Analysing Metro Operations Using Apache Spark on Databricks
by Even Vinge, Senior Manager - EY Advisory, Data & Analytics
This is a guest blog from EY Advisory Data & Analytics team, who have been working with Sporveien in Oslo building a platform for metro analytics using Apache Spark on Databricks.
Sporveien is the operator of the Oslo Metro, a municipally owned Metro network supplying the greater Oslo area with public transportation since 1898. Today, the Metro transports more than 200,000 passengers on a daily basis and is a critical part of the city's infrastructure.
Sporveien is an integrated operator, meaning they are responsible for all aspects of keeping the service running. Metro operations, train maintenance, infrastructure maintenance and even construction of new infrastructure falls under Sporveien’s domain. As a result, the company employs a large workforce of experienced metro drivers, operators, mechanics and engineers to ensure smooth operation of the metro.
Over the next few years, with a growing population and political shifts towards green transportation, the Metro will need to be able transport even more people than today. Sporveien’s stated goal for the coming years is to enable this expansion while keeping costs down and, just as importantly, punctuality high.
Punctuality — the percentage of Metro departures delivered on time — is a key metric being closely monitored by Sporveien, as any deviation in punctuality can cause big problems for Sporveien’s end customers — the citizens of Oslo. The Metro is a closed loop system running on a tight schedule, and even small deviations from the schedule can become amplified throughout the network and end up causing large delays.
The Metro is being monitored continuously by a signalling system following every movement of every train, logging around 170,000 train movements and 3 million signal readings every day. Due to the volume and complexity of the signalling data, Sporveien was, until recently, not able to fully utilize this information source to get a deeper understanding of how the different aspects of Metro operations affect overall performance.
When we started looking at this data and the hypotheses we wanted to investigate, we realized this was a great case for Apache Spark. The combination of high data volumes with a need for near real time processing, as well as the need for extensive data cleaning and transformation to be able to extract value all pointed to the conclusion that a modern data analysis platform would be necessary. Wanting to start performing analyses and operationalizing them quickly without getting bogged down in the complexities of setting up and administering a Spark cluster, we decided to use Databricks for both analysis and production deployment. Sporveien had already chosen AWS as their preferred cloud stack, so that Databricks was tightly integrated was an added advantage.
Our Data Pipeline: S3, Spark, Redshift and Tableau
In order to get insights from the signaling data, it is extracted from the source system and pushed to a Kinesis queue, before being loaded to S3 using a simple AWS Lambda function. Then the Spark processing sets off. First the data is cleaned and transformed to calculate precise timings of the actual metro departures. It is then combined with detailed scheduling data from the planning system using a multi-step matching routine which ensures that any single actual departure is only matched with a single planned departure. The departure data is then further enriched with passenger flow data fetched from the automated passenger counting system installed in each train. Finally, the enriched and cleaned data is dumped to our data warehouse in Redshift.
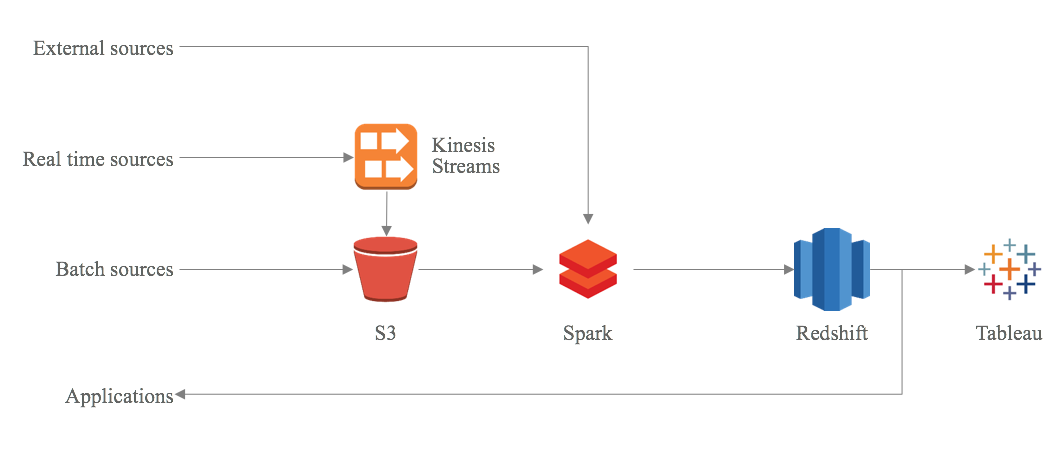
This whole process runs every five minutes throughout the day on real time data, using heuristics for some of the more complex calculations. To ensure precise results over time, the whole day’s data is recalculated during the night using more detailed calculations. We like to think of this as our version of lambda architecture, where we are able to use the same stack and the same logic for both real time and batch processing.
Our data pipelines and our Redshift cluster have a myriad of uses within Sporveien, including operational analysis of operations performance and deviations, KPI reporting, real time dashboards, and recently also feeding analyzed sensor data back into production systems to enable condition based maintenance of some of Sporveien’s railway infrastructure.
The signalling data is one of several data pipelines we have running in production. At the time of writing this, we have around 40 Databricks notebooks running nightly or continuously, coordinated using Databricks Notebook Workflows and scheduled in parallel using the Jobs feature. We have also set up an integration to Sporveien’s Slack instance to make sure that everyone on the analytics team is aware of what’s happening with our production jobs.
In all this, the Spark framework has proven to be an immensely powerful tool kit. An obvious advantage is being able to spread computing over several nodes —- for instance we run our real-time jobs on a small cluster, and then launch a bigger one for recalculations at night. But equally important, we’ve found that PySpark SQL is a surprisingly succinct and communicative way of expressing data transformation logic. We get to write transformation logic that is understandable and auditable even to non-analysts, something that increases the trust in the results greatly.
The Challenge: How to do Continuous Integration on Databricks
As we’re continuously extending our analyses and refining our algorithms, we’ve found ourselves needing to deploy updated transformation logic to our development and production repositories quite often.
We use Databricks for all aspects of writing and running Spark code, and were early adopters of the GitHub integration as we have the rest of our codebase in GitHub as well. However, we found the built in Github integration to be too simplistic to work for our needs. Since we are using Databricks Notebook Workflows, we have many dependencies between different notebooks, and as such we wanted to be able to perform commits across notebooks, being in control of all changes and what to deploy when. We also found it cumbersome trying to do larger deployments to production.
We have been working with Github Flow as our deployment workflow in previous projects, using branches for feature development and pull requests for both code reviews and automated deployments, and felt this could work well in this setting as well — if we only had the necessary CI setup in place. With this motivation, we spoke to Databricks to see what could be done, and agreed that an API for accessing the workspace would make a lot of what we wanted possible. A few months later we were very happy to be invited to try out the new Workspace API, and quickly confirmed that this was what we needed to be able to get a complete code versioning and CI setup going.
Bricker
The Workspace API makes it easy to list, download, upload and delete notebooks in Databricks. If we could get this working together, we would be able to sync a whole folder structure between our local machines and Databricks. And, of course, as soon as we had the notebooks locally, we would have all our usual Git tools at our disposal, making it simple to stage, diff, commit, etc.
So to make this work, we built a small Python CLI tool we’ve called bricker. Bricker allows us to sync a local folder structure to Databricks just by entering the command bricker up, and similarly to sync from Databricks to the local filesystem using bricker down. Bricker uses your current checked out Git branch name to determine the matching folder name in Databricks.
We have also added a feature to create a preconfigured cluster with the right IAM roles, Spark configs etc. using bricker create_cluster to save some time as we found ourselves often creating the same types of clusters.
We thought more people might be needing something similar, so we’ve open sourced the tool and published it on PyPI. You can find install instructions here.
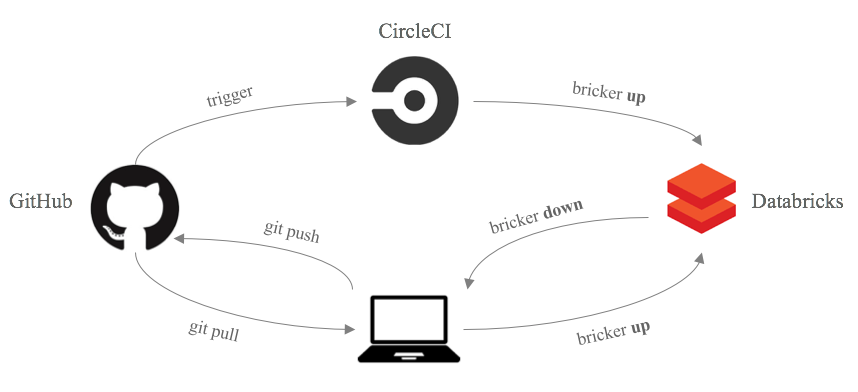
Our Analysis Development Lifecycle: GitHub, Bricker, CircleCL and Databricks
Using bricker, our analysis lifecycle now works like this: We start a new feature by branching from the dev branch on our laptops, and bricker up to get a new cloned folder in Databricks where we develop and test new and updated analyses. When we’re ready to merge, we use bricker down and commit to our feature branch, before pushing to Github and creating a pull request.
We’ve set up the cloud CI solution Circle CI to trigger on pull request merges, and so as soon as the pull request is merged into dev or production, CI fetches the merged code and runs bricker up to automatically deploy the merge to our Databricks production folder. With this, we’ve been able to reduce our entire production deployment into a one click approval in Github, allowing the entire team to iterate on analyses quickly and safely without worrying about broken dependencies, and to deploy into production as often as we need.
Impact
Using this setup, we have been able to very rapidly establish a robust and full featured analytics solution in Sporveien. We have spent less time thinking about infrastructure and more about creating analyses and data products to help Sporveien better understand how different aspects of the Metro operations affect punctuality.
In the last few years, Sporveien has really embraced data-driven decision making. We are using detailed analyses and visualizations of different aspects of performance in every setting from strategic planning to operational standups in the garages and with operations teams.
Looking forward, there is still a lot of exciting work to be done at Sporveien. We have only seen the beginning of what insights can be had by understanding and analysing the ever growing amounts of data generated by all kinds of operational systems. As we get more sensors and higher resolution measurements, we are now looking at applying machine learning to predict when railway infrastructure components will break down.
By continuously optimizing operations and improving performance, Sporveien is doing everything to be able to offer the citizens of Oslo a reliable and punctual service both today and in the many years to come.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.