Cloud-based Relational Database Management Systems at Databricks
by Yun Zhang, Aaron Davidson, Lucian Popa and Jules Damji
Databricks and Microsoft have jointly developed a new cloud service called Microsoft Azure Databricks, which makes Apache Spark analytics fast, easy, and collaborative on the Azure cloud. Not only does this new service allow data scientists and data engineers to be more productive and work collaboratively with their respective teams, but it also gives them the ability to create and execute complex data pipelines without leaving the platform.
While working with their data, users create additional content like source code, configuration, and even credentials inside the platform. In order to store this content in a scalable, durable, and available manner, Databricks relies on MySQL and PostgreSQL operated as a service by Azure and AWS. In this blog post, we will explore seven reasons why we chose a cloud-managed solution, why relational database management system (RDBMS) like MySQL and PostgreSQL made the cut, and share our experience with the Azure Database for MySQL, and Azure Database for PostgreSQL offerings.
Why Cloud-Managed Storage?
Database as a Service, or specifically relational database as a service, is an established concept in the Cloud Computing world. While the advantages of using cloud-managed (as opposed to self-managed) databases have been documented on both the AWS and Azure websites, we would like to emphasize why this is especially critical given the size of our engineering team and the myriad databases we have to support at Databricks. In the first section, we will answer the question of why Databricks chose cloud-managed storage, in the aspects of scalability, operational simplicity, and cost efficiency.
Scalability
Inside Databricks, we follow the service-oriented architecture as one of our primary design principles (illustrated in Fig. 1). Each service is backed by its own database for performance and security isolation. We routinely introduce new services to the family as we further our SaaS offering. For the sake of data locality, availability, and compliance related to geographic data provenance, we also run our database instances collocated with our control plane services in various regions throughout the world, resulting in more databases being added over time.
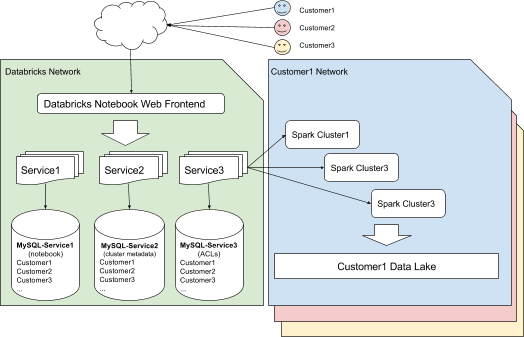
To easily provision new databases to adapt to the growth, the Cloud Platform team at Databricks provides MySQL and PostgreSQL as one of the many infrastructure services. Through this service, Databricks engineers can request a new database at any time for a new application, such as a hackathon project they’re working on, or expand easily to a new region. In such cases, they describe the provisioning request through a unified resource template file. This template is then translated into a cloud-specific representation by our automation pipeline and eventually fulfilled by the Cloud Provider (for example, ARM template).
On the other hand, as new services gain more traffic over time, we need to change the computing or storage power correspondingly for additional capacity. With the resource templating system, Databricks engineers can easily update the database template file to specify the new performance requirements. Cloud providers, like Azure Database for MySQL and PostgreSQL, provide the ability to update the computing and storage resources of a targeted database with minimal downtime.
Using the on-demand request-and-provision model, we can quickly launch new services, increase service capacity and expand to new regions, giving us an immense ability to both scale up and scale out.
Operational Simplicity
Because most of our databases are provisioned along with services that serve real customer traffic, they have to be built with production-grade reliability. For example, they need to support sharding, backup, recovery, encryption, regular upgrades, and much more. To perform this operational work routinely for self-managed databases, we would need to hire a dedicated DBA team with years of experience. Fortunately, a managed database address all these concerns for us. For instance, Azure managed MySQL and PostgreSQL provide built-in high availability feature, encryption for data-at-rest and in-motion by default and also handle automatic patching and management of backups, which allows us to focus on delivering features and value that matters most to our customers.
Cost Efficiency
Most customers use Databricks to process their data in a cloud data lake, like Amazon S3 or Azure Blob Storage. First of all, it would not make much sense to build any databases from the ground up in an on-premise data center, given the size of our company, and the need to collocate our services with customer data, for reduced latency and data transfer fee. Secondly, we don’t want to manage our own installations of MySQL or PostgreSQL on the cloud either. Because by doing so, we would pay separately for the virtual machines, storage, and usage of all other related services, instead of just paying for the hourly rate of the managed database. We would also need to pay for the engineering time spent to develop and maintain an administration process around these databases. Adding up all these costs together, it turns out managed database solution is not only cheaper but also better structured in pricing, allowing us to easily budget against our usage forecast.
Why Relational Database Management System?
Although popular and modern NoSQL stores such as Apache Cassandra or DynamoDB or object stores like S3 and Azure Blog are considered alternatives for storage architecture, we elected MySQL and PostgreSQL for many reasons. First, they were cloud agnostic, giving us freedom. Second, they offered high-level SQL-based API with transactionality support, which is an imperative design point. Another reason was its simple programming model that suited our use case, especially when the data volume is low to medium. In the following section, we will answer why Databricks chose relational databases for most of our Control Plane services by elaborating on each of these reasons.
Cloud Agnostic
At Databricks we ensure that our customers can process their data, regardless of cloud providers they use. Keeping that requirement in mind, any technologies we integrate into our product must be cloud agnostic, for the purpose of running the same Control Plane services anywhere on multiple clouds. This requirement makes it difficult to use a number of cloud-specific options, like DynamoDB or Microsoft SQL Server.
MySQL and PostgreSQL are both widely adopted open source databases. Multiple stable versions of both are available on almost all cloud providers today, like AWS, Azure, and GCP. Their JDBC and ODBC drivers are also among the most common database interfaces that have been integrated with a wide range of tools and frameworks.
As an example, consider our recent announcement on Azure Databricks. When we decided to offer our product on Azure, we were looking to use a fully managed MySQL and PostgreSQL offering on the Azure platform. Fortunately, Microsoft was just in the process of releasing such an offering.
Since deploying the Azure Databricks Control Plane in Azure, and during the private preview period, our service has used the Azure managed MySQL and PostgreSQL offering. This offering has met and exceeded our expectations in terms of stability and performance and has made our transition to Azure an order of magnitude easier compared to us hosting such a service on our own.
All this speaks to our requirement for cloud-agnostic technology and easy integration. Next, we explore why transactionality is equally important.
Transactionality
While Databricks users are working in our product, they’re generating complex data operations against the underlying databases at the same time. For example, adding a new cell to the notebook may trigger multiple reads and writes against different storage locations (tables of relational databases, or keys or partitions of NoSQL databases). MySQL and PostgreSQL have the mature support of transactions that guarantees data consistency for such use cases.
On the other hand, most Databricks services are deployed on the Kubernetes clusters in a distributed and replicated way—each service instance functions independently and shares nothing but the database so that in the case of sudden instance loss, the service would still be accessible by customers. With this architecture, global synchronization like total order publishing is usually achieved at the database level using transactions provided by MySQL and PostgreSQL.
Simple Programming Model
One key difference between a relational database and a key-value store is the SQL support, which is a higher level abstraction for data manipulations and therefore more developer friendly. Developers can easily perform tasks like JOIN and indexing to fetch complicated data types in a timely fashion.
Also available are a ton of tools and framework built around RDBMS over the decades, which significantly simplify routine tasks like schema management and object-relational (O-R) mapping that used to be headaches. At Databricks, we’ve been using flyway for schema management and JDBI for O-R mapping.
As part of easy programming model criteria, developers should be able to choose whatever new tools they feel like to use in their own services. We poll our developers frequently on what impacts developers' time, and we have found that schema migration or writing tedious O-R mapping code has not been a large time sink.
All these developer-friendly attributes of MySQL and PostgreSQL make for a simple programming model.
Data Volume
Finally, let’s consider data volume. Because our Control Plane services don’t process data-intensive workload inside Databricks network or process large datasets inside customers’ data lake or warehouses, data capacity is not an issue. What matters are rapid recordings of interactions from our notebooks that issue code or commands from each cell. These commands when recorded don’t demand immense storage.
For example, an average user would generate in the order of tens to hundreds of notebooks, each typically containing a few hundred lines of code as commands. This data volume is well below the maximum capacity of either MySQL or PostgreSQL when aggregated across thousands of users. Because of this nature of Control Plane workload, it’s more enticing for us to use relational databases and take the three advantages above, instead of taking a trade-off and looking for a NoSQL alternative which is usually better for elasticity or schema flexibility.
Conclusion
To summarize, cloud-managed relational databases provide good support around production readiness, transactionality, high-level cloud-agnostic interfaces with an attainable cost that are critical to the success of both Databricks and our customers. Products like Azure Database for MySQL and PostgreSQL, built with the community version of database engines, offer us tremendous value in terms of high availability, performance, scalability, and operational flexibility. They’re an essential part of our platform offering to other engineering teams to boost their level of autonomy and productivity.
Read More
To find out about the Azure Databricks announced last week, read our blog here.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.