Managing and Securing Credentials in Databricks for Apache Spark Jobs
by Jason Pohl
Since Apache Spark separates compute from storage, every Spark Job requires a set of credentials to connect to disparate data sources. Storing those credentials in the clear can be a security risk if not stringently administered. To mitigate that risk, Databricks makes it easy and secure to connect to S3 with either Access Keys via DBFS or by using IAM Roles. For all other data sources (Kafka, Cassandra, RDBMS, etc.), the sensitive credentials must be managed by some other means.
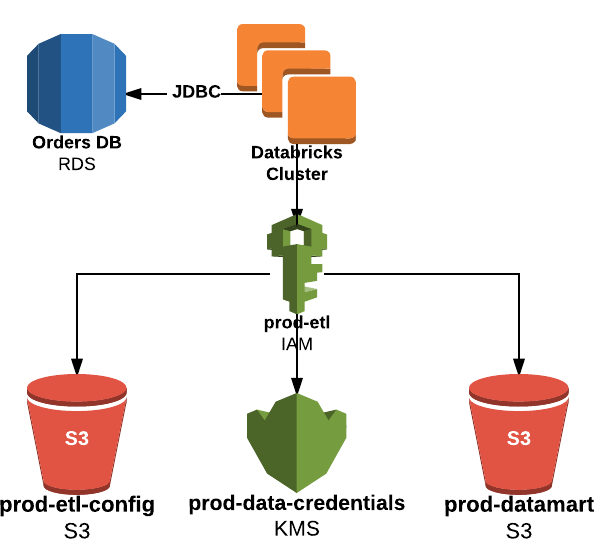
This blog post will describe how to leverage an IAM Role to map to any set of credentials. It will leverage the AWS’s Key Management Service (KMS) to encrypt and decrypt the credentials so that your credentials are never in the clear at rest or in flight. When a Databricks Cluster is created using the IAM Role, it will have privileges to both read the encrypted credentials from an S3 bucket and decrypt the ciphertext with a KMS key.
In this example, an ETL Job will read data from a relational database using JDBC and write to an S3 bucket. It uses an IAM Role, prod-etl, that is allowed to read configuration for production ETL jobs from the S3 bucket prod-etl-config, to decrypt the ciphertext using the prod-data-credentials KMS key, and to write data to the prod-datamart S3 bucket. Similarly, there can be equivalent buckets, roles, and keys for Dev and Test environments. Databricks allows you to restrict which users are allowed to use which IAM Roles.
Job Configuration File
The configuration for this ETL Job resides in an S3 bucket and resembles the following:
Every part of the configuration is in clear text except for the password which is represented as encrypted ciphertext. When the ETL Job is run, it accepts a path for the configuration file as an input:
s3a://prod-etl-config/StageOrdersDataMart.json
If this configuration were meant to connect to Test data sources, a config file corresponding to the Test environment would be referenced instead.
ETL Notebook
The notebook for the ETL Job does the following:
- Receives Job Parameters (config file & job name)
- Downloads Config File
- Checks that the Config is valid
- Parses the file into a JobConfig object
- Uses that JobConfig object to decrypt and apply credentials to both the DataFrameReader and DataFrameWriter
Ciphertext Decryption
The actual decryption occurs within the Connection class in a private method. The API accepts either a DataFrameReader or DataFrameWriter object and applies the decrypted values as options to them. At no point are the decrypted values printed or logged. This class could be built into its own library from a source code repository that is restricted so that only a small number of developers are allowed to modify it. This notebook shows the Connection code.
This code was inspired by the AWS Encryption SDK for Java Example Code. You may want to experiment with the encryption context to suit your particular use case. In order for the Encryption SDK to work, you need to create and attach the following libraries from maven.
Encryption
The AWS Encryption SDK must be used to encrypt the clear text password before it can be included in the configuration file. A method to do so has been included as part of the Connection class. This can be done within a Databricks notebook. After the config file has been created and written to S3, the notebook to create
it can be deleted.
AWS Setup
- Create an IAM Role, prod-etl
- Add policies to IAM Role to List, Get, Put, Delete to the following S3 buckets:
* Parquet Datamart Bucket: prod-datamart
* ETL Configuration Bucket: prod-etl-config
3. Register IAM Role with Databricks
4. Create a Customer Master Key (CMK) via the AWS Console
* Be sure to select the correct region BEFORE clicking “Create Key”
* Add the prod-etl IAM Role as a Key User
* Record the ARN of the CMK as you will need it to encrypt your credentials
Conclusion
This blog post illustrated how you can leverage an IAM Role and a KMS Key to encrypt sensitive credentials at rest and decrypt them in memory. This provides a way to leverage the access controls in Databricks that restricts which users can create clusters with which IAM roles. This prevents sensitive credentials from being left in the clear within either notebooks or a repository of source code. Finally, this scheme provides a way to have a clear separation between Dev, Test, and Production environment configurations.
Try these three notebooks on your Databricks. If you don’t have a Databricks account, get one today.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.