark’s performance, the team asked a basic question: “Spark is already pretty fast, but can we make it 10x faster?” The answer, in short, led to Apache Spark 2.0 shipping with the second generation Tungsten engine, built upon ideas from modern compilers and MPP databases and applied to data processing queries (SQL / DataFrames).
Agarwal shared an insightful glimpse into Spark Internals and covered how Tungsten emits optimized bytecode at runtime that collapses the entire query into a single function, eliminating virtual function calls and leveraging CPU registers for intermediate data. He also discussed how Tungsten laid out the cached data in memory in a column oriented format for more efficient storage and higher performance.
Update: You can watch the full presentation here.

A Deep Dive into the Catalyst Optimizer
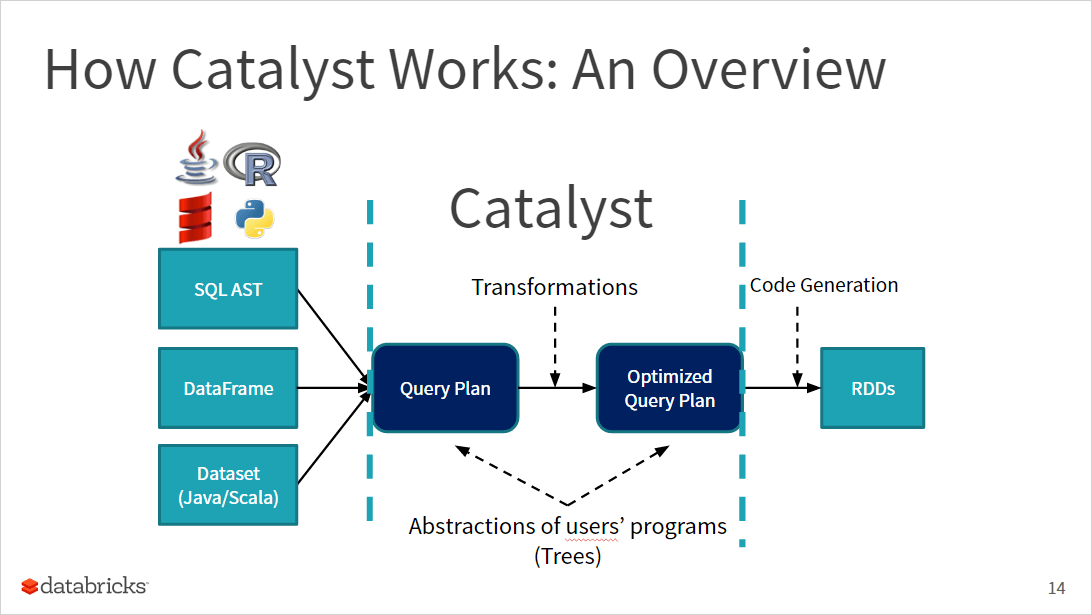
Whether you express your query or computation in SQL, DataFrame or Dataset, it undergoes the same Spark SQL engine with the Catalyst Optimizer. Through careful analysis, the Catalyst optimizer generates logical and physical plans, followed by an RDD-level byte code, optimized for optimal performance, for the JVM.
Herman van Hovell, a Spark committer and Databricks software engineer, took his audience on a deep dive on the entire pipeline and transformation that a query undergoes. He explained that the main data type in Catalyst is a tree composed of node objects or operations with zero or more children. Next he discussed how rules can be applied to manipulate the tree, and finally how rules may rearrange the nodes in the tree for optimal code generation.
Immediately following the talk, the audience got a hands-on lab session and walked away with an in-depth understanding of how Catalyst works under the hood.
Update: You can watch the full presentation here, and the hands-on lab session here.
What’s Next
A recap of the second day is available, read it in our blog. Also, shortly after the Spark Summit, all the keynotes and sessions talks and slides will available at the Spark Summit EU website.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.