Spark Summit East 2017: Another Record-Setting Spark Summit

Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.

We’ve put together a short recap of the keynotes and highlights from Databricks’ speakers for Apache Spark enthusiasts who could not attend the summit—to enjoy the Patriots’ Super-Bowl victory euphoria that suffused the Spark Summit attendees: the snowstorm outside did not dampen the high spirits inside.
Day One: Voices of Databricks Speakers
What to Expect for Big Data and Apache Spark in 2017
Matei Zaharia led us through the journey of how Spark evolved from its early days, advancing in lockstep and taking advantage of (or overcoming shortcomings) three particular evolutionary trends in the industry: Hardware, Users, and Applications. Watch his keynote where he expounds on these three trends.
View the slides for this talk.
Insights Without Tradeoffs: Using Structured Streaming in Apache Spark
Echoing what Matei referred to as big data trends moving to production use, Michael Armbrust demonstrated how structured streaming allows developers to derive valuable insights without tradeoffs. All this is possible because, though streaming in general demands parallelism and complexity, structure streaming alleviates the burden of fault-tolerance, exactly-once semantics, data consistency, and integrity. In this talk and demo, Michael articulates Matei’s vision of continuous applications and demonstrates the ease of use of Structured Streaming APIs in a live demo.
View the slides for this talk.
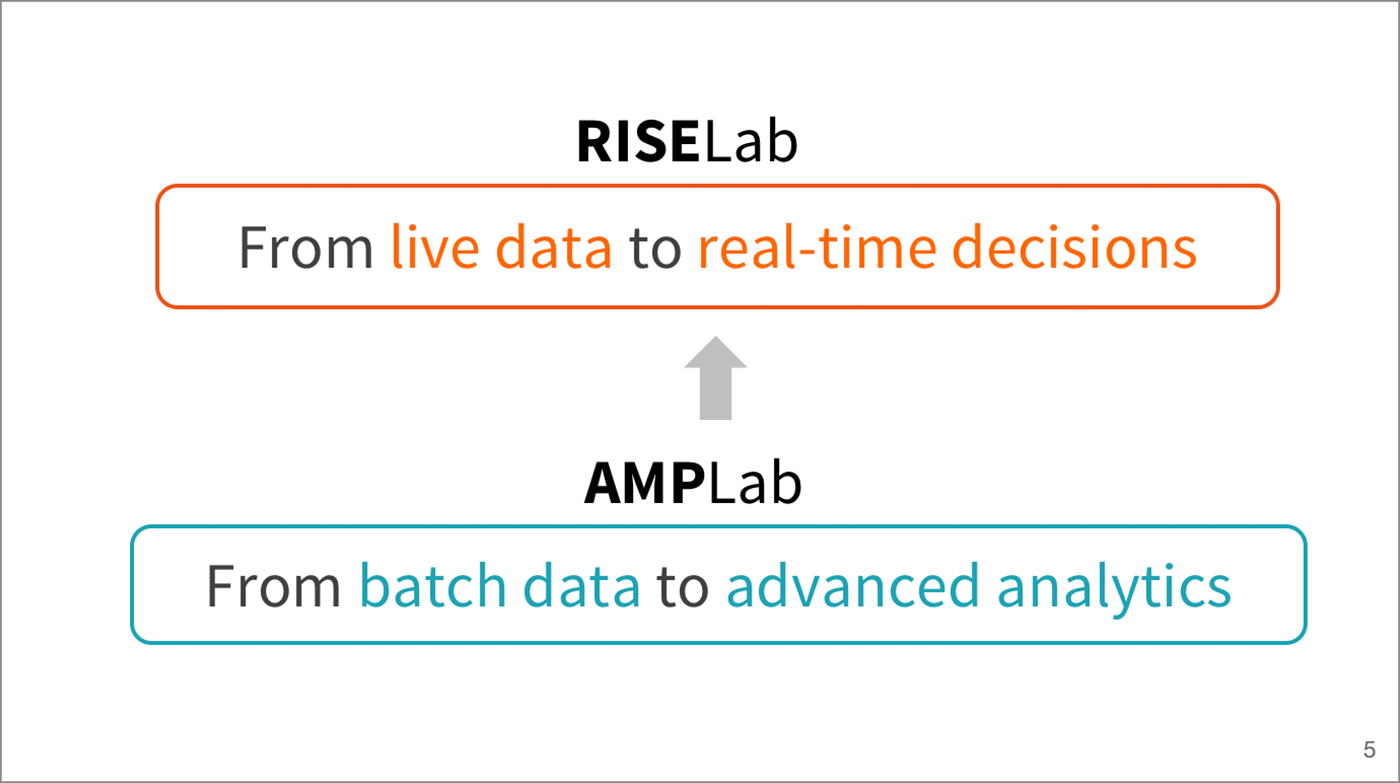
RISELab: Enabling Intelligent Real-Time Decisions
Late last year, the UC Berkeley AMPLab shut down after producing notable projects such as Apache Spark, Apache Mesos, Alluxio, BlinkDB, and others. To continue its transformative contributions to research and industry, AMPLab transitioned into a new phase of innovation: RISELab (Real-time Intelligent Secure Execution).
Today in his keynote Ion Stoica shared with the community his vision and goal of RISELab. In particular, he stressed researchers will work on AI, robotics, security, and fast distributed data systems at scale.
While AMPLab projects enabled batch data processing to advanced analytics, RISELab projects will engender and enable live data to real-time decisions, Stoica said.
Committed to the goal of building open-source frameworks, tools, and algorithms that make building real-time applications decisions on live data with stronger security, this new phase is set to innovate and enhance Spark with two projects—Drizzle and Opaque—Stoica said.
While Drizzle reduces Apache Spark’s streaming latency by a factor of ten and bolsters fault-tolerance, Opaque enhances Spark’s data encryption-at-rest or in-motion, offering stronger protection in cloud or on-premise.
Making Structured Streaming Ready for Production - Updates and Future Directions
For much of Spark’s short history, Spark streaming has continued to evolve—all to simplify writing streaming applications. Today, developers need more than just a streaming programming model to transform elements in a stream. Instead, they need a streaming model that supports end-to-end applications that continuously react to data in real-time.

Tathagata Das (TD) shared how Structured Streaming, with new features introduced in Apache Spark 2.x, allow developers to write a fault-tolerant, end-to-end streaming applications, using the unified DataFrame/Dataset APIs built atop the SparkSQL engine. Whether you doing a streaming ETL, joining real-time data from Kafka with static data, or aggregating data and updating your sinks, Structured Streaming, TD emphasized, ensures all aspects of reliability and repeatability. Looking ahead, he hinted new features, such as sessionization, support for Apache Kafka, and more windowing operations—planned for future releases.
View the slides for this talk.
Optimizing Apache Spark SQL Joins
Vida Ha takes on one of the primary sources of performance problems in Apache Spark - Spark SQL joins. She demystified how joins work in Spark, and described best practices to debug and optimize performance.
View the slides for this talk.
Women In Big Data
Several inspiring female leaders in big data came together for a luncheon and panel discussion hosted by the Women in Big Data Forum. Their goal is to strengthen diversity in the industry by helping female talent connect, engage, and grow in the field of big data and analytics. The event kicked off with a keynote presentation by Kavitha Mariappan, VP of marketing at Databricks. Kavitha spoke to the “leaky pipeline” problem facing our industry and gave actionable advice on how to make a mark as a woman in the world of big data.

Following the keynote was a panel of esteemed technology leaders including Ziya Ma, VP of Big Data at Intel, Business Unit Executive at IBM, Julie Greenway, Head of Big Data Analytics at Bose, and Gunjan Sharma, Head of Big Data Analytics at Capital One. Moderated by Donna Fernandez, COO of MetiStream, the panel debated and weighed in on why this dilemma exists and how as female leaders and role models, they need to continue to work towards a more equitable work environment.
View the slides for this talk.
Tuning and Monitoring Deep Learning on Apache Spark
The increasing rapid growth of deep learning in data analytics, cyber security, fraud detection, and database systems have huge potential for impact in research and across industries. Tim Hunter, software engineer at Databricks and contributor to the Apache Spark MLlib project and leading deep learning expert, took the stage and dove into a number of common challenges users face when integrating deep learning libraries with Spark such as needing to optimize cluster setup and data ingest, tuning the cluster, and monitoring long-running jobs. He then demonstrated various tuning techniques using the popular TensorFlow library from Google and shared best practices for building deep learning pipelines with Spark.
View the slides for this talk.

Day Two: Voices of Databricks Speakers
Virtualizing Analytics with Apache Spark
How can enterprises use more of their data to make decisions and act with more intelligence? This question kicked off the keynote on day 2. Databricks’ VP of Field Engineering, Arsalan Tavakoli-Shiraji, described how increasing diversity across the data, analytics, and end-user groups is creating a multi-faceted challenge for enterprises today.

The solution, observed Arsalan, lies not in traditional data warehouses nor Hadoop data lakes, which are artifacts from an era with much more limited problems. Rather, this new challenge requires an entirely different paradigm based on four key principles:
- Decoupled compute and storage
- Uniform data management and security model
- Unified analytics engine
- Enterprise-wide collaboration
Arsalan noted that while Spark is the perfect engine to power this new paradigm, there are many operational needs around the engine in an enterprise setting. These enterprise requirements ultimately drove Databricks to build a platform around Spark that enables them to reap the benefits of Spark faster, easier, and cheaper.
Exceptions are the Norm: Dealing with Bad Actors in ETL
Big Data is messy; data is deeply nested; and data is often “incorrect, incomplete or inconsistent,” explained Sameer Agarwal, as he opened as the first talk of the Developer track after the keynotes. He explained how the new features in Apache Spark 2.x are able to handle nested types, isolate input records for informative diagnostics, and improve the robustness of your ETLs.
He suggested techniques in how to deal and handle these “bad actors” in ETL.
View the slides for this talk.

Robust and Scalable ETL Over Cloud Storage with Spark
When it comes to data processing pains, ETL tends to be near the top of the list for most of them. As data continues to make its move into the cloud, in order to optimize for performance, it is preferable for Spark to access data directly from services such as Amazon S3, thereby decoupling storage and compute. However, there are some limitations to object stores such as S3 that can impact ETL jobs performance. Eric Liang, a Databricks software engineer, exposed these issues in great detail and provides a path forward with Databricks, which provides a highly optimized S3 access layer that gives you blazing fast read/write performance.
View the slides for this talk.

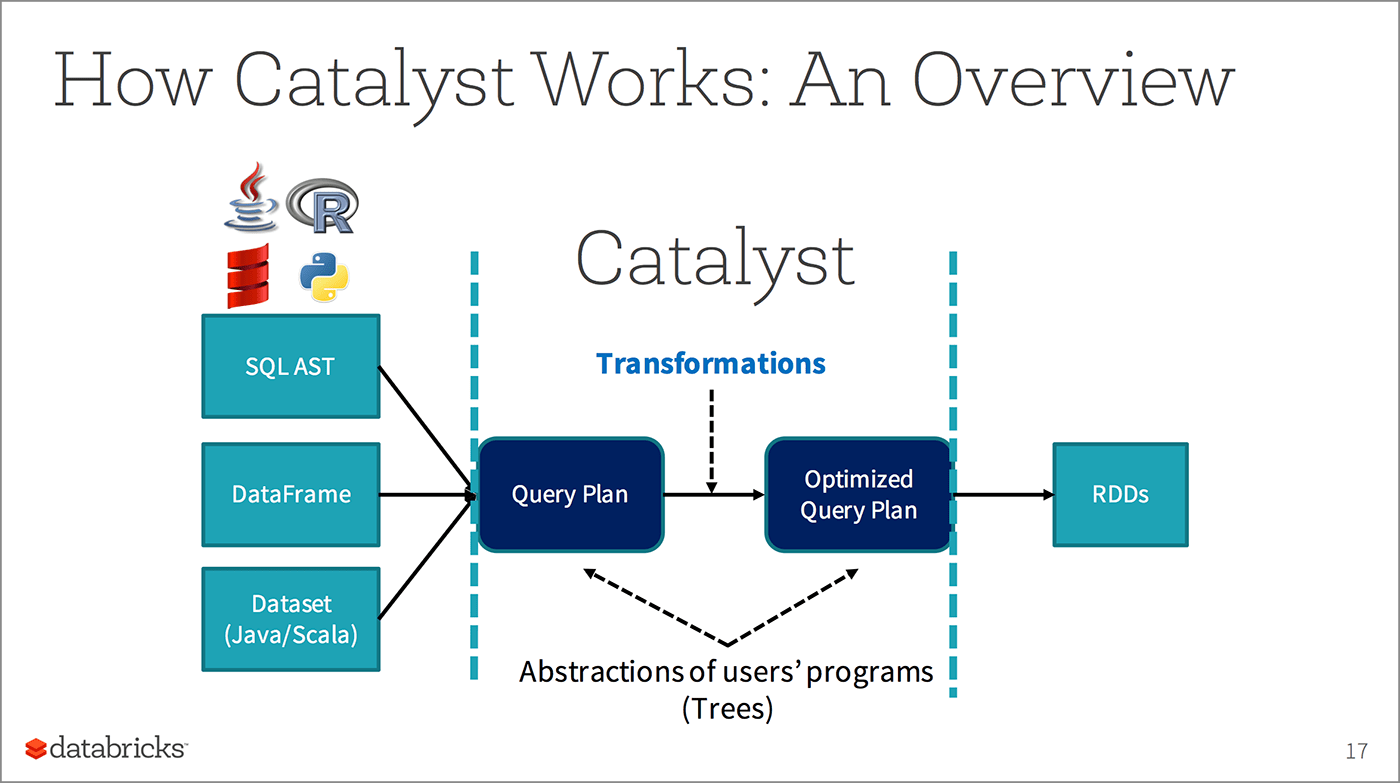
SparkSQL: A Compiler from Queries to RDDs
To a packed room—even though it was the last talk on the last day—Sameer Agrawal led us on an incisive journey and a peek under the hood, tracing a lifecycle a query (or high-level computation) undergoes with the SparkSQL engine. Using a compiler analogy, he outlined how SparkSQL parses, analyzes, optimizes, plans, and executes a user’s query—all along its phases taking advantage of the optimal benefits and techniques of the Catalyst Optimizer and Tungsten’ whole-stage code generation.
View the slides for this talk.
Parallelizing Existing R Packages with SparkR
Apache Spark 2.0 is a big step forward for SparkR. Hossein Falaki – one of the major contributors to SparkR - provided an overview of the new SparkR API. His talk described how to use this API to parallelize existing R packages, with special considerations for performance and correctness.
View the slides for this talk.

Keeping Spark on Track: Productionizing Apache Spark for ETL
Building production-quality ETL pipelines is one of the most common use cases for Apache Spark. Databricks solution engineers Kyle Pistor and Miklos Christine took the stage to share a wealth of their accumulated knowledge on how to build fast and robust ETL pipelines with Spark, based on their extensive experience working with Databricks customers.
View the slides for this talk.

What’s Next
Videos and slides of every talk will be posted on the Spark Summit website in two weeks. Follow Databricks on Twitter or subscribe to our newsletter to get notified when the new content becomes available.
In the meantime, learn Apache Spark on the Community Edition or build a production Spark application with a free trial of Databricks today!

