Databricks Voices From Spark Summit EU 2016 Day 2
by Jules Damji and Dave Wang
Read the recap from Day 1 of Spark Summit EU.
Update: The videos of the presentations are now available. Find them below.
Spark Summit Keynotes
Although the October overcast persisted over Brussels, inside the SQUARE’s convention center attendees lined up, with coffee in one hand and pastry in the other, to hear how other organizations employ Apache Spark for their use cases.

Democratizing AI with Apache Spark
The second day kicked off with the a keynote from Databricks CEO Ali Ghodsi on the topic of artificial intelligence (AI).
Ali observed that the machine learning algorithm itself is rarely the main barrier in building AI applications. Instead, the real culprit is the set of complex systems that manages the infrastructure and prepares the data for the ML algorithms.
According to Ali, Spark is a huge leap forward in democratizing AI because of its speed, flexibility, and scalability. However, Spark cannot solve all the problems around AI by itself - and this is where Databricks comes in. Databricks’ vision is to build a platform around Spark that allows organizations to easily capitalize on Spark’s inherent speed, flexibility, and scalability for advanced analytics and beyond.
As another step towards Databricks’ goal, Ali announced the addition of GPU support and integration of popular deep learning libraries to the Databricks’ big data platform. This allows organizations to easily conduct deep learning on Spark using the popular TensorFlow framework on top of highly optimized GPU hardware.
The deep learning functionality works in concert with other components of the Databricks platform, enabling organizations to seamlessly perform data wrangling, feature extraction, interactive exploration, and model training in an end-to-end machine learning pipeline. Read the blog on GPU support to learn more, or contact us to get started.
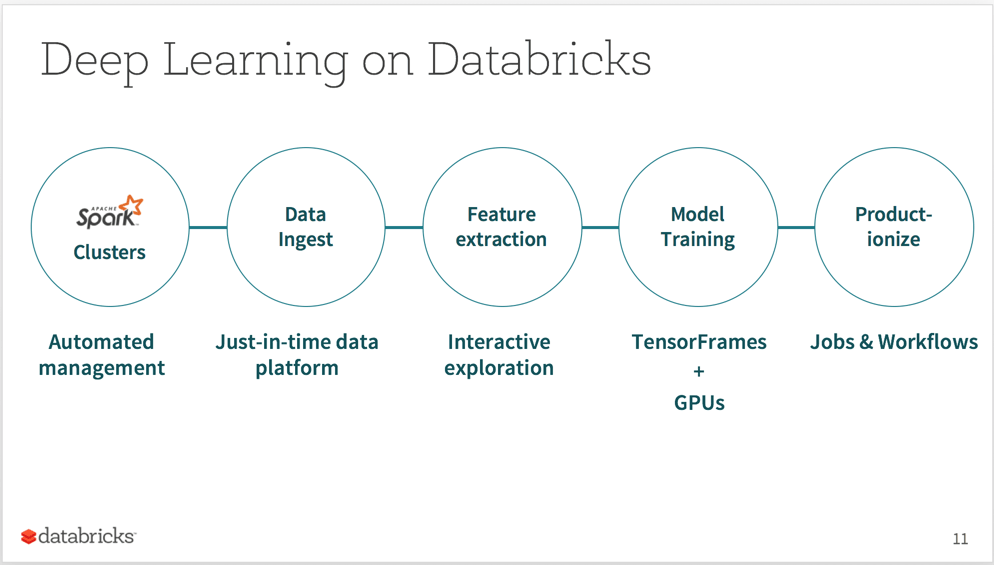
Developer Track Sessions
TensorFrames: Deep Learning with TensorFlow on Apache Spark

Databricks engineer Tim Hunter revealed more details behind Ali’s keynote with a presentation focused on deep learning on Apache Spark. He discussed how to combine Apache Spark with TensorFlow, a popular framework from Google that provides the building blocks for Machine Learning computations on GPUs. Tim demonstrated how to use GPUs with TensorFlow on Apache Spark to achieve extremely fast performance.
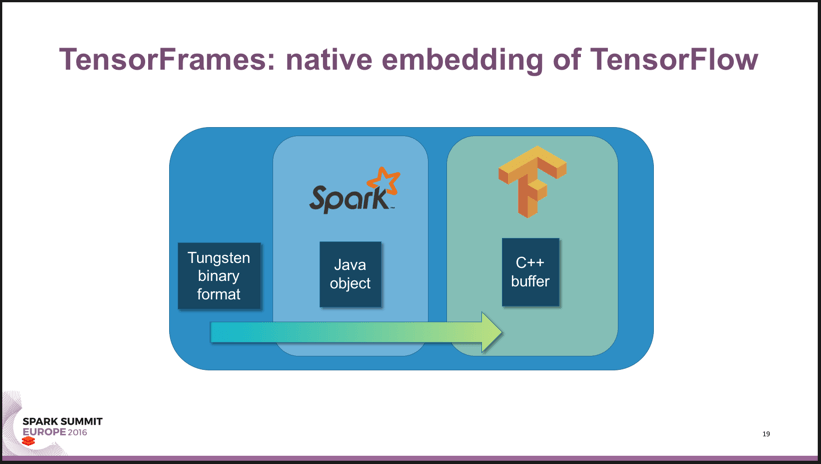
The trick, as Hunter explained, is TensorFrames. It is a library he wrote that allows Spark developers to easily pass data between Spark DataFrames and the TensorFlow runtime while taking advantage of the latest performance optimizations in Project Tungsten. The result is faster and simpler code.
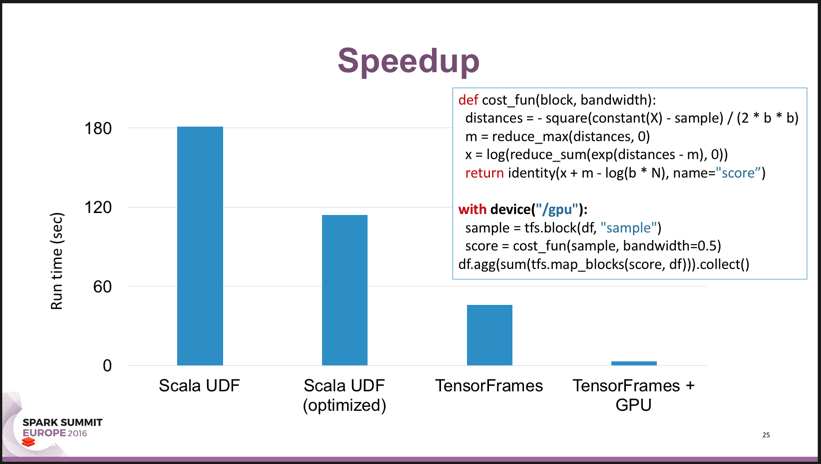
Update: You can watch the full presentation here.
Data Science Track
Online Learning with Structured Streaming
In his session talk, Databricks Product Manager Ram Sriharsha defined online machine learning as an ability to learn efficiently over a data stream on a single pass, especially when you cannot replay or revisit your data point. This ability is important for two sets of problems. First, for large scale learning in which achieving accuracy in a given time is important, machine learning algorithms might achieve that accuracy faster. And second, when data distribution changes over time, online algorithms can adapt to changing algorithms.


Implementing online Machine Learning (ML) on top Structured Streaming makes it all possible, Sriharsha said, because we can leverage its fault tolerance and interoperability with MLlib for invoking feature transformation and online algorithms within the same ML pipeline.

Update: You can watch the full presentation here.
Enterprise Track
Paddling Up the Stream
When building a real-time streaming application, how do you untangle the challenges around upgrading versions, migrating between languages and integrating with peripheral systems?

Miklos Christine, systems engineer at Databricks, today discussed the top 5 issues that he has seen customers run into and how they resolved them. In the first four issues, he showed how to fix common stacktraces seen in the wild such as type mismatches, “couldn’t find leader offsets” errors, “toDF not member of RDD” and “task not serializable.”
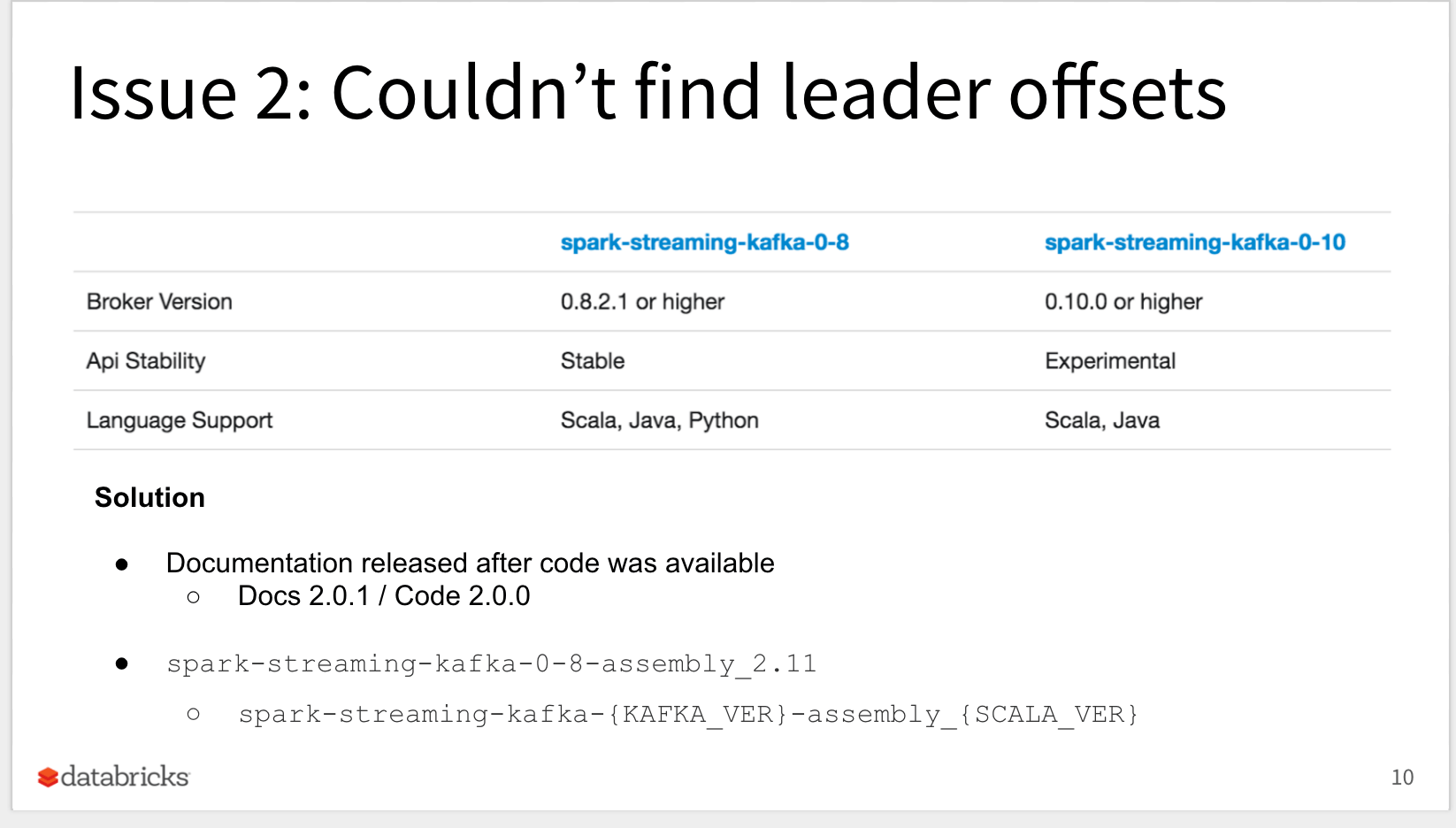
In the fifth issue, Miklos covered how to efficiently push JSON records to Kinesis or Kafka.

If you’ve been using Spark Streaming, this session was an exemplary way to learn to avoid common pitfalls that developers can run into.
Update: You can watch the full presentation here.
What’s Next
Also, presentation slides and recordings from this event will be available on the Spark Summit website by November 4th.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.