Anthology of Technical Assets on Apache Spark's Structured Streaming
by Jules Damji
Older anthologies collated a collection of contributions from various authors around a theme—bounded then as a journal or periodical. Newer anthologies, however, include multiple modals of expressions—digitized now as an ebook or a blog. Both offer an exposition of the subject matter. No matter their form, they provide a single source of focused content.
In this anthology, we have compiled a collection of videos, technical blogs, podcasts, and articles that focus on Apache Spark's Structured Streaming.
Spark Summit 2017 Keynote: Apache Spark 2.2 and Structured Streaming Demo
Databricks' Chief Technologist Matei Zaharia thanks the community's contributions and announces Structured Streaming as ready for production.
Easy, Scalable, Fault-tolerant Stream Processing with Structured Streaming in Apache Spark 2.2
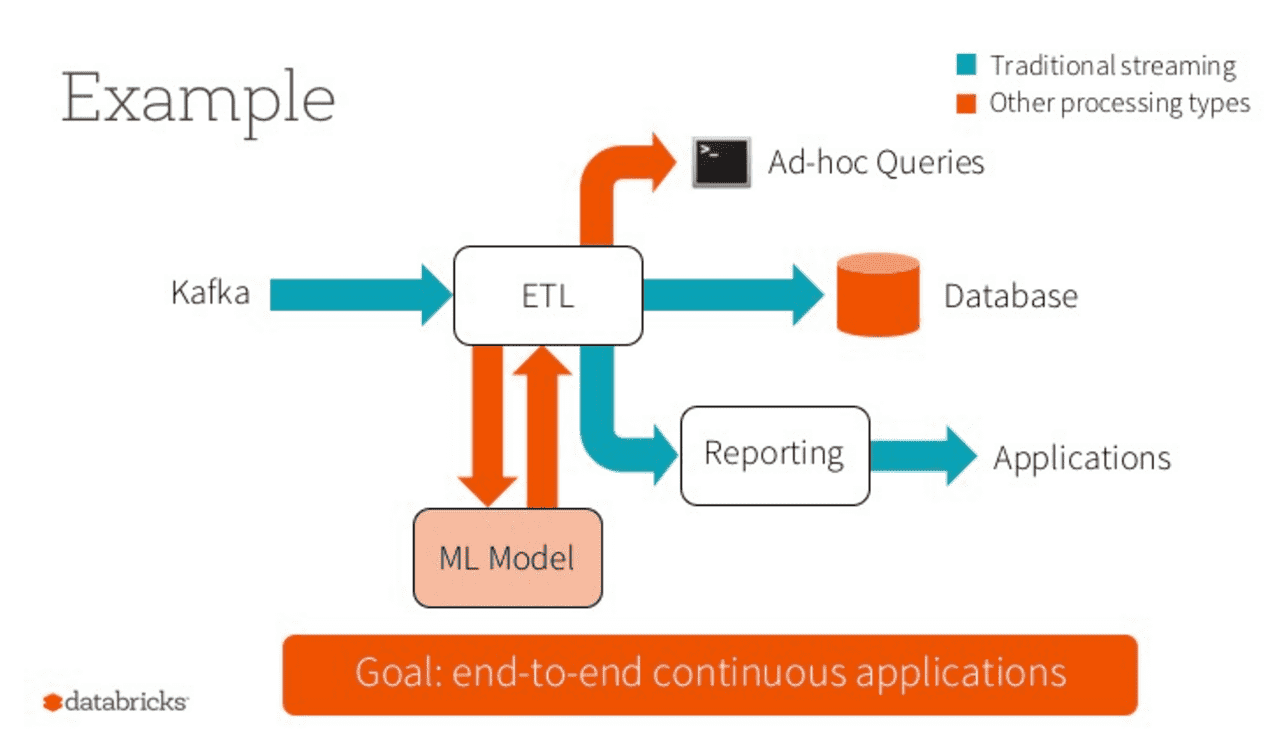
In less than 10 lines of code, you can read streams from Apache Kafka, parse JSON payload data into separate columns, transform it, enrich it by joining with static data and write it out as a table ready for batch or ad-hoc queries. Apache Spark committers and Databricks' engineers Michael Armbrust and Tathagata Das discuss and demonstrate that with concrete examples.
Also, they explain features that allow event-time based aggregations, arbitrary stateful operations, and automatic state management using event-time watermarks.
Continuous Applications: Evolving Streaming in Apache Spark 2.x
Last year, Databricks' Chief Technologist Matei Zaharia shared his vision of where Apache Spark streaming is heading: Continuous Applications with Structured Streaming is the next step, he wrote.
Structured Streaming In Apache Spark: A new high-level API for streaming
Databricks' engineers and Apache Spark committers Matei Zaharia, Tathagata Das, Michael Armbrust and Reynold Xin expound on why streaming applications are difficult to write, and how Structured Streaming addresses all the underlying complexities.
Real-time Streaming ETL with Structured Streaming in Apache Spark 2.1: Part 1 of Scalable Data @ Databricks
Databricks' engineers Tathagata Das, Michael Armbrust and Tyson Condie show how to do streaming ETL with real-time data at scale.
Working with Complex Data Formats with Structured Streaming in Apache Spark 2.1: Part 2 of Scalable Data @ Databricks
Learn from Databricks engineers and Apache Spark contributors Burak Yavuz, Michael Armbrust, Tathagata Das, and Tyson Condie how to handle complex and nested data formats with Structured Streaming.
Processing Data in Apache Kafka with Structured Streaming in Apache Spark 2.2: Part 3 of Scalable Data @ Databricks
Databricks engineers and Spark contributors Kunal Khamar, Tyson Condie and Michael Armbrust show how easily you can read streams from Apache Kafka using Structured Streaming APIs in Apache Spark 2.2.
Event-time Aggregation and Watermarking in Apache Spark's Structured Streaming: Part 4 of Scalable Data @ Databricks
How to do event-time aggregations and watermarking using simple Structured Streaming APIs? Databricks engineer and Spark committer Tathagata Das explains how.
Taking Apache Spark's Structured Streaming to Production: Part 5 of Scalable Data @ Databricks
How do you ensure your Structured Streaming Application is ready for production. Product Manager Bill Chambers and Apache Spark committer Michael Armbrust lay out the vital steps, using simple APIs for alerts and monitoring streaming query states.
Running Streaming Jobs Once a Day For 10x Cost Savings: Part 6 of Scalable Data @ Databricks
Apache Spark contributors Burak Yavuz and Tyson Condie demonstrate how to control and curb costs by using simple APIs such as Run Once trigger feature added to Structured Streaming in Spark 2.2. You get all the benefits of the Catalyst Optimizer incrementalizing your workload and the cost savings of not having an idle cluster lying around.
Arbitrary Stateful Processing in Apache Spark's Structured Streaming: Part 7 of Scalable Data @ Databricks
Databricks Product Manager Bill Chambers and Spark Community Evangelist Jules Damji demonstrate how to use Structure Streaming APIs for Customized and Arbitrary Stateful Processing
Real-Time End-to-End Integration with Apache Kafka in Apache Spark's Structured Streaming
Databricks Senior Solution Architect Sunil Sitaula guides you through an end-to-end integration with Apache Kafka, consuming messages from it, doing simple to complex windowing ETL, and pushing the desired output to various sinks such as memory, console, file, databases, and back to Kafka itself.
Making Apache Spark the Fastest Open Source Streaming Engine
Databricks' lead on Structured Streaming and Spark committer Michael Armbrust avers why Structured Streaming is the fastest open source engine compared to other streaming engines.
Apache Spark's Structured Streaming with Amazon Kinesis on Databricks: A quick guide on how to get started with Kinesis Connector
Databricks' Spark Community Evangelist Jules Damji outlines steps to use AWS Kinesis with Structured Streaming in Apache Spark 2.2 on Databricks Runtime 3.0.
Arbitrary Stateful Aggregations in Structured Streaming in Apache Spark
In this Bay Area Apache Spark Meetup talk, Burak Yavuz, Spark committer and Databricks software engineer, expands on how to use Structured Streaming APIs to maintain stateful aggregations.
Structured Streaming Comes to Apache Spark 2.0
O'Reilly's Chief Data Scientist Ben Lorica sits down with Michael Armbrust and talks about life and structured streaming.
What Spark's Structured Streaming Really Means
Ion Pointer (contributor for InfoWorld) advocates why DataFrames are the best choice for Apache Spark Streaming in Spark 2.0, and why structured streaming makes sense.
Apache Spark 2.0 to Introduce New 'Structured Streaming' Engine
Datanami sits down with Chief Technologist and Co-founder of Databricks Matei Zaharia to discuss all aspects of Structured Streaming in Apache Spark
What's Next?
You might want to bookmark this page, as we will update it with part 7 of our series on Structured Streaming. If you want to try some of the notebooks in these assets to explore Spark 2.2's Structured Streaming features on Databricks Runtime 3.0, you can sign up for a free trial.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.