10th Spark Summit Sets Another Record of Attendance
by Jules Damji and Wayne Chan

We have assembled a selected collage of highlights from Databricks’ speakers at our 10th Spark Summit, a milestone for Apache Spark community and users. Shortly, the coverage of all sessions and slides will be available on the Spark Summit 2017 website.
Day One: Developer Day
Expanding Apache Spark Use Cases in 2.2 and Beyond
Apache Spark has come a long way, and it is tackling new frontiers through innovations to embrace new workloads. In his keynote, the creator of Apache Spark Matei Zaharia shares the rate of Spark’s adoption in the community; Spark’s philosophy and some notable use cases; and reveals two new open source projects from Databricks to handle new workloads: deep learning and structured streaming general availability and performance.
Software engineer Tim Hunter demonstrates how to use deep learning pipelines on the Databricks, and Michael Armbrust, team lead in the streaming team, shows Structured Streaming’s performance and continuous processing on Databricks’ in a live demo.
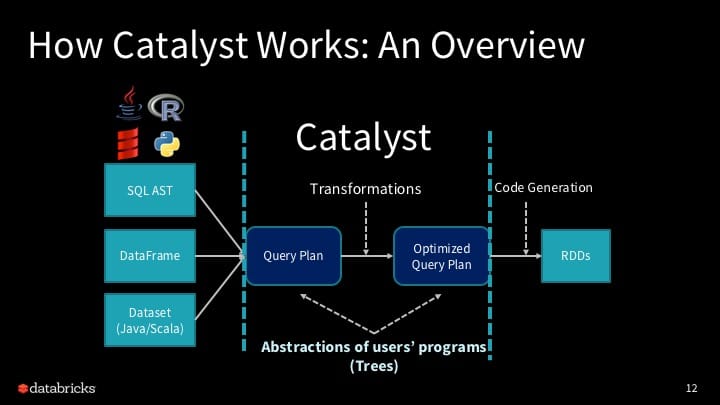
A Deep Dive into Spark SQL's Catalyst Optimizer
Kicking off the Developer track on the first day, Yin Huai takes us into the internals of how SQL optimizes your query—whether written in SQL, Dataframe or Dataset—the outcome is the same: optimized code for execution. But what facilitates this optimizations are Structured APIs, which signal the optimizer what needs to be accomplished not how. As a result, the Catalyst optimizer can rearrange higher-level operations such as project, aggregate, join or filter for optimal execution.
Challenging Web-Scale Graph Analytics with Apache Spark
Xiangrui Meng informs us that the rise of social networks and internet of things demand complex web-scale graphs with billions of vertices and edges. One way to address this problem, Meng said, is to use GraphFrames, which implements graph queries and pattern matching to enable and simplify Spark SQL like queries for graph analytics.

Apache Spark MLlib's Past Trajectory and New Directions
Joseph Bradley frames his talk in three basic questions: What? So What? And Now What?.
By giving us a trajectory of Spark’s MLlib evolution, he touches on some key milestones why MLlib has become a popular framework among machine learning practitioners. Through its continued growth and expanding community of contributors, MLlib’s major projects have covered most of the popular use cases’ algorithms.

How to Productionize Your Machine Learning Models Using Apache Spark MLlib 2.x
Data scientists like to understand and explore data by transforming massive datasets and by building large-scale machine learning models with Apache Spark, a popular tool. But deploying them in production can prove challenging. Richard Garris shows how you can deploy this models by examining some actual case studies.
Cost-Based Optimizer in Apache Spark 2.2
In this deep-dive technical track Messrs Sameer Agarwal and Wenchen Fan (Databricks) and Ron Hu and Zhenhua Wang (Huawei) explore details in how Apache Spark 2.2 Cost-based Optimizer works and how statistical collections schemes are used to formulate an execution plan to generate compact code for execution.

Real-Time Machine Learning Analytics Using Structured Streaming and Kinesis Firehose
One of the most popular Apache Spark use cases is to build real-time advanced analytics applications. Databricks Solutions Architects Caryl Yuhas and Myles Baker walk through how to build a sample application and share valuable tips and tricks learned from working with many applications during the entirety of the talk.
Easy, Scalable, Fault-Tolerant Stream Processing with Structured Streaming in Apache Spark
In this follow up deep-dive session to Matei Zaharia’s keynote and Michael Armbrust’s demo on the performance of structured streaming, Michael Armbrust and Tathagata Das expound on all aspects of Structured Streaming in its intimate technical details, in particular how complex data, complex workloads, and complex systems can be used for its sinks and sources in a transaction-oriented manner.
In short, with structured streaming you as developer should not worry about underlying streaming complexities. Instead, you as developer should focus on writing simple queries and let Spark continuously update the answer.

Building Robust ETL Pipelines with Apache Spark
While stable and robust ETL pipelines are critical components in any enterprise data processing, equally important are their reliability and resiliency. Xiao Li offers best and safe practices to attain both. By using features in Spark 2.2 (and future Spark 2.3), he shares a few tips and tricks: how to deal with dirty or bad records; how to handle multi-line JSON/CSV support, and to you use high-order functions in SQL.

Day Two: Enterprise Day
Accelerating Innovation with Unified Analytics Platform
CEO and Co-Founder of Databricks Ali Ghodsi kicks off day two with his keynote. He tells how the continued growth of Apache Spark has resulted into a myriad of innovative uses cases, from churn analytics to genome sequencing. As result, these applications are difficult to develop as they often involve siloed teams of different domain experts; their complex workflows take too long from data access to insight; and the infrastructure is costly and difficult to manage.
To address these problems, Ali explains the three pillars of Databricks’ Unified Analytics Platform: people, process and platforms (or systems).
He then shares three customer stories from HP, and Shell that highlight how the Databricks Unified Analytics Platform addresses these challenges to help enterprises accelerate innovation by unifying data science, engineering, and business.
To close out his keynote, Ali announces Databricks Serverless that eliminates the complexity of infrastructure by allowing large groups of users to run workloads on a single, automatically managed pool of resources — and increase the deployment speed of Spark by up to 10x at a lower cost.
Software engineer Greg Owen demonstrates Databricks Serverless capabilities such as fine-grained security, performance benefits, and auto-scaling. Greg shows how resources are automatically managed to ensure that all users are isolated and not impacted by others while they share the serverless pool.
Machine Learning Innovation Fireside Chat
Ben Lorica sits down with Ion Stoica (co-founder and Executive Chairman of Databricks; co-founder of UC Berkeley RISELab) and Matei Zaharia (co-founder and Chief Technologist of Databricks; assistant professor at Stanford CS).

Machine Learning in the Apache Spark ecosystem is advancing at a rapid pace. New projects are emerging to help take it to the next level. Ion Stoica and Matei Zaharia discuss how their two respective new initiatives from RISELab and DAWN are solving and approaching new demands of real-time intelligent decision making.
Watch the full recording of the panel here
Transactional I/O on Cloud Storage in Databricks
Eric Liang, a software engineer at Databricks, discusses the three dimensions to evaluate HDFS to S3: cost, SLAs (availability and durability), and performance. He then provides a deep dive on the challenges in writing to Cloud storage with Apache Spark and shares transactional commit benchmarks on Databricks I/O (DBIO) compared to Hadoop.
From Pipelines to Refineries: Building Complex Data Applications with Apache Spark
Apache Spark provides strong building blocks for batch processes, streams and ad-hoc interactive analysis. However, users face challenges when putting together a single coherent pipeline that could involve hundreds of transformation steps, especially when confronted by the need of rapid iterations. Databricks software engineer Tim Hunter explores these issues through the lens of functional programming.
Identify Disease-Associated Genetic Variants Via 3D Genomics Structure and Regulatory Landscapes Using Deep Learning Frameworks
Data analytics is exploding in the life sciences industry, particularly in the field of genomics where biotechnology firms are trying to glean insights from genomic data to accelerate drug innovation. This fascinating talk featuring Dr. Yi-Hsiang Hsu, Director of the GeriOMICS Center at the Beth Israel Deaconess Medical Center, and YongSheng Huang, a resident solutions architect at Databricks, demonstrated how Apache Spark can be used to apply deep learning to predict functions of disease-associated variants to impact development of new drug intervention.
Apache SparkR Under the Hood: How to Debug your SparkR Applications
On the final day of the data science track, Hossein Falaki a software engineer and data scientist at Databricks, dives deep into the inner-workings of SparkR, its architecture, performance issues, and more. He then walked through real SparkR use cases to show how common errors can be eliminated based on his experience.
Voices from the Apache Spark Ecosystem
Using AI For Providing Insights and Recommendations on Activity Data
In front of a packed room, Alexis Roos and Sammy Nammari from Salesforce share how Databricks and Apache Spark power Einstein, an artificial intelligence capability built into the Salesforce platform. In a live demo within Databricks, they show how they combine activity data with contextual and CRM data to provide real-time insights and recommendations to their customers.
Applying Machine Learning to Construction
Autodesk is a leader in architecture, engineering and construction software. They developed a set of cloud products for construction that enables almost anytime, anywhere access to project-related data throughout the building construction lifecycle. Charis Kaskiris and Subham Goel discuss how Databricks and Apache Spark have allowed their data science team to work more efficiently by unifying data management, machine learning, and insight generation to empower intelligent construction.
Herding Cats: Migrating Dozens of Oddball Analytics Systems to Apache Spark
Trying to manage and derive insights from multitudes of large sets of data distributed across various data sources and legacy systems is a common challenge many companies face. John Cavanaugh, master architect and strategist at HP, speaks of their experience finding, cataloging, and eventually eliminating these siloed systems by migrating everything to Databricks — allowing them to fully leverage the power of Apache Spark and Databricks to analyze the data.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.