Building Complex Data Pipelines with Unified Analytics Platform
by Jules Damji and Jason Pohl
Introduction
Big data practitioners often post recurring questions on Quora: What is data engineering? How to become a data scientist? What’s a data analyst?
Apart from understanding these roles and respective responsibilities, more important questions to pose are: How can three different personas, three different experiences, and three different requirements collaborate and combine their efforts? Or can they employ a unified platform rather than resort to one-off bespoke solutions?
Yes, they can collaborate and use a single platform. Last month, we announced our Unified Databricks Platform. Aimed to facilitate collaboration among data engineers, data scientists, and data analysts, two of its software artifacts—Databricks Workspace and Notebook Workflows—achieve this coveted collaboration.
In this blog, we will explore how each persona can
- Employ Notebook Workflows to collaborate and construct complex data pipelines with Apache Spark
- Orchestrate independent and idempotent notebooks as a single unit of execution
- Eliminate the need for bespoke one-off or distinct solutions.
Amazon Public Product Ratings
First, let’s look at the data scenario. Consider our data scenario as a corpus of Amazon public product ratings, where each persona expects data in a digestible format to perform respective tasks.
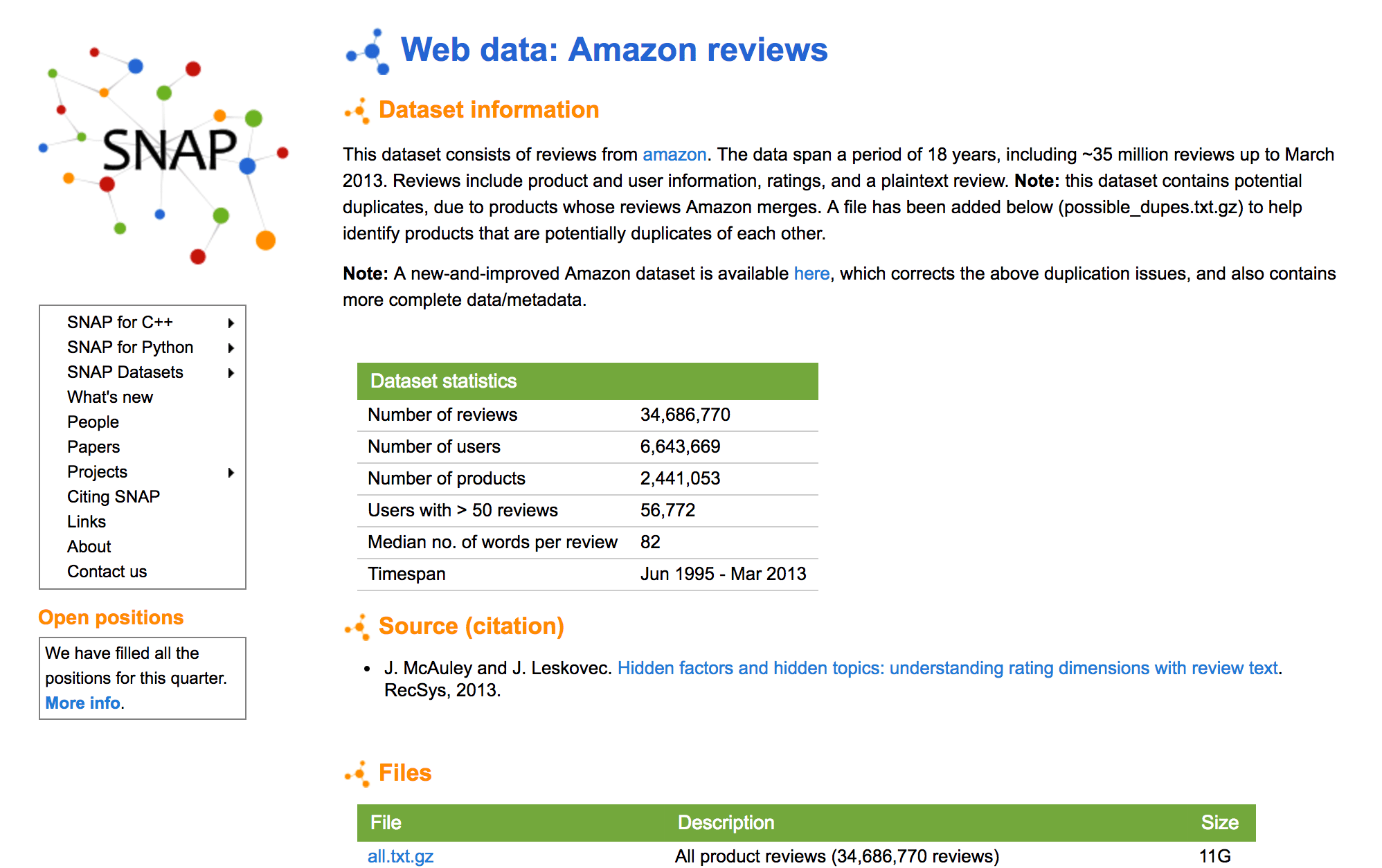
A corpus of product reviews with different data artifacts, this dataset is of interest to any data scientist or data analyst. For example, a data analyst may want to explore data to examine what kinds of ratings, product categories or brands exist. By contrast, a data scientist may want to train a machine learning model to predict favorable ratings with certain keywords—such as “great” or “return” or “horrible”—in the user reviews on a periodic basis.
But neither exploration (by a data analyst) nor training the model (by a data scientist) is possible without first transforming data into a digestible format for each of the personas. And that’s where a data engineer comes into the equation: She’s responsible to transform raw data into consumable data, by creating a data pipeline. (We refer to a ExamplesIngestingData notebook how a data engineer may ingest public data set into Databricks.)
Next, we will examine our first data pipeline, the first notebook TrainModel, and walk through the tasks pertaining to each persona.
Data Pipeline of Apache Spark Jobs
Exploring Data
For brevity we won’t go into the Python code that transformed raw data into JSON files for ingestion—that code is on this page. Instead, we will focus on our data pipeline notebook, TrainModel, that aids the data scientist and data analyst to collaborate.
Once our data engineer has ingested the corpus of product reviews into Parquet files, created an external Amazon table with parquet files, created a temporary view from that external table to explore portions of the table, both a data analyst and data scientist can work cooperatively within this TrainModel notebook.

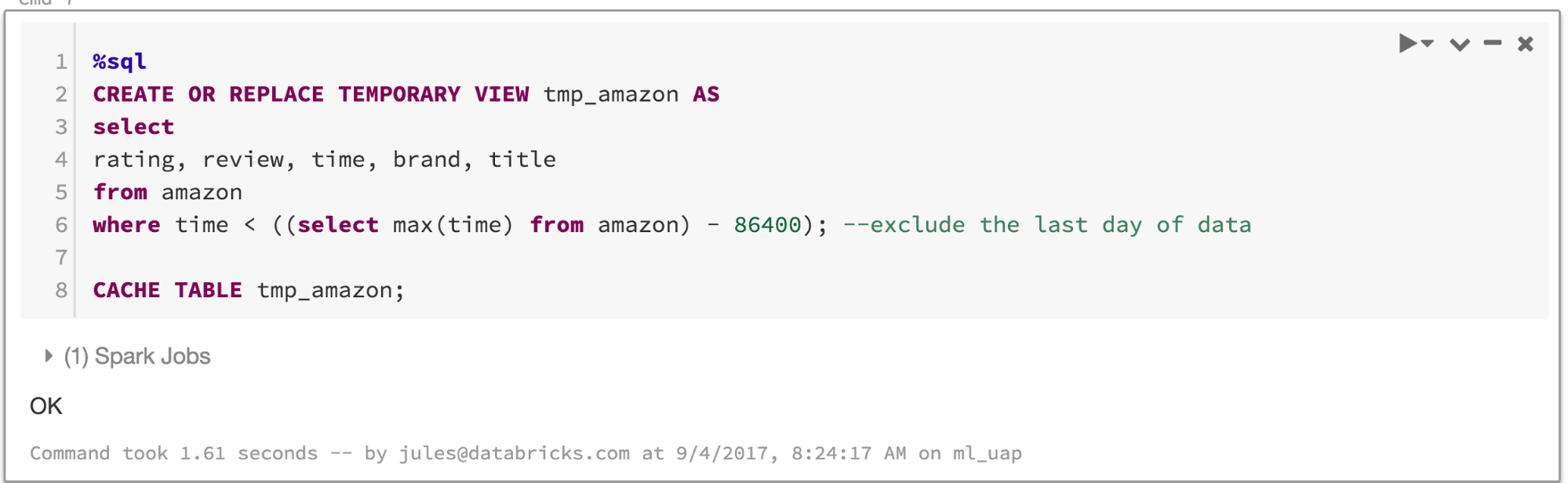
Rather than express computation in Python code, a language a data engineer or data scientist is more intimate with, a data analyst can express SQL queries. The point here is that the type of notebook—whether Scala, Python, R or SQL—is less important than the ability to express query in a familiar language (i.e., SQL) and to collaborate with others.
Now that we have digestible data for each persona, as a temporary table tmp_amazon, a data analyst can ask business questions and visualize data; she can query this table, for example, with the following questions:
What does the data look like?
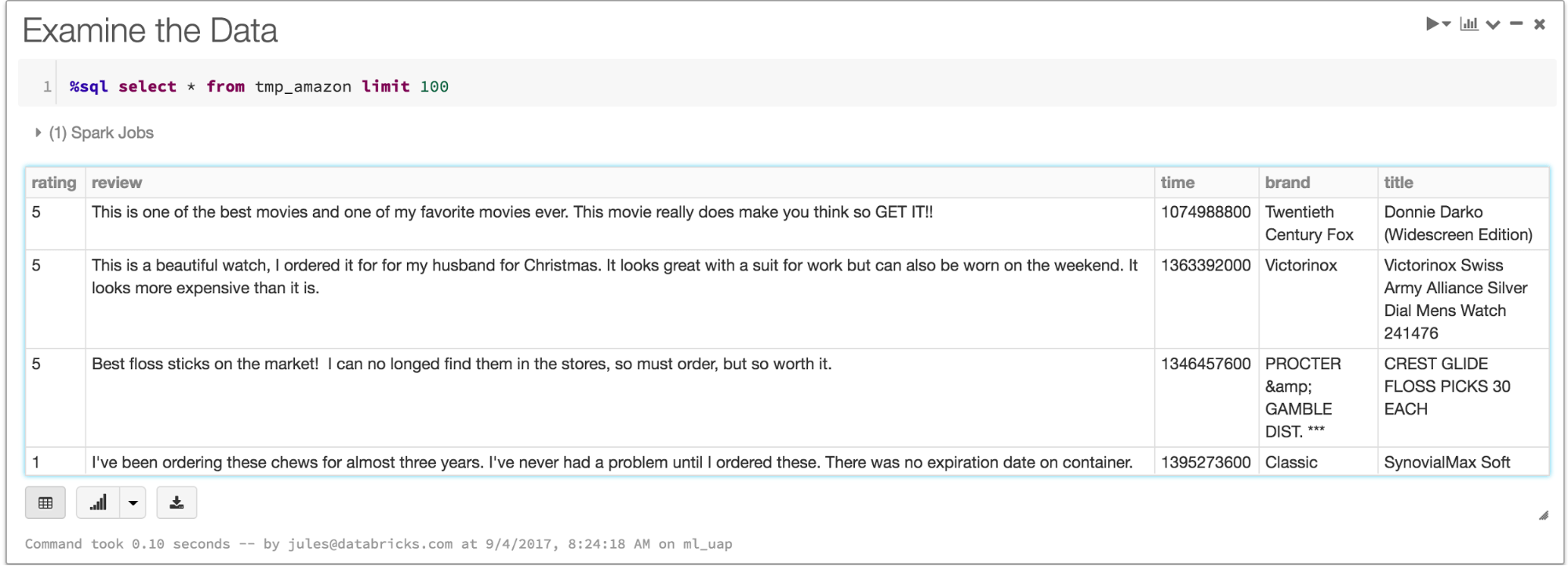
How many different brands?
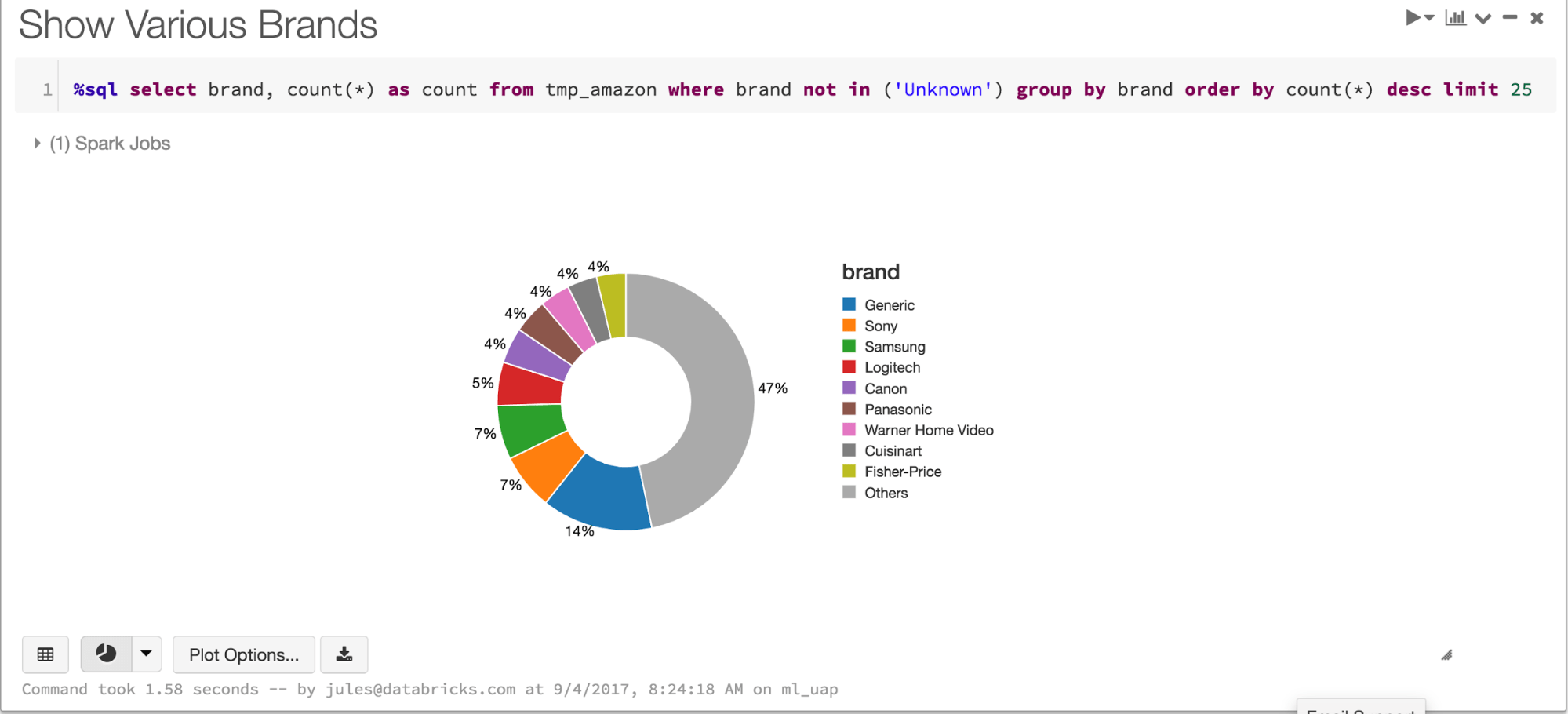
How do the brands fair in ratings?
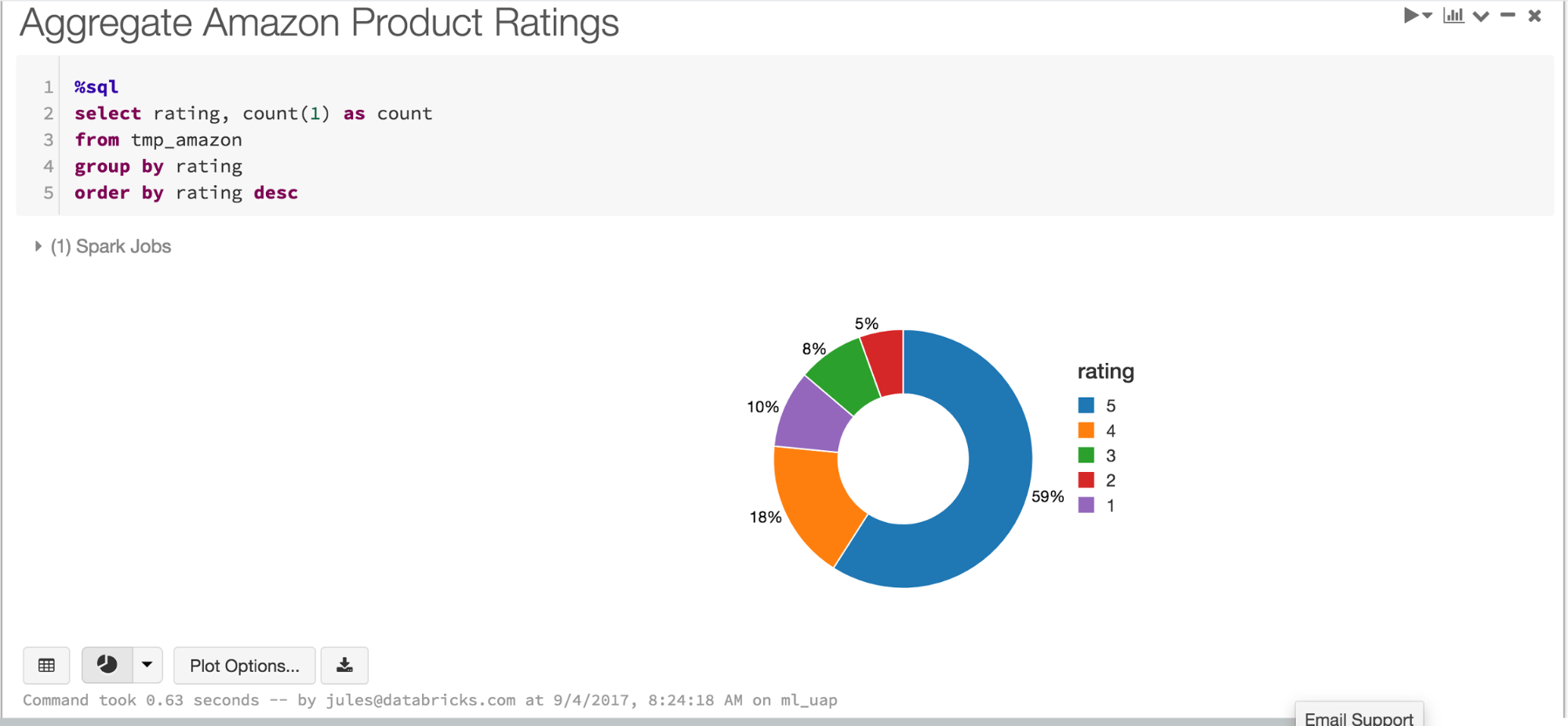
Satisfied with her preliminary analyses, she may turn to a data scientist who can devise a machine learning model that enables them to periodically predict ratings of user reviews. As users buy and rate products on the Amazon website, on daily or weekly basis, a machine learning model can be retrained with new data on regular basis in production.
Training the Machine Learning Model
Apache Spark’s Machine Learning Library MLlib contains many algorithms for classification, regression, clustering and collaborative filtering. At a high level, the spark.ml package provides tools, techniques, and APIs for featurization, pipelining, mathematical utilities, and persistence.
When it comes to binary predictions with outcomes of good (1) or bad (0) based on certain keywords, the best model suited for this classification is Logistic Regression Model, a special case of Generalized Linear Models that predict the probability of favorable outcomes.
In our case, we want to predict outcomes of ratings for reviews with some favorable keywords. Not only we will employ the binomial logistic regression of the family of logistic regression models offered by MLlib but use spark.ml pipelines and its Transformers and Estimators.
Create Machine Learning Pipeline
This snippet of Python code shows how to create the pipeline with transformers and estimators.
Create Training and Test Data
Next, we use our training data to fit the model and finally evaluate with our test data. The transformed DataFrames predictions should have our predictions and labels.

As you may notice from the above query on our predictions DataFrame saved as a temporary table that occurrences of the word return in the reviews in our test data result in value 0 for both prediction and label and low ratings as expected.
Satisfied with the results from evaluating the model, a data scientist can persist the model for either sharing with other data scientists for further evaluation or sharing with data engineer to deploy in production.
That is accomplished by persisting the model.
Persisting the Model
Consider use cases and scenarios where a data scientist produces an ML model and wants to test and iterate over it, deploy it into production for real-time prediction serving or share it with another data scientist to validate. How to do you do it?
Persisting and serializing the ML pipeline is one way to export MLlib models. Another way is to use Databricks dbml-local library, which is the preferred way for real-time serving with very low latency requirements. An important caveat: For low-latency requirements when serving the model, we advise and advocate using dbml-local. Yet for this example, because latency is not an issue or a requirement with periodic product reviews, we are using the MLlib pipeline API for exporting and importing the models.
Although dbml-local is our preferred way to export and import model, both mechanisms of persistence are important for many reasons. First, it is easy and language independent—the model is exported as JSON. Second, it can be exported from one notebook, written in Python, and imported (loaded) into another notebook, written in Scala—persisting and serializing a ML pipeline and the exchange format are language independent. Third, serializing and persisting the pipeline encapsulates all featurization, not just the model. And finally, if you wish to serve your model in real-time prediction with Structured Streaming.
In our TrainModel notebook, we export our model so that it can be imported by another notebook, ServeModel, downstream in our chained notebooks workflow (see below).
In the next section, we discuss our second pipeline, CreateStream.
Creating Streams
Consider this scenario: We have access to a live stream of product reviews and, using our trained model, we want to score against our model. A data engineer can offer this real-time data in two ways: one through Kafka or Kinesis as users rate the product on Amazon website; another through the new entries inserted into the table, which were not part of the training set, convert them into JSON files on S3. Indeed, that will just work, because Structured Streaming API reads data in the same manner whether your data sources are Blobs, files in S3, or streams from Kinesis or Kafka. We elected S3 over distributed queue for low cost and low latency.
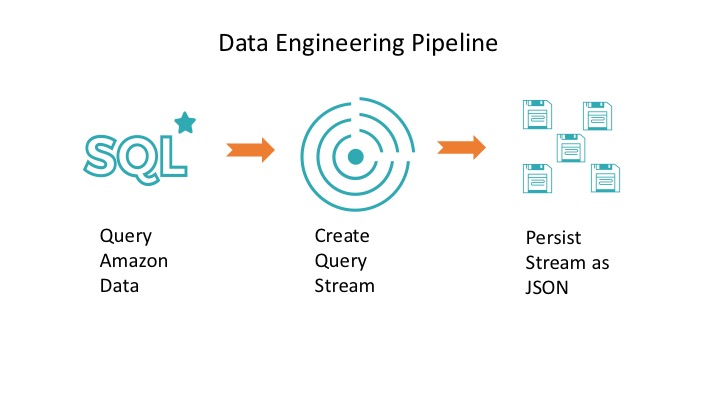
In our case, a data engineer can simply extract the most recent entries from our table, built atop Parquet files. This short pipeline consists of three Spark jobs:
- Query new product data from the Amazon table
- Convert the resulting DataFrame
- Store our DataFrames as JSON Files on S3
To simulate streams, we can treat each file as a collection of rows of JSON data as streaming data to score our model. This is not an uncommon case where a data scientist has trained a model and a data engineer is tasked to provide a way to get to the stream of live data persisted someplace where she can easily read and evaluate against the trained model.
To see how this is implemented, read the CreateStream notebook; its output serves JSON files as streams of Amazon reviews to the ServeModel notebook—to score against our persisted model. This leads to our final pipeline.
Serving, Importing and Scoring a Model
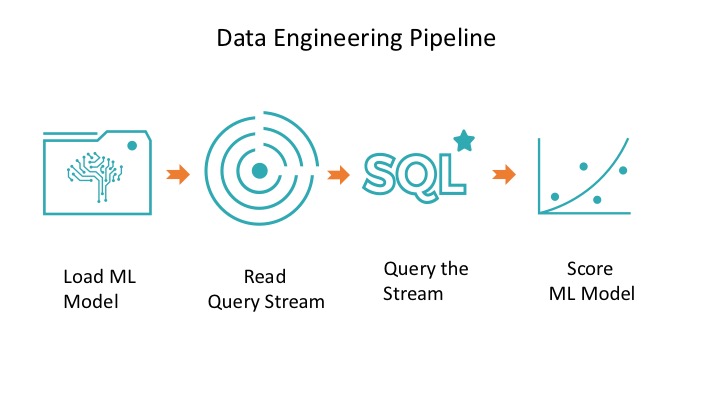
Consider the final scenario: We now have access to a live stream (or near a live stream) of new product reviews, and we have access to our trained model, which is persisted on our S3 bucket. A data scientist can then employ both these assets.
Let's see how. In our case, a data scientist can simply create short pipeline of four Spark jobs:
- Load the model from data store
- Read the JSON files as DataFrame input stream
- Transform the model with input stream
- Query the prediction
Since all the featurization is encapsulated in the persisted model, all we need is to load this serialized model as is from the disk and use it to serve and score our new data. Moreover, note that we created this model in the notebook TrainModel, which is written in Python, and we loaded inside a Scala notebook. This shows that regardless of language each persona is using to create notebooks, they can share persisted models in languages supported in Apache Spark.
Databricks Notebook Workflow Orchestration
Central to collaboration and coordination are Notebook Workflows’ APIs. With these APIs, a data engineer can string together all the aforementioned pipelines as a single unit of execution.
https://www.youtube.com/watch?v=byLFMgmHdwE
One way to achieve this is to share inputs and outputs among notebooks in the chain. That is, notebook’s output and exit status serve as input to the next notebook in the flow. Notebook Widgets allows parameterizing input to notebooks, whereas notebook’s exit status can pass arguments to the next one in the flow.
In our example, RunNotebooks invokes each notebook in the flow, with parameterized arguments. It will orchestrate three other notebooks, each executing its own data pipeline, creating its own Spark jobs within, and finally emitting a JSON document as its exit status. This JSON document then serves as an input parameter to the subsequent notebook in the pipeline.
Finally, not only you can run this particular notebook as an ephemeral job, but you can schedule the flow using the Job Scheduler.
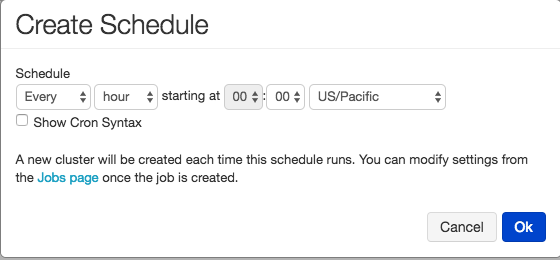
What’s Next
To really get the feel for this end-to-end collaboration among the three personas in the Unified Analytics Platform, try these five notebooks today on the Databricks platform.
- RunNotebooks, created by a data engineer
- TrainModel, created by a data engineer, data analyst, and data scientist
- CreateStream, created by a data engineer
- ServeModel, created by a data scientist and data engineer
- ExamplesIngestingData, a sample notebook for data engineer
In summary, we demonstrated that big data practitioners can work together in Databricks’ Unified Analytics Platform to create notebooks, explore data, train models, export models, and evaluate their trained model against new real-time data. Together, they become productive when complex data pipelines, when myriad notebooks, built by different personas, can be executed as a single and sequential unit of execution. Through Notebook Workflows APIs, we demonstrated a unified experience, not bespoke one-off solutions. All that promises benefits.
Read More
To understand Notebook Workflows and Widgets and Notebooks integration in Github, read the following:
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.