A Guide to AI, Machine Learning, and Data Science Talks at Spark + AI Summit
by Jules Damji
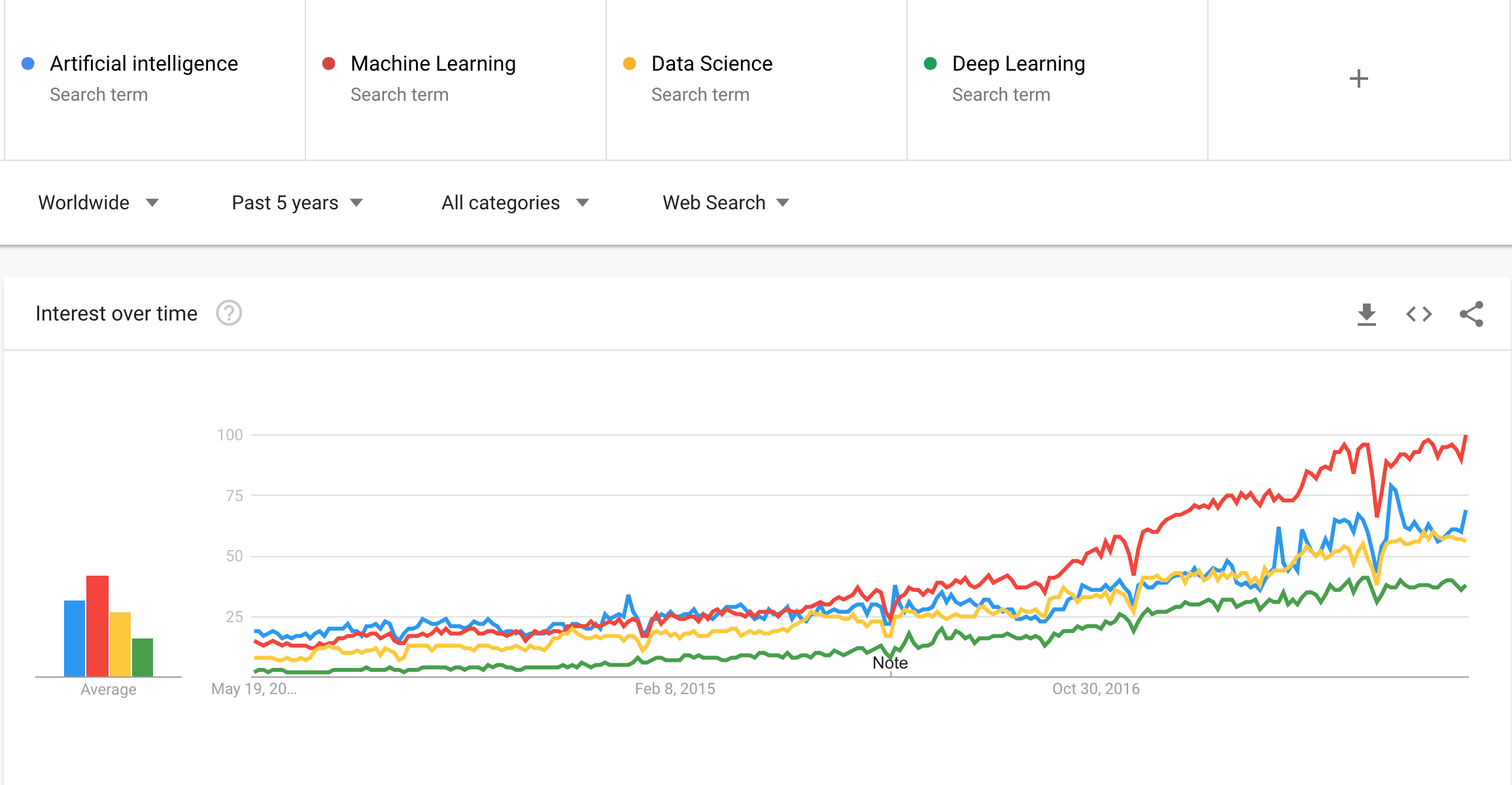
By any measurement today, in the digital media, technical conferences and citations, or searches on Google trends, the frequency of terms like artificial intelligence, machine learning, deep learning or data science is on the rise. A special report
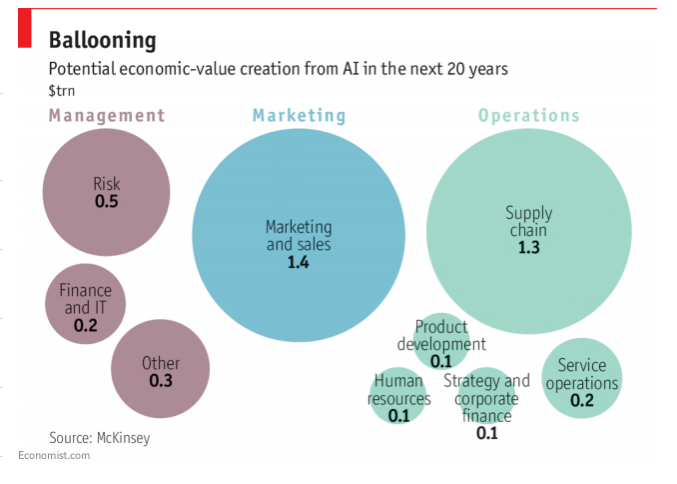
in The Economist makes the case that Artificial Intelligence (AI) and Machine Learning (ML), and its purported tectonic shifts, is spreading beyond the technology sector, with big consequences in different market segments, affecting workers and consumers and generating a potential economic-value from AI in the next couple of decades.
{kind=link}
But doing AI and ML are not so much of a problem as managing and processing big data at scale and its infrastructure is. And the problem is not so much in the machine learning code or algorithms as it is in the technical debt in supporting the infrastructure.
For the Spark + AI Summit, we expanded new tracks to attract talks that speak of AI use cases, data science, and productionizing machine learning to address how practitioners operate in the real world and manage their infrastructure for these use cases. In this blog, we point to a few sessions that speak volumes in their endeavors in combining the immense value of data and AI.
Let’s start to examine how Mastercard productionizes their AI as a service platform using distributed deep learning techniques and productizing User-Items Propensity Models with Apache Spark at scale. Suqiang Song will share with the community their technical journey and AI architecture design principles for this service in his talk, AI as a Service, Build Shared AI Service Platforms Based on Deep Learning Technologies.
At some point, we all have inadvertently interacted with AI assistants, chatbots. What is the technical mystery behind them? How do you build and operate them? David Low of Pand.ai reveals the finer technical details of building and deploying LSTM machine learning models as well as discuss the current and future state of chatbots in his talk, The Rise of Conversational AI.
It’s one thing to build an ML model; it’s another to manage and deploy it in production. In his talk, Productionizing Apache Spark ML Pipelines with the Portable Format for Analytics, IBM’s Nick Pentreath will discuss a portable format to productionize Apache Spark ML pipelines.
Similarly, Databricks’ Joseph Bradley will discuss developments in Apache Spark to deploy MLlib models and pipelines within Structured Streaming. In the session, Deploying MLlib for Scoring in Structured Streaming, he will share how new developments in Apache Spark 2.3 and MLlib support deploying MLlib models and Pipelines for scoring and predicting in Structured Streaming and why it simplifies many production cases.
Now, if you live in a metropolitan area, you have likely taken an Uber at some point to reach your desired destination. Ever wonder how they compute prices in real-time for over 600 cities? Or curious what machine learning algorithms they use, or how data scientists work to do feature engineering? Messrs Peng Du and Felix Cheung from Uber will reveal technical details of their machine learning infrastructure in their session, Building Intelligent Applications, Experimental ML with Uber’s Data Science Workbench.
And if you have traveled lately, you have likely stayed at an Airbnb rental. Behind that ease-of-use and comfort of selecting myriad rentals of your choice is a complex infrastructure supporting an end-to-end machine learning production life-cycle. Session talks form Airbnb, Bighead: Airbnb’s End-to-End Machine Learning Platform and Zipline: Airbnb’s Machine Learning Data Management Platform will expose Airbnb’s machine learning platforms that enable them to cover data collection at scale, do feature engineering, and train, deploy, productionize, and monitor their infrastructure.
For those using cloud computing for their infrastructure, cost management is as important as reliability. At Databricks, we invest heavily in cloud computing, because it’s our core business to offer unified analytics platform, powered by optimized Apache Spark, to our customers. Hence, cost management for our customers becomes an imperative function as part of the cost of goods (COGS) and operating expenses (OPEX). Data scientist Xuan Wang, from Databricks, will demonstrate how we detect changes and do forecasts to minimize costs and share some data science techniques in his talk, Cloud Cost Management and Apache Spark.
Finally, Natural Language Processing (NLP) as a way to parse spoken or written text is paramount to ML and AI applications. Building a complex NLP system requires an infrastructure and use of three software frameworks: machine learning, deep learning, and Apache Spark NLP libraries. Apache Spark NLP: Extending Spark ML to Deliver Fast, Scalable & Unified Natural Language Processing session by engineers Alexander Thomas and David Talby dives into all aspects of optimization, sentiment detection, lemmatization, language modeling, and pipeline building.
What’s Next
There is much to peruse and pick sessions that appeal to you from the schedule, too. In the final blog, we will share our picks from Developer, Spark Experience, Deep Dives, and related tracks.
If you have not registered yet, use JulesPicks code for a $300 discount. See you there!
Read More
- Check out Few Picks From TensorFlow Sessions
- Find out 5 Reasons to Attend Spark + AI Summit
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.