A Guide to AI, Machine Learning, and Deep Learning Talks at Spark + AI Summit Europe
by Jules Damji
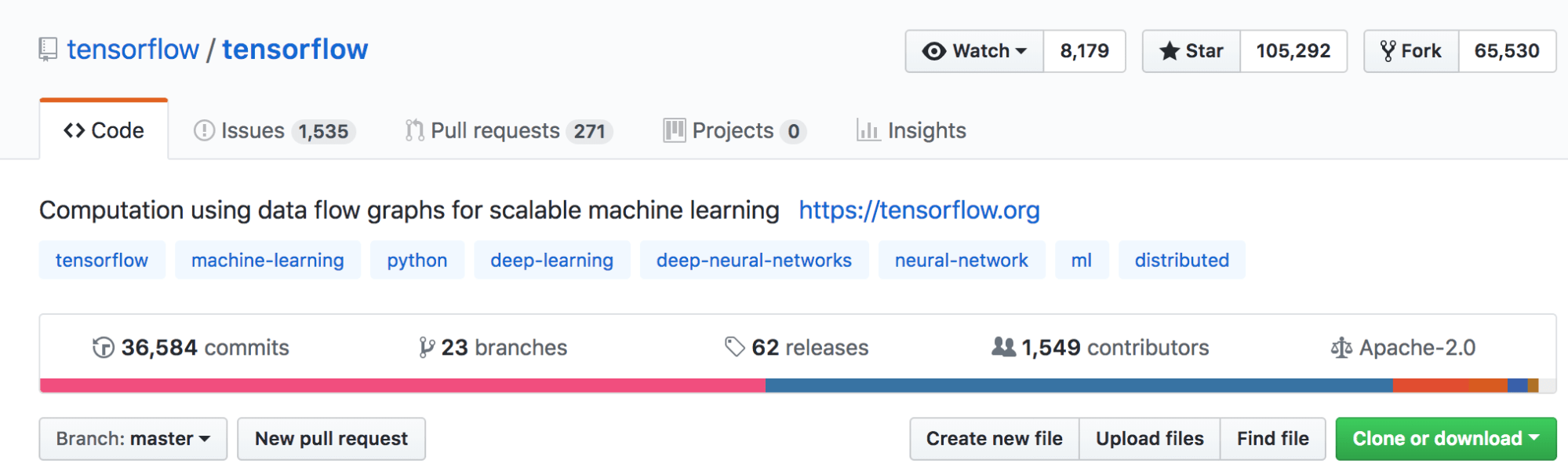
Within a couple of years of its release as an open-source machine learning and deep learning framework, TensorFlow has seen an amazing rate of adoption. Consider the number of stars on its github page: over 105K; look at the number of contributors: 1500+; and observe its growing penetration and pervasiveness in verticals: from medical imaging to gaming; from computer vision to voice recognition and natural language processing.
As in Spark + AI Summit in San Francisco, so too in Spark + AI Summit Europe, we have seen high-caliber technical talks about the use of TensorFlow and other deep learning frameworks as part of the new tracks: AI, Productionizing ML, and Deep Learning Techniques. In this blog, we highlight a few talks that caught our eye, in their promise and potential. It always helps to have some navigational guidance if you are new to the summit or technology.
For example, look how Logical Clocks AB is using Apache Spark and TensorFlow to herald novel methods for developing distributed learning and training. Jim Dowling in his talk, Distributed Deep Learning with Apache Spark and TensorFlow, will explore myriad ways Apache Spark is combined with deep learning frameworks such as TensorFlow, TensorFlowonSpark, Horovod, and Deep Learning Pipelines to build deep learning applications.
Closely related to the above talk in integrating popular deep learning frameworks, such as TensorFlow, Keras or PyTorch, as first-class citizens on Apache Spark is Project Hydrogen: Unifying State-of-the-Art AI and Big Data in Apache Spark. Messrs Tim Hunter and Xiangrui Meng will share how to unify data and AI in order to simplify building production-ready AI applications. Continuing on how Spark integrates well with deep learning frameworks, Messrs Tim Hunter and Debajyoti Roy will discuss how to accomplish Geospatial Analytics with Apache Spark and Deep Learning Pipelines.
Now, if you are a news junky and wonder how to decipher and discern its emotive content, you may marvel at the use of sophisticated algorithms and techniques behind it and how to apply it. In this fascinating use case, An AI Use Case: Market Event Impact Determination via Sentiment and Emotion Analysis, Messrs Lei Gao and Jin Wang, both from IBM, will reveal the technical mastery. Similarly, if you are curious how social media images, when analyzed and categorized employing AI, are engaging, say for marketing campaigns, this session from Jack McCush will prove equally absorbing: Predicting Social Engagement of Social Images with Deep Learning.
At the Spark + AI Summit in San Francisco, Jeffrey Yau’s talk on Time Series Forecasting Using Recurrent Neural Network and Vector Autoregressive Model: When and How was a huge hit. He will repeat it in London on how two specific techniques—Vector Autoregressive (VAR) Models and Recurrent Neural Network (RNN)—can be applied to financial models. Also, IBM’s Nick Pentreath will provide an overview of RNN, modeling time series and sequence data, common architectures, and optimizing techniques in his talk, Recurrent Neural Networks for Recommendations and Personalization.
Data and AI are all about scale—about productizing ML models, about managing data infrastructure that supports the ML code. Three talks seem to fit the bill that may be of interest to you. First is from Josef Habdan, an aviation use case aptly titled, RealTime Clustering Engine Using Structured Streaming and SparkML Running on Billions of Rows a Day. Second is from Messrs Gaurav Agarwal and Mani Parkhe, from Uber and Databricks, Intelligence Driven User Communications at Scale. And third deals with productionizing scalable and high volume Apache Spark pipelines for smart-homes with hundreds of thousands of users. Erni Durdevic of Quby in his talk will share, Lessons Learned Developing and Managing High Volume Apache Spark Pipelines in Production.
At Databricks we cherish our founders’ academic roots, so all previous summits have had research tracks. Research in technology heralds paradigm shifts—for instance, at UC Berkeley AMPLab, it led to Spark; at Google, it led to TensorFlow; at CERN it led to the world wide web. Nikolay Malitsky’s talk, Spark-MPI: Approaching the Fifth Paradigm, will address the existing impedance mismatch between data-intensive and compute-intensive ecosystems by presenting the Spark-MPI approach, based on the MPI Process Management Interface (PMI). And Intel researchers Qi Xie and Sophia Sun will share a case study: Accelerating Apache Spark with FPGAs: A Case Study for 10TB TPCx-HS Spark Benchmark Acceleration with FPGA.
And finally, if you’re new to TensorFlow, Keras or PyTorch and want to learn how it all fits in the grand scheme of data and AI, you can enroll in a training course offered on both AWS and Azure: Hands-on Deep Learning with Keras, Tensorflow, and Apache Spark. Or to get a cursory and curated Tale of Three Deep Learning Frameworks, attend Brooke Wenig’s and my talk.
What's Next
You can also peruse and pick sessions from the schedule, too. In the next blog, we will share our picks from sessions related to Data Science, Developer and Deep Dives.
If you have not registered yet, use this code JulesPicks and get 20% discount.
Read More
Find out more about initial keynotes: Spark + AI Summit Europe Agenda Announced
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.