Apache Spark’s Structured Streaming with Amazon Kinesis on Databricks
by Jules Damji
On July 11, 2017, we announced the general availability of Apache Spark 2.2.0 as part of Databricks Runtime 3.0 (DBR) for the Unified Analytics Platform. To augment the scope of Structured Streaming on DBR, we support AWS Kinesis Connector as a source (to read streams from), giving developers the freedom to do three things.
First, you can choose either Apache Kafka or Amazon’s Kinesis as a source to read streaming data. Second, you are not shackled to Kinesis Analytics for doing analytics but can use Spark SQL and Structured APIs. And finally, you can use Apache Spark on the Unified Databricks Platform, along with other workloads, to write your end-to-end continuous applications.
In this blog, we’ll discuss four aspects of the Kinesis connector for Structured Streaming so that you can get started quickly on Databricks, and with minimal changes, you can switch to other streaming sources and sinks of your choice.
- Kinesis Data Schema
- Configuration Parameters
- Authentication with AWS Kinesis
- Anatomy of a Kinesis Structured Streaming Application
Kinesis Data Schema
Knowing what Kinesis records you’ve read from a stream and understanding how those records map to a defined schema make developers’ lives easier. Even better if a Kinesis record maps to Apache Spark’s DataFrames, with named columns and their associated types. Then you can select the desired payload from the Kinesis record, by accessing the column from the resulting DataFrame and employ DataFrame APIs operations.
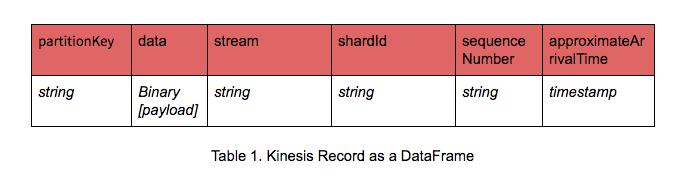
Let’s assume you send JSON blobs to Kinesis as your records. To access the binary data payload, which is your JSON encoded data, you can use the DataFrame API method as cast(data as STRING) as JsonData to deserialize your binary payload data into a JSON string. Furthermore, once converted to a JSON string, you can then use from_json() SQL utility functions to explode into respective DataFrame columns.
Hence, knowing the Kinesis schema and how it maps to a DataFrame makes things easier to do streaming ETL, whether your data is simple, such as words, or structured and complex, such as nested JSON.
Kinesis Configuration
Just as important as understanding Kinesis record and its schema is knowing the right configuration parameters and options to supply in your Kinesis connector code. While options are many, few import ones are worthy of note:
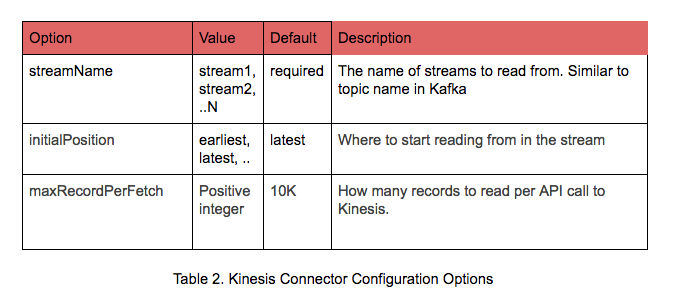
For detailed options read Kinesis configuration documentation.
Now that we know the format of our DataFrame derived from the Kinesis record and understand what options we can supply to Kinesis connector to read a stream, we can write our code, as shown below in the anatomy of a Kinesis streaming application. But first, we must pass through AWS security gatekeepers for authentication.
Authentication with AWS Kinesis
By default, the Kinesis connector resorts to Amazon’s default credential provider chain, so if you have created an IAM role for your Databricks cluster that includes access to Kinesis then access will be automatically granted. Additionally, depending on your IAM role access, the same default credentials will grant you access to AWS S3 buckets for writing.
Alternatively, you can explicitly supply credentials as part of the “options” to the Kinesis connector. When supplying explicit secret keys, use two “option” parameters: awsAccessKey and awsSecretKey. However, we recommend using AWS IAM Roles instead of providing keys in production.
Anatomy of a Kinesis Structured Streaming Application
So far we introduced three concepts that enable us to write our Structured Streaming application using the Kinesis connector. A Structured Streaming application has a distinct anatomy, serial steps, regardless of your streaming sources or sinks. Let’s study each step.
Step 1: Defining your data’s schema
Although the Kinesis connector can read any encoded data—including JSON, Avro, bytes—as long as you can decode it in your receiving Spark code, for this blog we will assume that our Kinesis stream is fed with device data encoded as a JSON string, with the following schemas.
[code_tabs]
[/code_tabs]
Step 2: Reading from your source
One you have defined your schema, the next step is to read your stream, using Kinesis connector. By only specifying your source format, namely “kinesis,” Databricks will automatically use the Kinesis connector for reading. It will handle all aspects of what shard to read from and keep track of all the metadata. You need not worry about it.
Something to note here is that if my source were other than “kinesis,” I would simply change this to indicate “kafka” or “socket,” and drop the AWS credentials.
[code_tabs]
[/code_tabs]
Step 3: Exploring or Transforming streams
Once we have our data loaded and the Kinesis records now have been mapped to DataFrames, we can use the SQL and DataFrames/Datasets API to process. And the underlying streaming engines will ensure exactly-once semantics and fault-tolerance. To learn more about how Spark Streaming achieves this vital functionality in Structured Streaming, view our deep dive Spark Summit session.
[code_tabs]
[/code_tabs]
This step is where most of your analytics is done and where your actionable insights are derived from. By using Spark’s Structured APIs in this step, you get all the merits of Spark SQL performance and compact-code generation from Tungsten, without using another SQL engine or programming in a separate SDK to conduct your ETL or streaming analytics.
Step 4: Saving your transformed stream
Finally, you can optionally write your transformed stream to a parquet file at the specified location in your S3 bucket, partitioned by “date” or “timestamp.” To inform Spark to ensure fault-tolerance, you can specify an option parameter “checkpointLocation,” and the underlying engine will maintain the state.
[code_tabs]
[/code_tabs]
These four basic steps encapsulate an anatomy of a typical Structured Streaming application. Whether your source is Kinesis or Kafka or socket or a local filesystem, you can follow these guidelines and structure your Structured Streaming computation.
What if you want to write your transformed stream to, for instance, your own sink, such as Kinesis or NoSQL, presently not supported by Spark’s Structured Streaming. You can write your own sink functionality by implementing the ForeachSinkinterface to write data to Kinesis.
What’s Next
Instead of cluttering this blog with a complete code example showing a Kinesis connector streaming application, I’ll refer you to examine and explore the code to do the quintessential “Hello World” of distributed computing WordCount on Kinesis. Even better, you can import this WordCount notebook and supply your AWS credentials—and get on with it.
There’s no need for you to install or attach any Kinesis library. No need to access an external Kinesis SDK. You simply write your Structured Streaming on Databricks Runtime 3.0. We will do the rest.
If you don’t have an account on Databricks, get one today.
Read More
We have a series of Structured Streaming blogs that expound on many of its features,
and you can consult our Kinesis Connector documentation along with
Structured Streaming Programming guide for some immersive reading.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.