Lakeflow
Ingest, transform, and orchestrate with a unified data engineering solution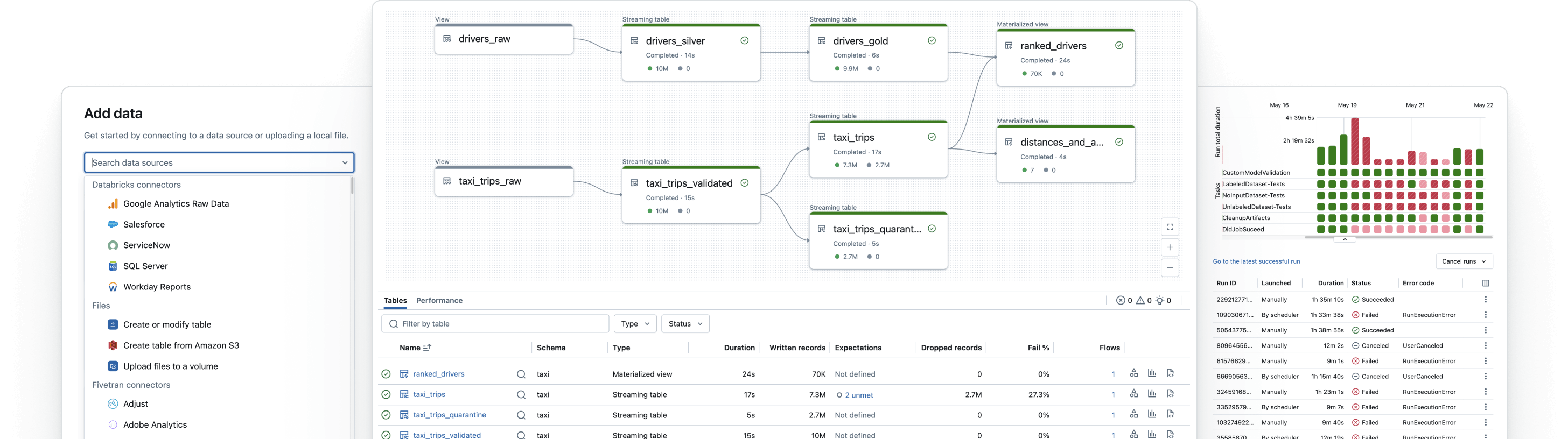
TOP COMPANIES USING LAKEFLOW
The end-to-end solution for delivering high-quality data.
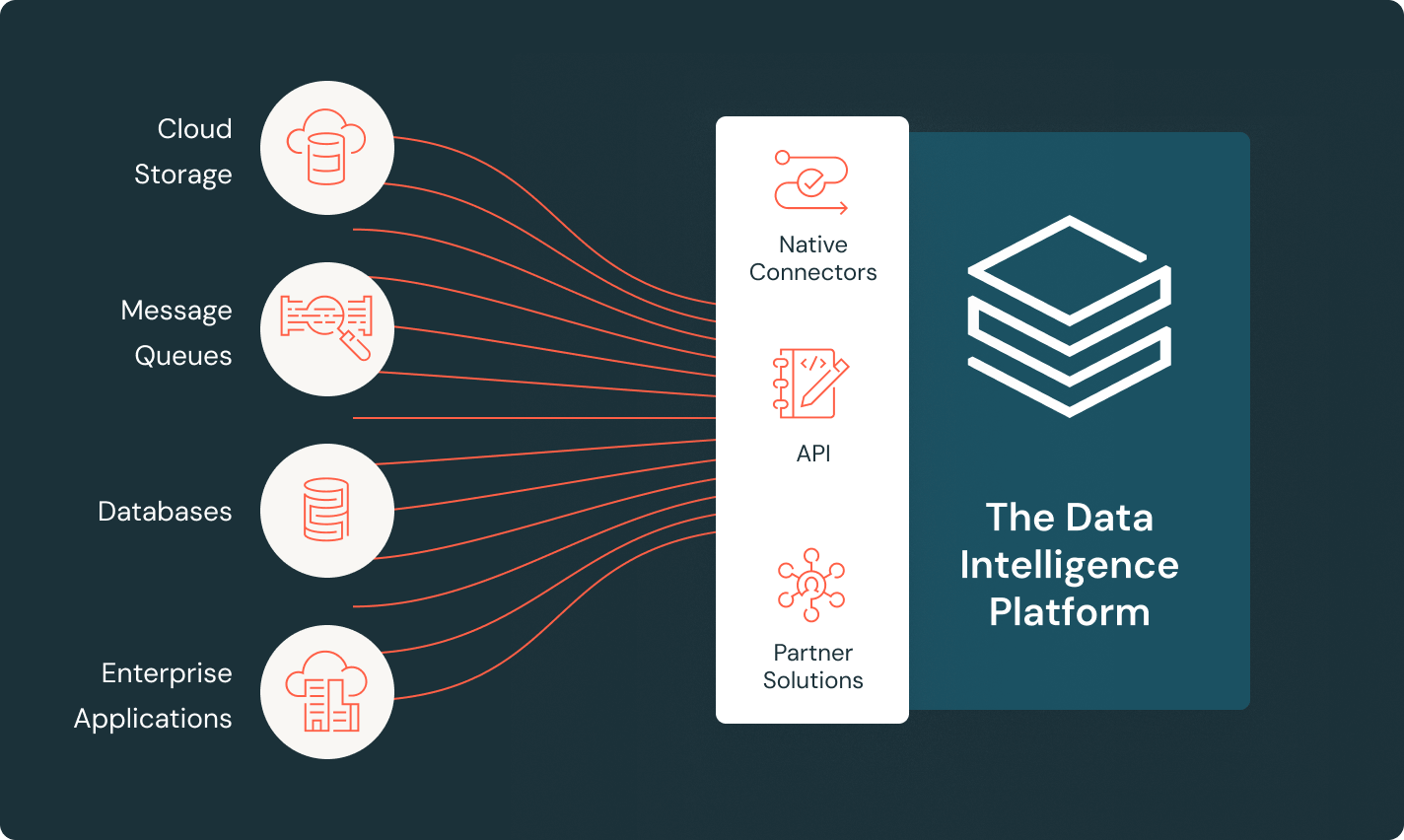
Tooling that makes it easy for every team to build reliable data pipelines for analytics and AI.Unified tool stack
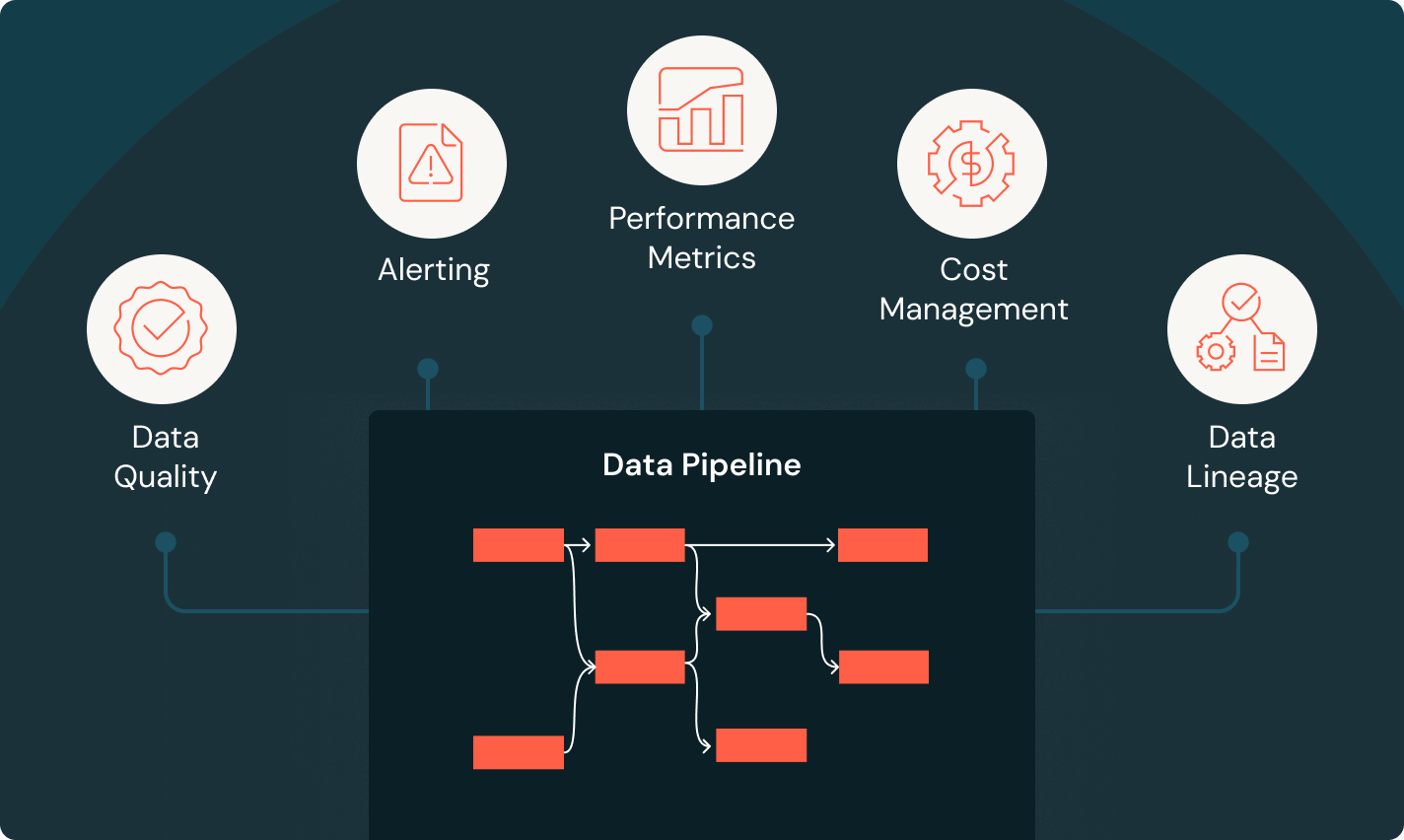
Reduce costs and integration overhead with a single solution to collect and clean all your data. Stay in control with built-in, unified governance and lineage.
Agentic data engineering
Use natural language to build faster with agents that understand your data and can author, maintain and troubleshoot data pipelines.
Efficient data processing
A powerful engine under the hood auto-optimizes resource usage for better price/performance for both batch and real-time use cases.
85% faster development
50% cost reduction
99% reduction in pipeline latency
Unified tooling for any data engineering workload
Genie Code
Build and maintain data pipelines with agentic AI that understands your data.

Lakeflow Connect
Efficient data ingestion connectors and native integration with the Data Intelligence Platform unlock easy access to analytics and AI, with unified governance.

Apache Spark™ Declarative Pipelines
Simplify batch and streaming ETL with automated data quality, change data capture (CDC), data ingestion, transformation, and unified governance.

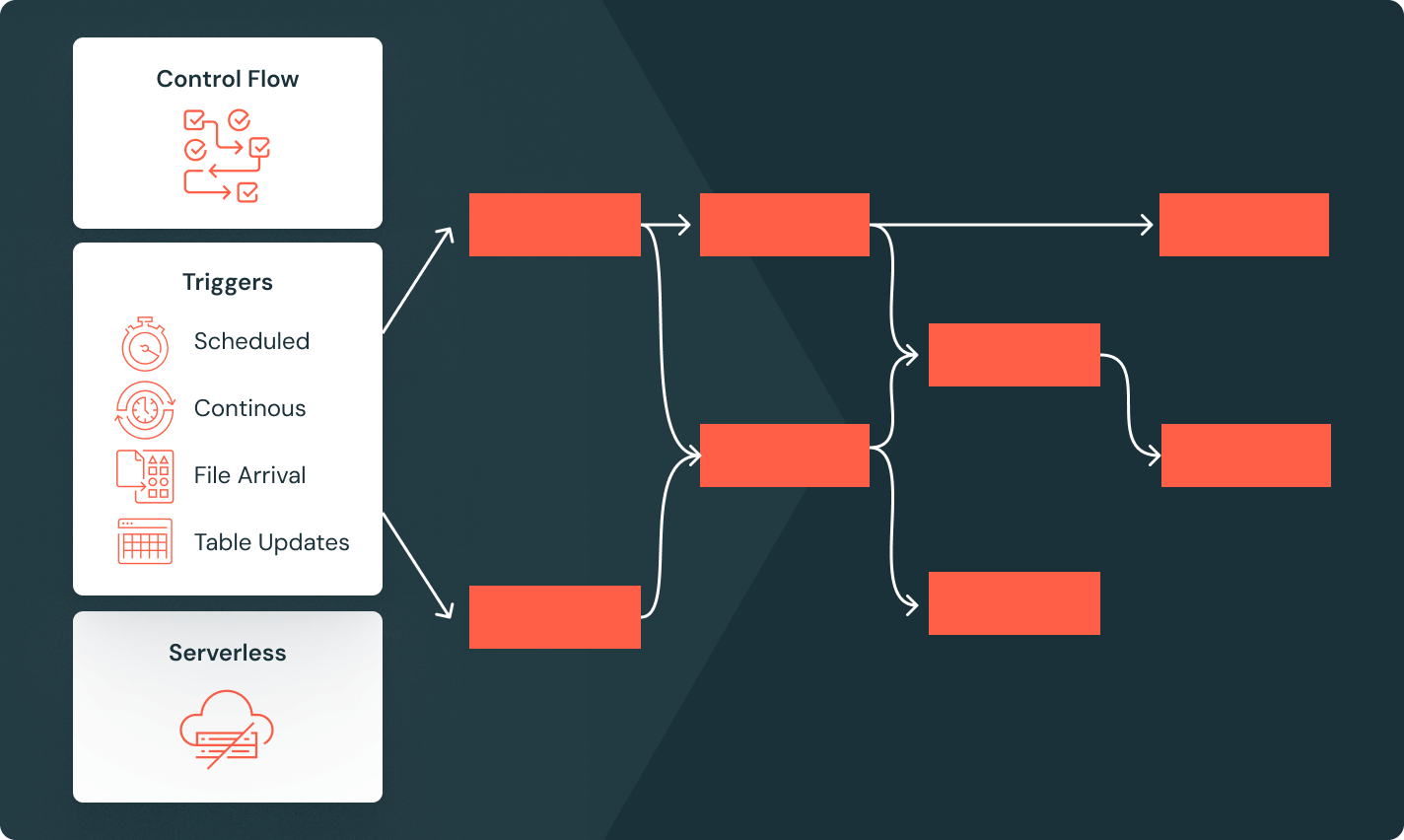
Lakeflow Jobs
Equip teams to better automate and orchestrate any ETL, analytics, and AI workflow with deep observability, high reliability, and broad task type support.

Unity Catalog
Seamlessly govern all your data assets with the industry’s only unified and open governance solution for data and AI, built into the Databricks Data Intelligence Platform.
Lakeflow Designer
Prepare and transform data with AI-first authoring, directly on Databricks.
Build reliable data pipelines

Transform raw data into high-quality gold tables
Implement ETL pipelines to filter, enrich, clean and aggregate data so it’s ready for analytics, AI and BI. Follow the medallion architecture to process data from bronze through silver to gold tables.

Take the next step




Data Engineering FAQ
Ready to become a data + AI company?
Take the first steps in your data transformation