Introducing Apache Spark 2.3
by Sameer Agarwal, Xiao Li, Reynold Xin and Jules Damji
Today we are happy to announce the availability of Apache Spark 2.3.0 on Databricks as part of its Databricks Runtime 4.0. We want to thank the Apache Spark community for all their valuable contributions to Spark 2.3 release.

Continuing with the objectives to make Spark faster, easier, and smarter, Spark 2.3 marks a major milestone for Structured Streaming by introducing low-latency continuous processing and stream-to-stream joins; boosts PySpark by improving performance with pandas UDFs; and runs on Kubernetes clusters by providing native support for Apache Spark applications.
In addition to extending new functionality to SparkR, Python, MLlib, and GraphX, the release focuses on usability, stability, and refinement, resolving over 1400 tickets. Other salient features from Spark contributors include:
- DataSource v2 APIs [SPARK-15689, SPARK-20928]
- Vectorized ORC reader [SPARK-16060]
- Spark History Server v2 with K-V store [SPARK-18085]
- Machine Learning Pipeline API model scoring with Structured Streaming [SPARK-13030, SPARK-22346, SPARK-23037]
- MLlib Enhancements Highlights [SPARK-21866, SPARK-3181, SPARK-21087, SPARK-20199]
- Spark SQL Enhancements [SPARK-21485, SPARK-21975, SPARK-20331, SPARK-22510, SPARK-20236]
In this blog post, we briefly summarize some of the high-level features and improvements, and in the coming days, we will publish in-depth blogs for these features. For a comprehensive list of major features across all Spark components and JIRAs resolved, read the Apache Spark 2.3.0 release notes.
Continuous Stream Processing at Millisecond Latencies
Structured Streaming in Apache Spark 2.0 decoupled micro-batch processing from its high-level APIs for a couple of reasons. First, it made developer’s experience with the APIs simpler: the APIs did not have to account for micro-batches. Second, it allowed developers to treat a stream as an infinite table to which they could issue queries as they would a static table.
However, to provide developers with different modes of stream processing, we introduce a new millisecond low-latency mode of streaming: continuous mode.
Under the hood, the structured streaming engine incrementally executed query computations in micro-batches, dictated by a trigger interval, with tolerable latencies suitable for most real-world streaming applications.
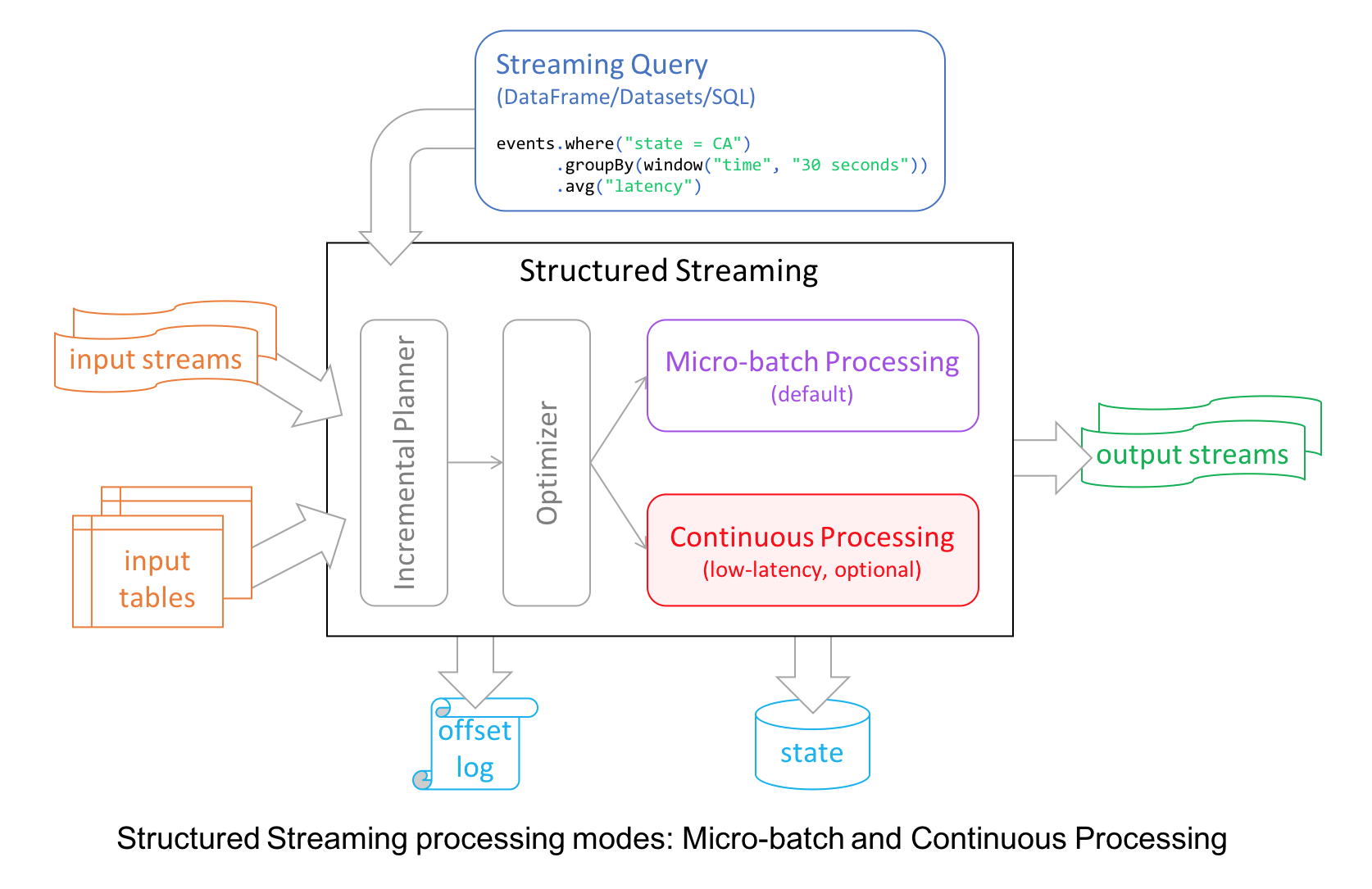
For continuous mode, instead of micro-batch execution, the streaming readers continuously poll source and process data rather than read a batch of data at a specified trigger interval. By continuously polling the sources and processing data, new records are processed immediately upon arrival, as shown in the timeline figure below, reducing latencies to milliseconds and satisfying low-level latency requirements.
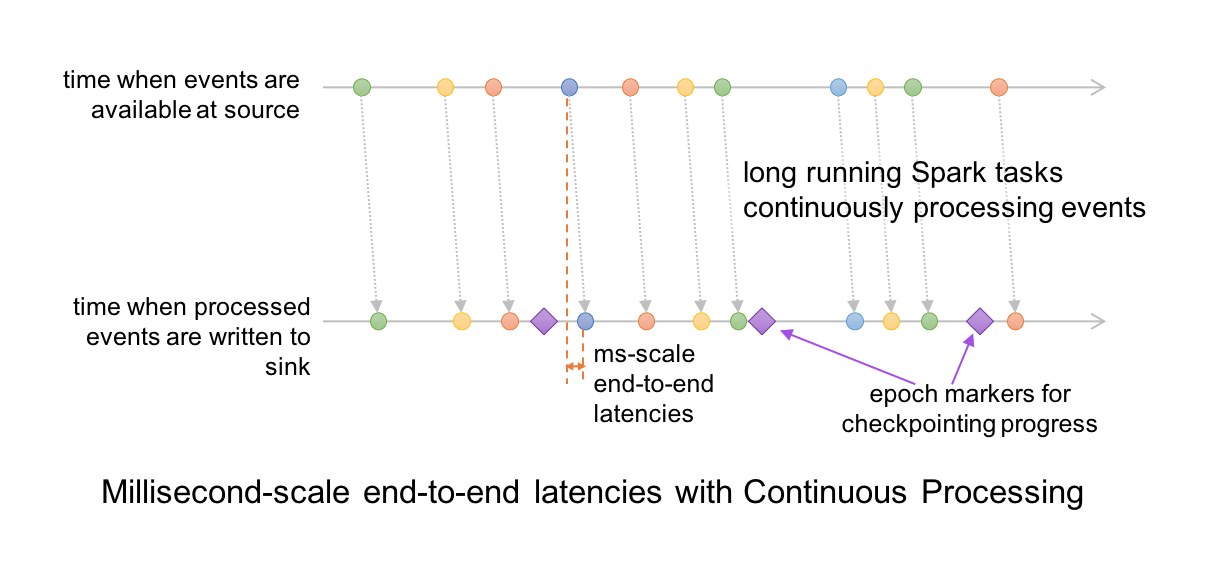
As for operations, it currently supports map-like Dataset operations such as projections or selections and SQL functions, with the exception of current_timestamp(), current_date() and aggregate functions. As well as supporting Apache Kafka as a source and sink, continuous mode currently supports console and memory as sinks, too.
Now developers can elect either mode—continuous or micro-batching—depending on their latency requirements to build real-time streaming applications at scale while benefiting from the fault-tolerance and reliability guarantees that Structured Streaming engine affords.
In short, the continuous mode in Spark 2.3 is experimental and it offers the following:
- end-to-end millisecond low latencies
- provides at-least-once guarantees.
- supports map-like Dataset operations
In this technical blog on Continuous Processing mode, we illustrate how to use it, its merits, and
how developers can write continuous streaming applications with millisecond low-latency requirements.
Stream-to-Stream Joins
While Structured Streaming in Spark 2.0 has supported joins between a streaming DataFrame/Dataset and a static one, this release introduces the much awaited stream-to-stream joins, both inner and outer joins for numerous real-time use cases.
The canonical use case of joining two streams is that of ad-monetization. For instance, an impression stream and an ad-click stream share a common key (say, adId) and relevant data on which you wish to conduct streaming analytics, such as, which adId led to a click.
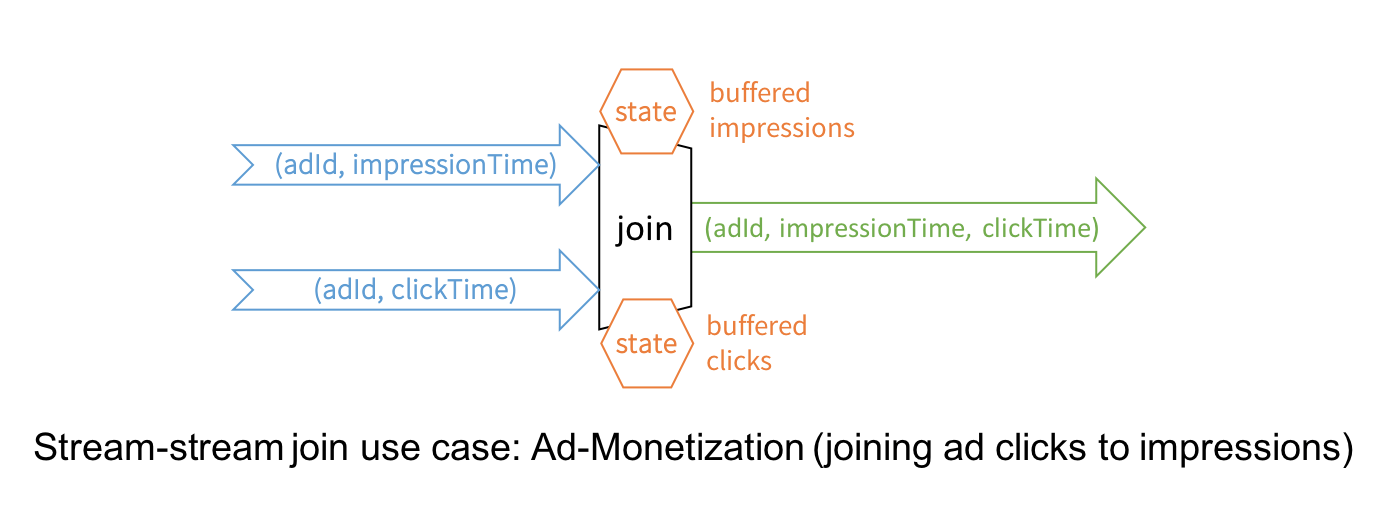
While conceptually the idea is simple, stream-to-stream joins resolve a few technical challenges. For example, they:
- handle delayed data by buffering late events as streaming “state” until matching event is found from the other stream
- limit the buffer from growing and consuming memory with watermarking, which allows tracking of event-time and accordingly clearing of old state
- allow a user to control the tradeoff between the resources consumed by state and the maximum delay handled by the query
- maintain consistent SQL join semantics between static joins and streaming joins
In this technical blog, we dive deeper into streams-to-stream joins.
Apache Spark and Kubernetes
No surprise that two popular open source projects Apache Spark and Kubernetes combine their functionality and utility to provide distributed data processing and orchestration at scale. In Spark 2.3, users can launch Spark workloads natively on a Kubernetes cluster leveraging the new Kubernetes scheduler backend. This helps achieve better resource utilization and multi-tenancy by enabling Spark workloads to share Kubernetes clusters with other types of workloads.
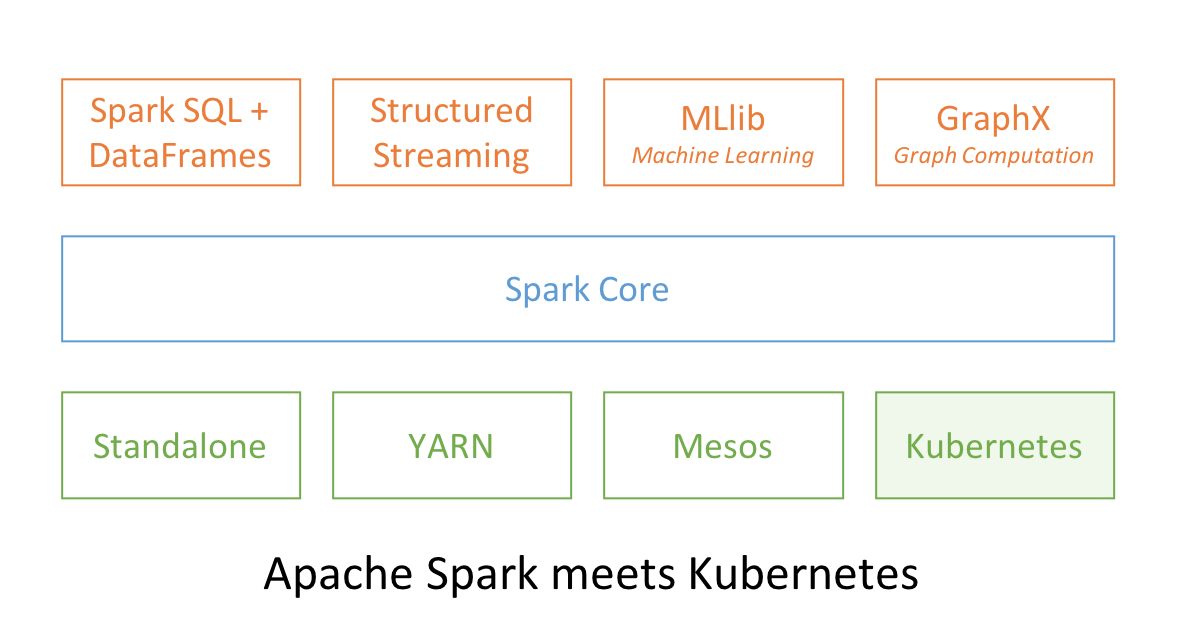
Also, Spark can employ all the administrative features such as Resource Quotas, Pluggable Authorization, and Logging. What’s more, it’s as simple as creating a docker image and setting up the RBAC to start employing your existing Kubernetes cluster for your Spark workloads.
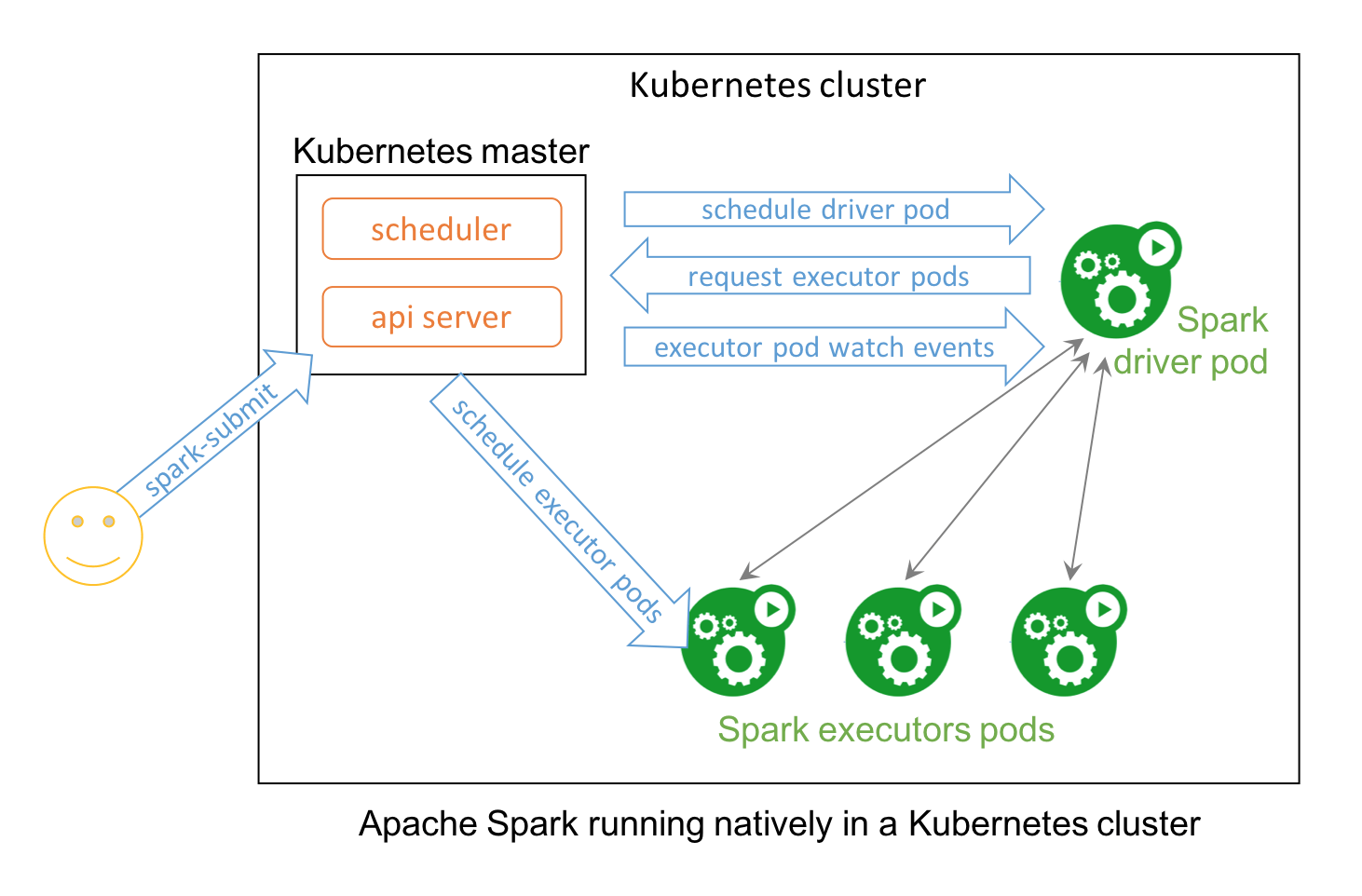
This technical blog explains how you can use Spark natively with Kubernetes and how to get involved in this community endeavor.
Pandas UDFs for PySpark
Pandas UDFs, also called Vectorized UDFs, is a major boost to PySpark performance. Built on top of Apache Arrow, they afford you the best of both worlds—the ability to define low-overhead, high-performance UDFs and write entirely in Python.
In Spark 2.3, there are two types of Pandas UDFs: scalar and grouped map. Both are now available in Spark 2.3. Li Jin of Two Sigma had penned an earlier blog, explaining their usage through four examples: Plus One, Cumulative Probability, Subtract Mean, Ordinary Least Squares Linear Regression.
Running some micro benchmarks, Pandas UDFs demonstrate orders of magnitude better performance than row-at-time UDFs.
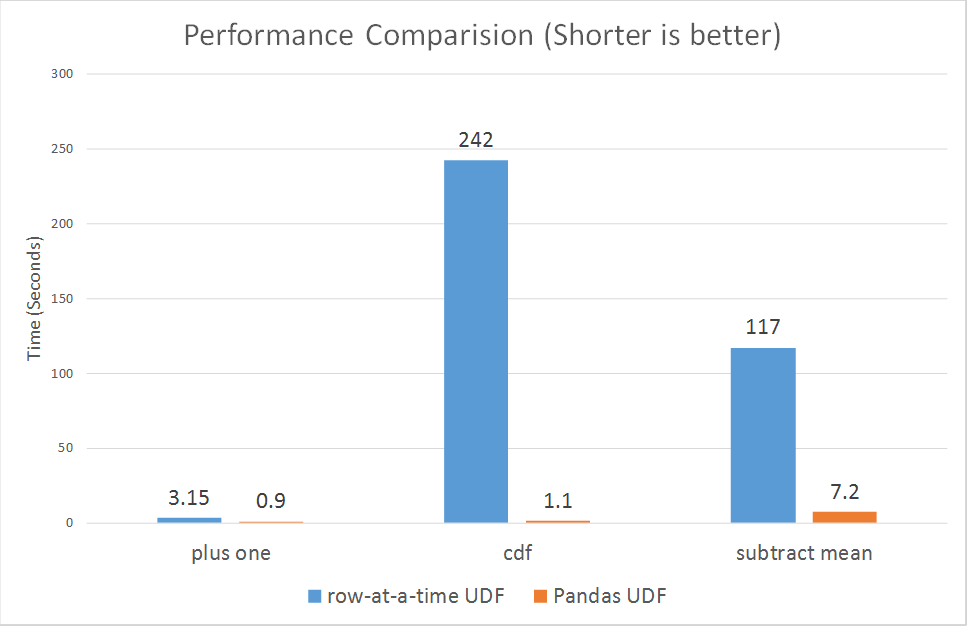
According to Li Jin and other contributors, they plan to introduce support for Pandas UDFs in aggregations and window functions, and its related work can be tracked in SPARK-22216.
MLlib Improvements
Spark 2.3 includes many MLlib improvements for algorithms and features, performance and scalability, and usability. We mention three highlights.
First, for moving MLlib models and Pipelines to production, fitted models and Pipelines now work within Structured Streaming jobs. Some existing Pipelines will require modifications to make predictions in streaming jobs, so look for upcoming blog posts on migration tips.
Second, to enable many Deep Learning image analysis use cases, Spark 2.3 introduces an ImageSchema [SPARK-21866] for representing images in Spark DataFrames, plus utilities for loading images from common formats.
And finally, for developers, Spark 2.3 introduces improved APIs in Python for writing custom algorithms, including a UnaryTransformer for writing simple custom feature transformers and utilities for automating ML persistence for saving and loading algorithms. See this blog post for details.
What's Next?
Once again, we want to thank all the contributions from the Spark community!
While this blog post only summarized some of the salient features in this release, you can read the official release notes to see the complete list of changes. Stay tuned as we will be publishing technical blogs explaining some of these features.
If you want to try Apache Spark 2.3 in Databricks Runtime 4.0. Sign up for a free trial account here
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.