Building a Real-Time Attribution Pipeline with Databricks Delta
by Caryl Yuhas and Denny Lee
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
In digital advertising, one of the most important things to be able to deliver to clients is information about how their advertising spend drove results. The more quickly we can provide this, the better. To tie conversions or engagements to the impressions served in an advertising campaign, companies must perform attribution. Attribution can be a fairly expensive process, and running attribution against constantly updating datasets is challenging without the right technology. Traditionally, this has not been an easy problem to solve as there are lots of things to reason about:
- How do we make sure the data can be written at low latency to a read location without corrupting records?
- How can we continuously append to a large, query-able dataset without exploding costs or loss of performance?
- And where and how should I introduce a join for attribution?
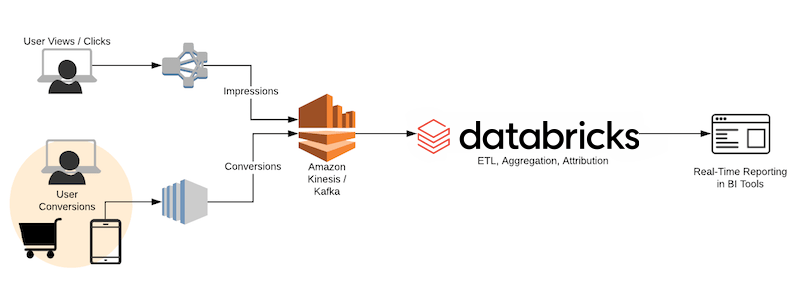
Fortunately, Databricks makes this easy with Structured Streaming and Databricks Delta. In this blog post (and associated notebook), we are going to take a quick look at how to use the DataFrame API to build Structured Streaming applications on top of Kinesis (for those using Azure Databricks, you can use Azure EventHubs, Apache Kafka on HDInsight, or Azure Cosmos DB integration), and use Databricks Delta to query the streams in near-real-time. We will also show how you can use the BI tool of your choice to review your attribution data in real-time.
Define Streams
The first thing we will need to do is to establish the impression and conversion data streams. The impression data stream provides us a real-time view of the attributes associated with those customers who were served the digital ad (impression) while the conversion stream denotes customers who have performed an action (e.g. click the ad, purchased an item, etc.) based on that ad.
With Structured Streaming in Databricks, you can quickly plug into the stream as Databricks supports direct connectivity to Kafka (Apache Kafka, Apache Kafka on AWS, Apache Kafka on HDInsight) and Kinesis as noted in the following code snippet (this is for impressions, repeat this step for conversions)
Next, create data streams schema as noted in the following code snippet.
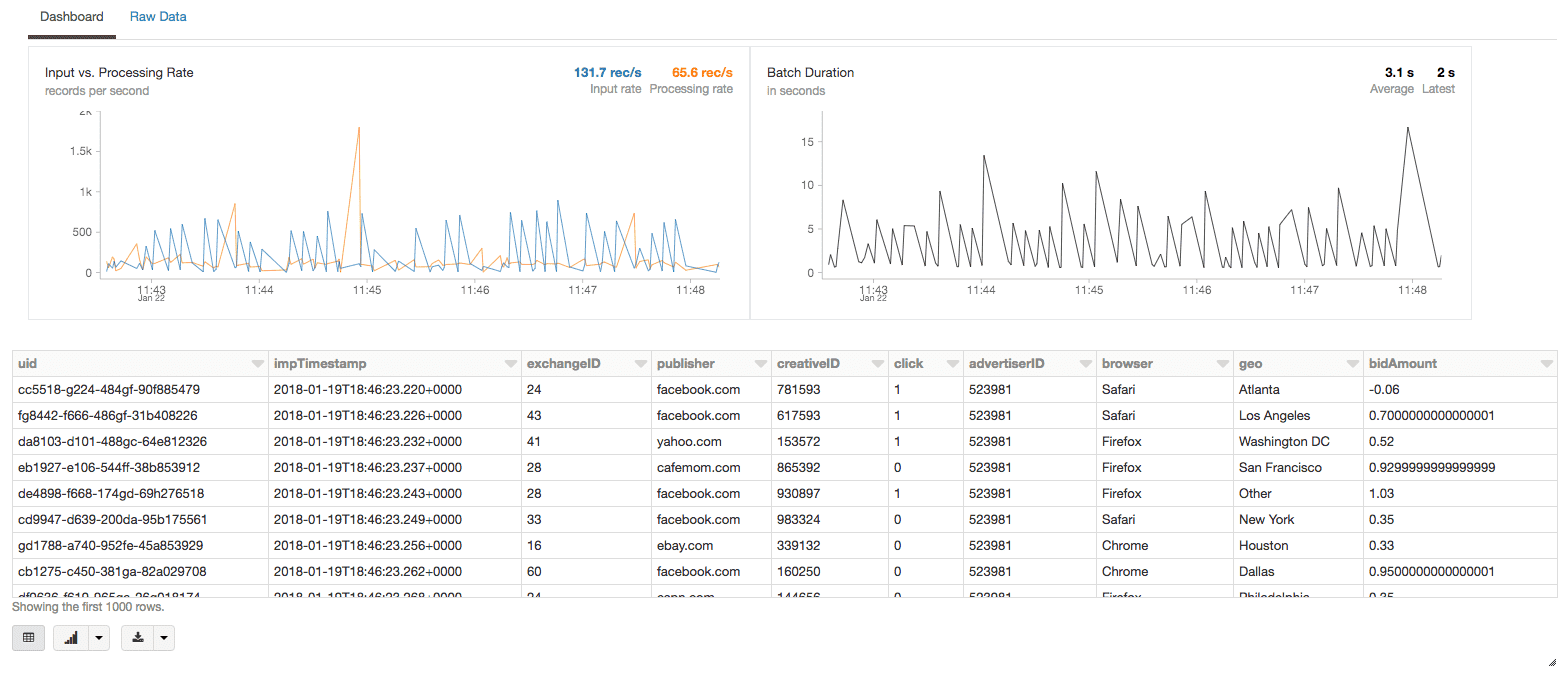
Finally, we will want to create our streaming impressions DataFrame. With the Databricks display command, we will see both the data and the input/processing rate in real-time alongside our data.
Sync Streams to Databricks Delta
The impression (imp) and conversion (conv) streams can be synced directly to Databricks Delta allowing us a greater degree of flexibility and scalability for this real-time attribution use-case. t allows you to quickly write these real-time data streams into Parquet format on S3 / Blob Storage while allowing users to read from the same directory simultaneously without the overhead of managing consistency, transactionality and performance yourself. As noted in the following code snippet, we’re capturing the raw records from a single source and writing it into its own Databricks Delta table.
It is important to note that with Databricks Delta, you can also:
- Apply additional ETL, analytics, and/or enrichment steps at this point
- Write data from different streams or batch process and different sources into the same table
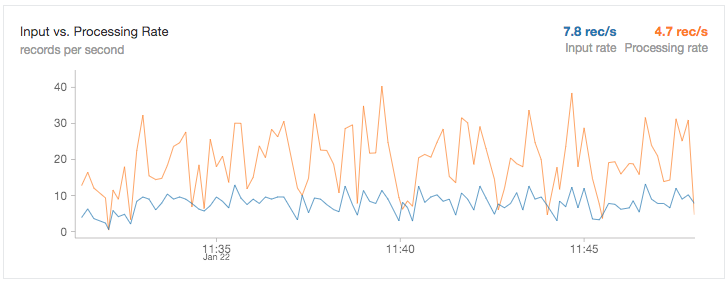
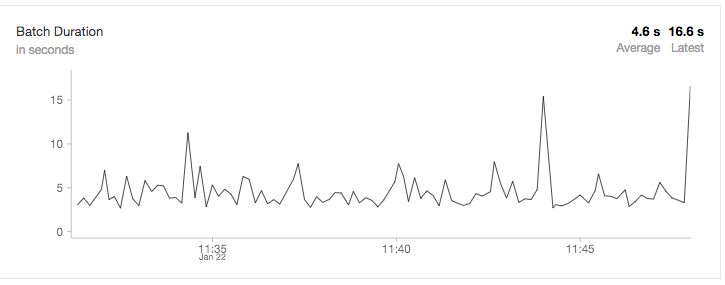
Databricks Delta Views for Ad Hoc Reporting
Now that we have created our impression and conversion Databricks Delta tables, we will create named views so we can easily execute our joins in Spark SQL as well as make this data available to query from your favorite BI tool. Let’s first start with creating our Databricks Delta views.
Calculate Real-time Attribution
Now that we have established our Databricks Delta views, we can calculate our last touch attribution on the view and then calculate weighted attribution on the view.
Calculate Last Touch Attribution on View
To calculate the real-time window attribution, as noted in the preceding sections, we will need to join two different Delta streams of data: impressions and conversions. As noted in the following code snippet, we will first define our Databricks delta-based impressions and conversions. We will also define window specification which will be used by the following dense_rank() statement. The window and rank define our attribution logic.
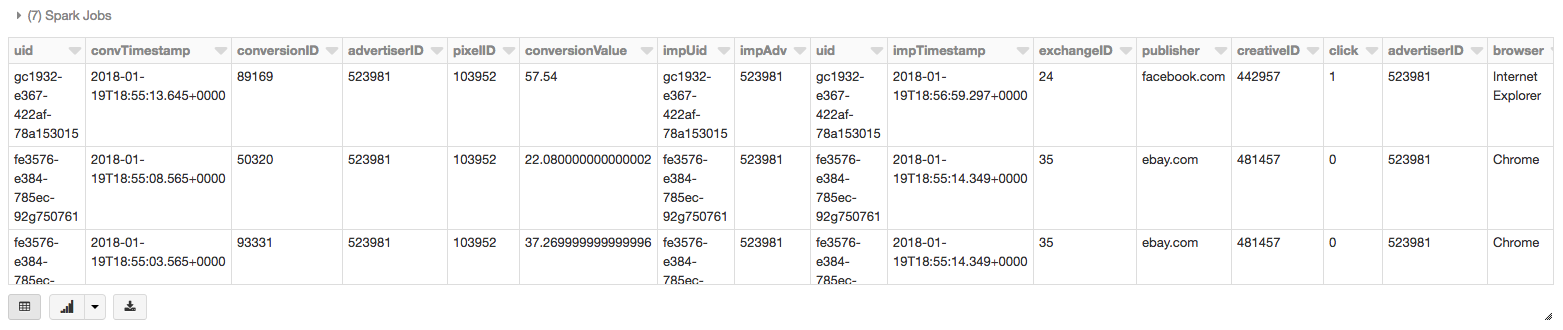
As well, you can plug in your favorite BI tool such as Tableau to perform ad-hoc analysis of your data.
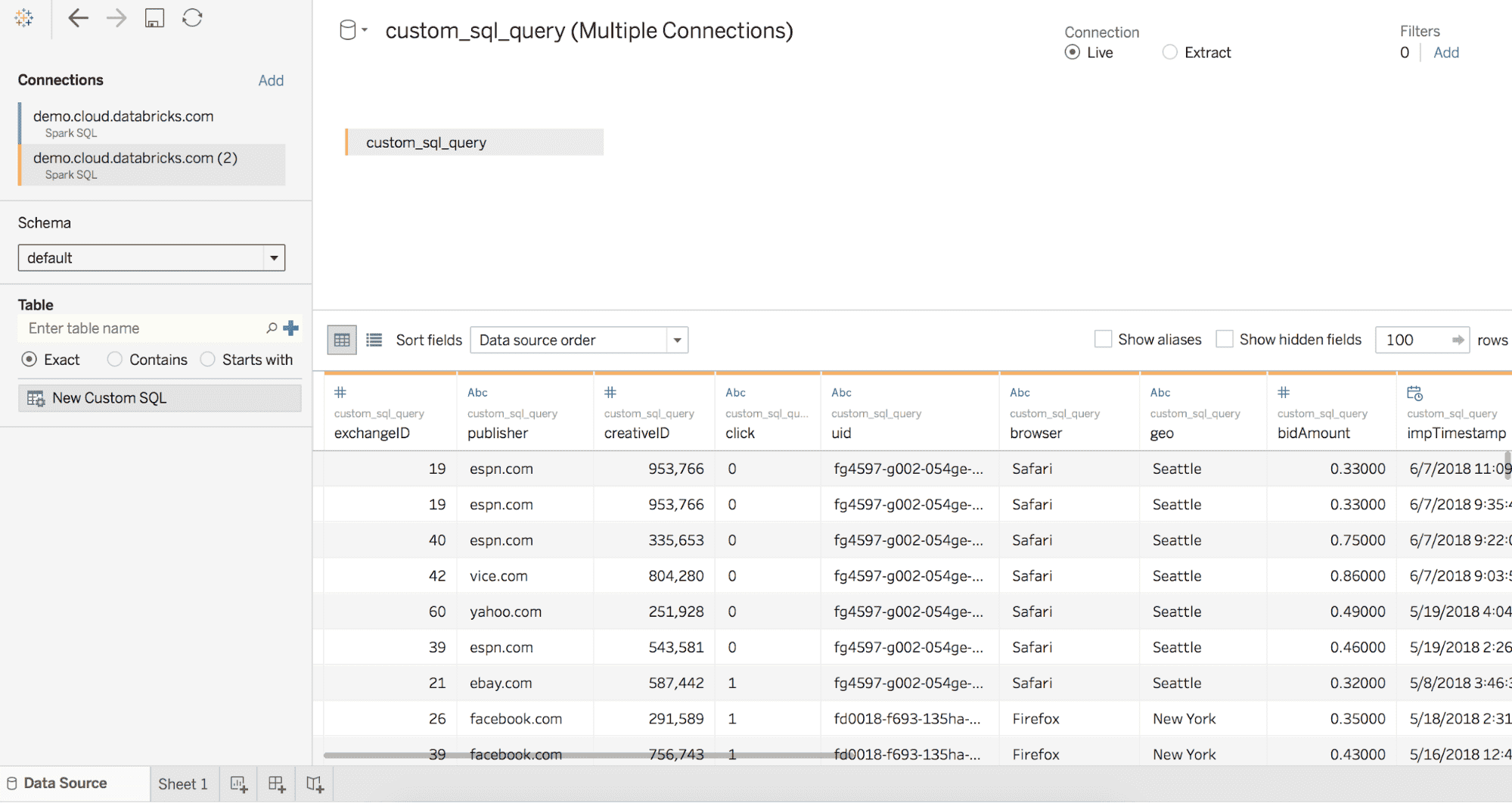
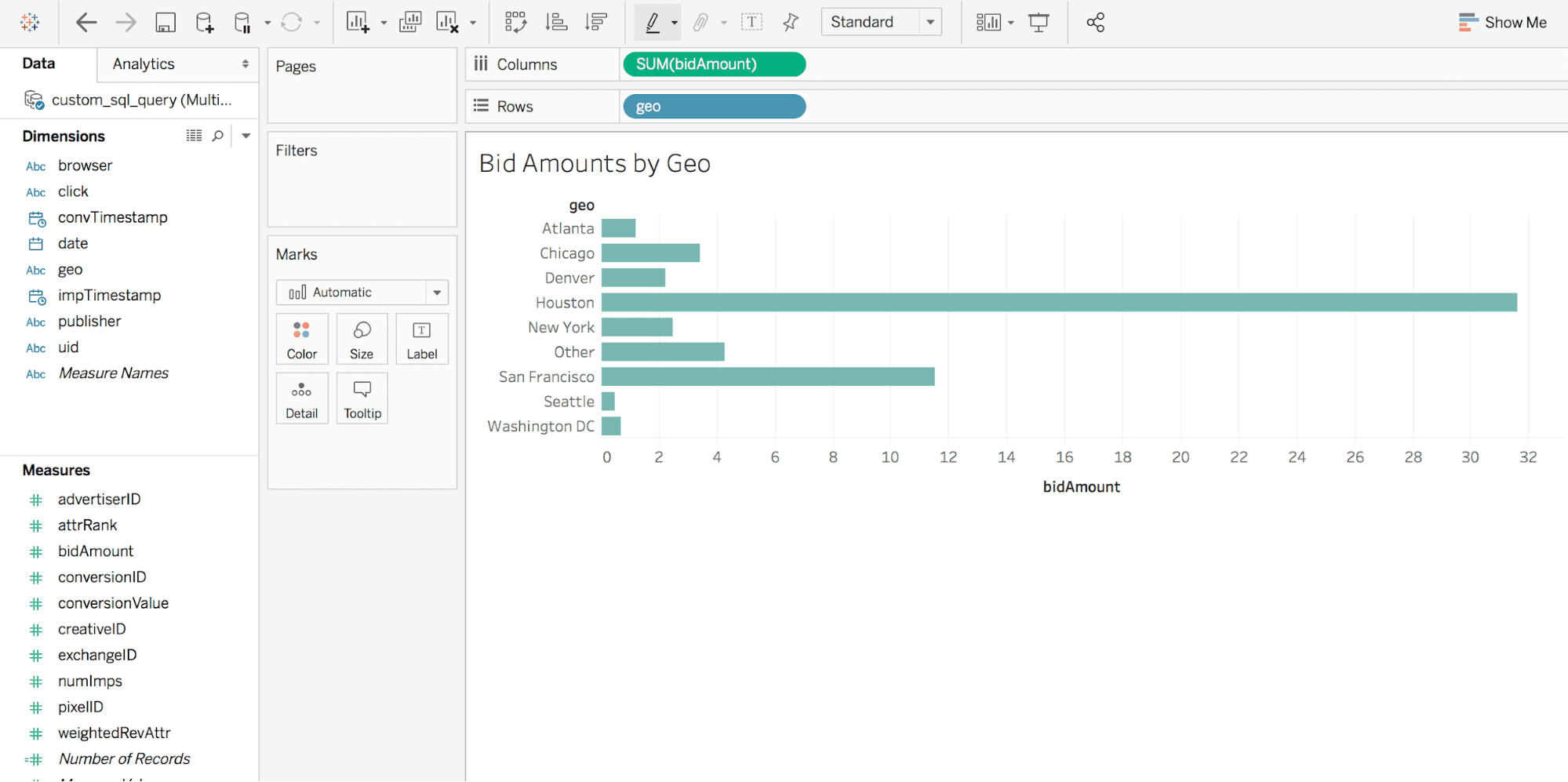
Calculate Weighted Attribution on View
In the preceding case, we demonstrate a very naive model — isolating all of a user’s impressions prior to conversion, selecting the most recent, and attributing only the most recent impression prior to conversion. A more sophisticated model might apply attribution windows or weight the impressions by time such as the code snippet below.
Discussion
In this blog, we have reviewed how Databricks Delta provides a simplified solution for a real-time attribution pipeline. The advantages of using Databricks Delta to sync and save your data streams include (but not limited to) the ability to:
- Save and persist your real-time streaming data like a data warehouse because Databricks Delta maintains a transaction log that efficiently tracks changes to the table.
- Yet still, have the ability to run your queries and perform your calculations in real-time and completing in seconds
- With Databricks Delta, you can have multiple writers can simultaneously modify a dataset and still see consistent views.
- Writers can modify a dataset without interfering with jobs reading the dataset.
- An important optimization is that Databricks Delta avoids the “many small file” problem typical of many big data projects because it features automatic file management that organizes data into large files so that they can be read efficiently.
- Statistics enable speeding up reads by 10-100x and data skipping avoids reading irrelevant information.
Together with your streaming framework and the Databricks Unified Analytics Platform, you can quickly build and use your real-time attribution pipeline with Databricks Delta to solve your complex display advertising problems in real-time.
Visit the Delta Lake online hub to learn more, download the latest code and join the Delta Lake community.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.