Detecting Financial Fraud at Scale with Decision Trees and MLflow on Databricks
by Elena Boiarskaia, Navin Albert and Denny Lee
Try this notebook in Databricks
Detecting fraudulent patterns at scale using artificial intelligence is a challenge, no matter the use case. The massive amounts of historical data to sift through, the complexity of the constantly evolving machine learning and deep learning techniques, and the very small number of actual examples of fraudulent behavior are comparable to finding a needle in a haystack while not knowing what the needle looks like. In the financial services industry, the added concerns with security and the importance of explaining how fraudulent behavior was identified further increases the complexity of the task.

To build these detection patterns, a team of domain experts comes up with a set of rules based on how fraudsters typically behave. A workflow may include a subject matter expert in the financial fraud detection space putting together a set of requirements for a particular behavior. A data scientist may then take a subsample of the available data and select a set of deep learning or machine learning algorithms using these requirements and possibly some known fraud cases. To put the pattern in production, a data engineer may convert the resulting model to a set of rules with thresholds, often implemented using SQL.
This approach allows the financial institution to present a clear set of characteristics that led to the identification of a fraudulent transaction that is compliant with the General Data Protection Regulation (GDPR). However, this approach also poses numerous difficulties. The implementation of a fraud detection system using a hardcoded set of rules is very brittle. Any changes to the fraud patterns would take a very long time to update. This, in turn, makes it difficult to keep up with and adapt to the shift in fraudulent activities that are happening in the current marketplace.
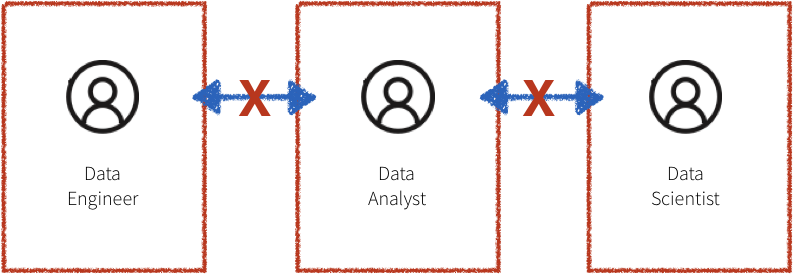
Additionally, the systems in the workflow described above are often siloed, with the domain experts, data scientists, and data engineers all compartmentalized. The data engineer is responsible for maintaining massive amounts of data and translating the work of the domain experts and data scientists into production level code. Due to a lack of common platform, the domain experts and data scientists have to rely on sampled down data that fits on a single machine for analysis. This leads to difficulty in communication and ultimately a lack of collaboration.
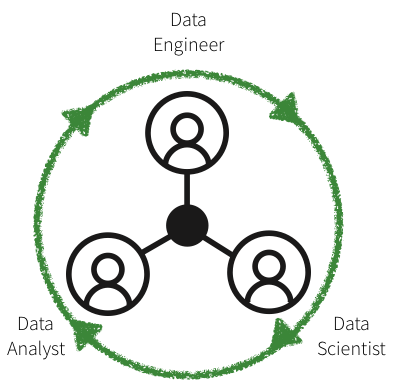
In this blog, we will showcase how to convert several such rule-based detection use cases to machine learning use cases on the Databricks platform, unifying the key players in fraud detection: domain experts, data scientists, and data engineers. We will learn how to create a machine learning fraud detection data pipeline and visualize the data in real-time leveraging a framework for building modular features from large data sets. We will also learn how to detect fraud using decision trees and Apache Spark MLlib. We will then use MLflow to iterate and refine the model to improve its accuracy.
Solving with Machine Learning
There is a certain degree of reluctance with regard to machine learning models in the financial world as they are believed to offer a "black box" solution with no way of justifying the identified fraudulent cases. GDPR requirements, as well as financial regulations, make it seemingly impossible to leverage the power of data science. However, several successful use cases have shown that applying machine learning to detect fraud at scale can solve a host of the issues mentioned above.
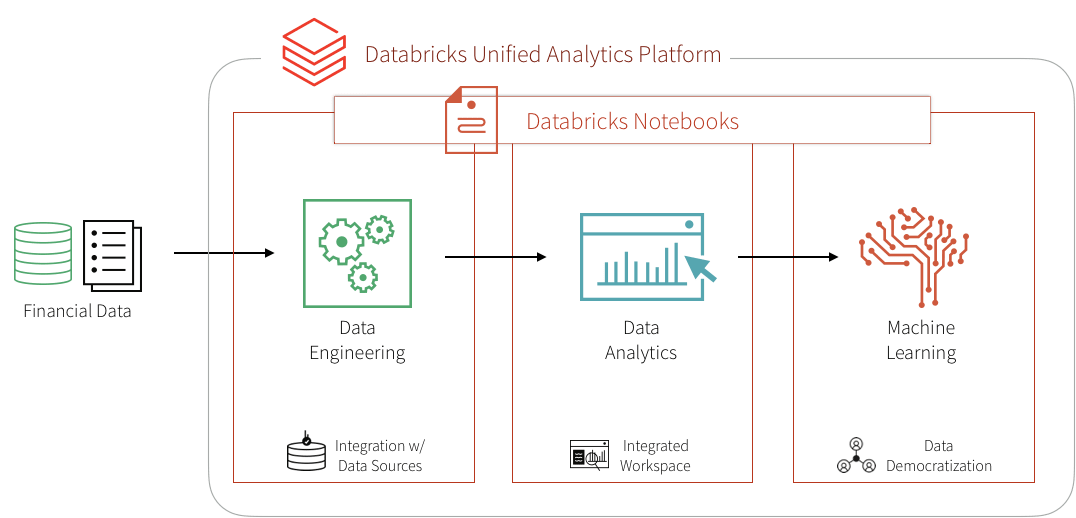
Training a supervised machine learning model to detect financial fraud is very difficult due to the low number of actual confirmed examples of fraudulent behavior. However, the presence of a known set of rules that identify a particular type of fraud can help create a set of synthetic labels and an initial set of features. The output of the detection pattern that has been developed by the domain experts in the field has likely gone through the appropriate approval process to be put in production. It produces the expected fraudulent behavior flags and may, therefore, be used as a starting point to train a machine learning model. This simultaneously mitigates three concerns:
- The lack of training labels,
- The decision of what features to use,
- Having an appropriate benchmark for the model.
Training a machine learning model to recognize the rule-based fraudulent behavior flags offers a direct comparison with the expected output via a confusion matrix. Provided that the results closely match the rule-based detection pattern, this approach helps gain confidence in machine learning based fraud prevention with the skeptics. The output of this model is very easy to interpret and may serve as a baseline discussion of the expected false negatives and false positives when compared to the original detection pattern.
Furthermore, the concern with machine learning models being difficult to interpret may be further assuaged if a decision tree model is used as the initial machine learning model. Because the model is being trained to a set of rules, the decision tree is likely to outperform any other machine learning model. The additional benefit is, of course, the utmost transparency of the model, which will essentially show the decision-making process for fraud, but without human intervention and the need to hard code any rules or thresholds. Of course, it must be understood that the future iterations of the model may utilize a different algorithm altogether to achieve maximum accuracy. The transparency of the model is ultimately achieved by understanding the features that went into the algorithm. Having interpretable features will yield interpretable and defensible model results.
The biggest benefit of the machine learning approach is that after the initial modeling effort, future iterations are modular and updating the set of labels, features, or model type is very easy and seamless, reducing the time to production. This is further facilitated on the Databricks Unified Analytics Platform where the domain experts, data scientists, data engineers may work off the same data set at scale and collaborate directly in the notebook environment. So let's get started!
Ingesting and Exploring the Data
We will use a synthetic dataset for this example. To load the dataset yourself, please download it to your local machine from Kaggle and then import the data via Import Data - Azure and AWS
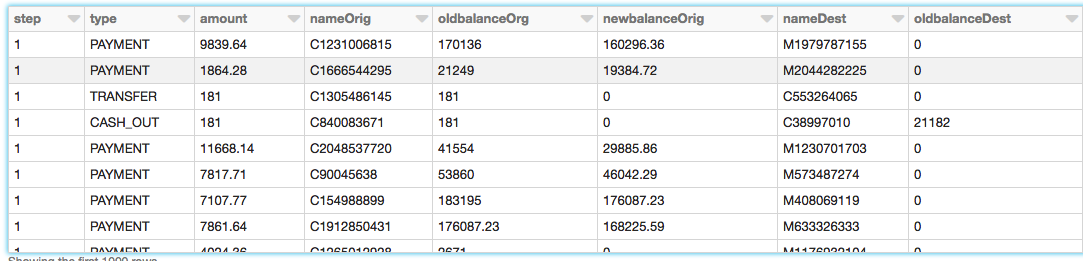
The PaySim data simulates mobile money transactions based on a sample of real transactions extracted from one month of financial logs from a mobile money service implemented in an African country. The below table shows the information that the data set provides:
Exploring the Data
Creating the DataFrames - Now that we have uploaded the data to Databricks File System (DBFS), we can quickly and easily create DataFrames using Spark SQL
Now that we have created the DataFrame, let's take a look at the schema and the first thousand rows to review the data.
Types of Transactions
Let's visualize the data to understand the types of transactions the data captures and their contribution to the overall transaction volume.
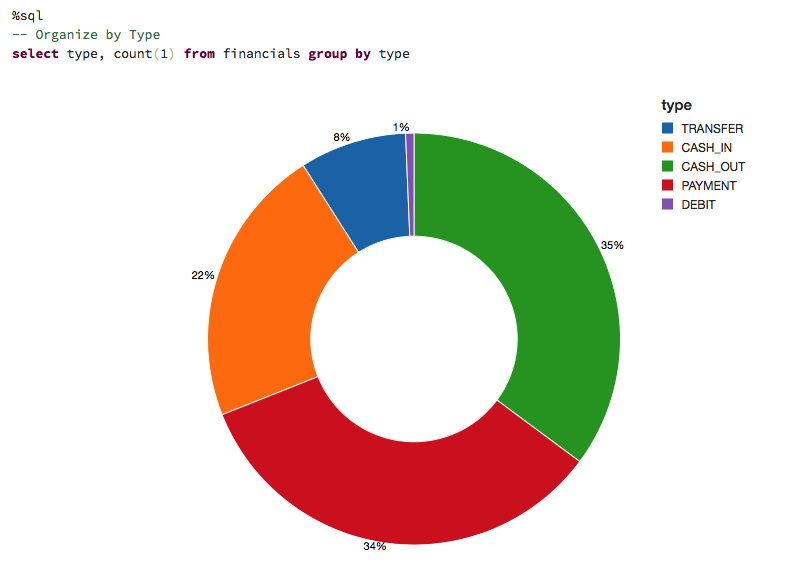
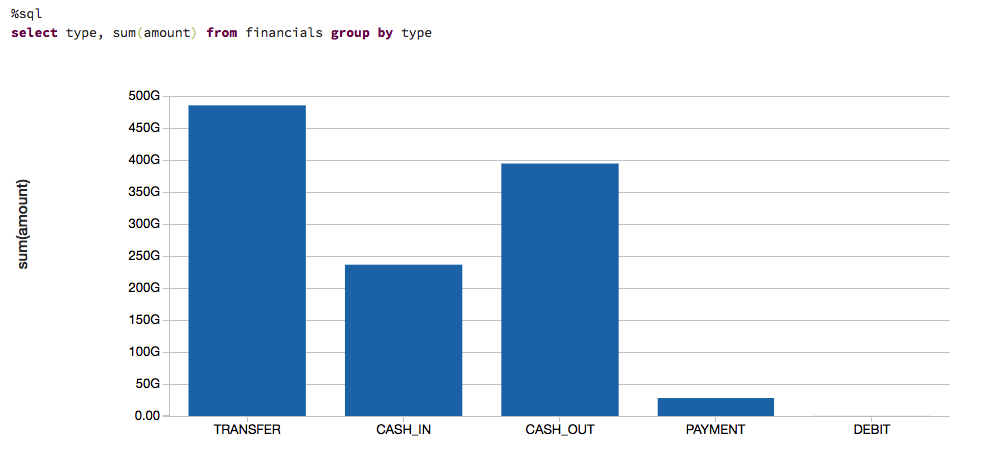
To get an idea of how much money we are talking about, let's also visualize the data based on the types of transactions and on their contribution to the amount of cash transferred (i.e. sum(amount)).
Rules-based Model
We are not likely to start with a large data set of known fraud cases to train our model. In most practical applications, fraudulent detection patterns are identified by a set of rules established by the domain experts. Here, we create a column called label based on these rules.
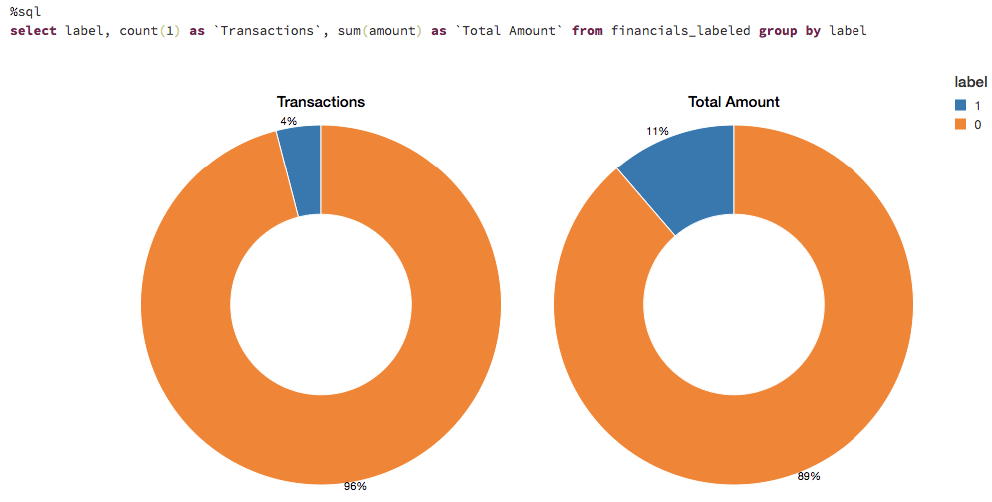
Visualizing Data Flagged by Rules
These rules often flag quite a large number of fraudulent cases. Let's visualize the number of flagged transactions. We can see that the rules flag about 4% of the cases and 11% of the total dollar amount as fraudulent.
Selecting the Appropriate Machine Learning Models
In many cases, a black box approach to fraud detection cannot be used. First, the domain experts need to be able to understand why a transaction was identified as fraudulent. Then, if action is to be taken, the evidence has to be presented in court. The decision tree is an easily interpretable model and is a great starting point for this use case.
Creating the Training Set
To build and validate our ML model, we will do an 80/20 split using .randomSplit. This will set aside a randomly chosen 80% of the data for training and the remaining 20% to validate the results.
Creating the ML Model Pipeline
To prepare the data for the model, we must first convert categorical variables to numeric using .StringIndexer. We then must assemble all of the features we would like for the model to use. We create a pipeline to contain these feature preparation steps in addition to the decision tree model so that we may repeat these steps on different data sets. Note that we fit the pipeline to our training data first and will then use it to transform our test data in a later step.
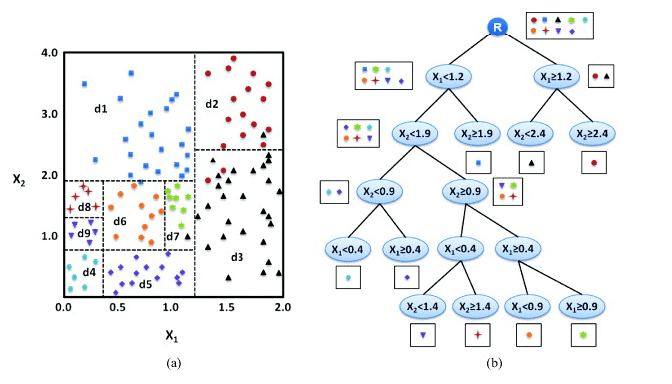
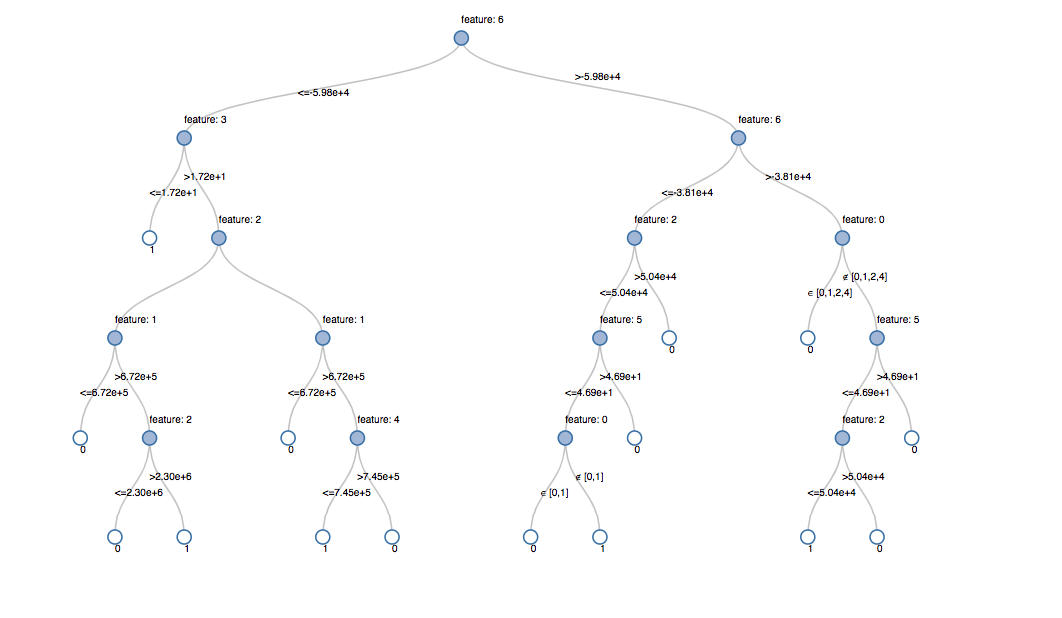
Visualizing the Model
Calling display() on the last stage of the pipeline, which is the decision tree model, allows us to view the initial fitted model with the chosen decisions at each node. This helps to understand how the algorithm arrived at the resulting predictions.
Model Tuning
To ensure we have the best fitting tree model, we will cross-validate the model with several parameter variations. Given that our data consists of 96% negative and 4% positive cases, we will use the Precision-Recall (PR) evaluation metric to account for the unbalanced distribution.
Model Performance
We evaluate the model by comparing the Precision-Recall (PR) and Area under the ROC curve (AUC) metrics for the training and test sets. Both PR and AUC appear to be very high.
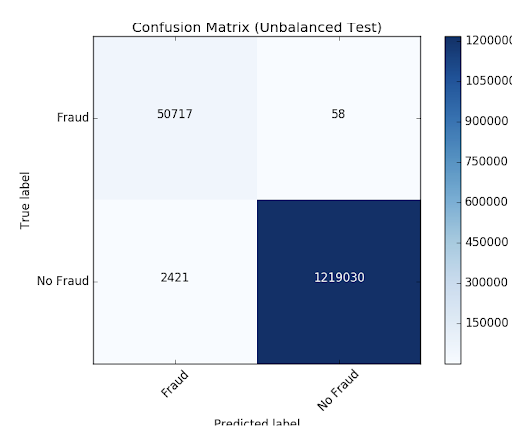
To see how the model misclassified the results, let's use matplotlib and pandas to visualize our confusion matrix.
Balancing the Classes
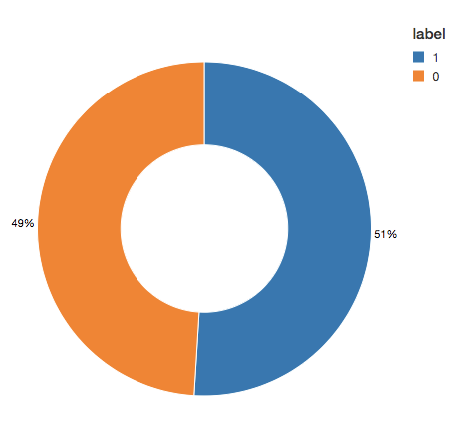
We see that the model is identifying 2421 more cases than the original rules identified. This is not as alarming as detecting more potential fraudulent cases could be a good thing. However, there are 58 cases that were not detected by the algorithm but were originally identified. We are going to attempt to improve our prediction further by balancing our classes using undersampling. That is, we will keep all the fraud cases and then downsample the non-fraud cases to match that number to get a balanced data set. When we visualized our new data set, we see that the yes and no cases are 50/50.
Updating the Pipeline
Now let's update the ML pipeline and create a new cross validator. Because we are using ML pipelines, we only need to update it with the new dataset and we can quickly repeat the same pipeline steps.
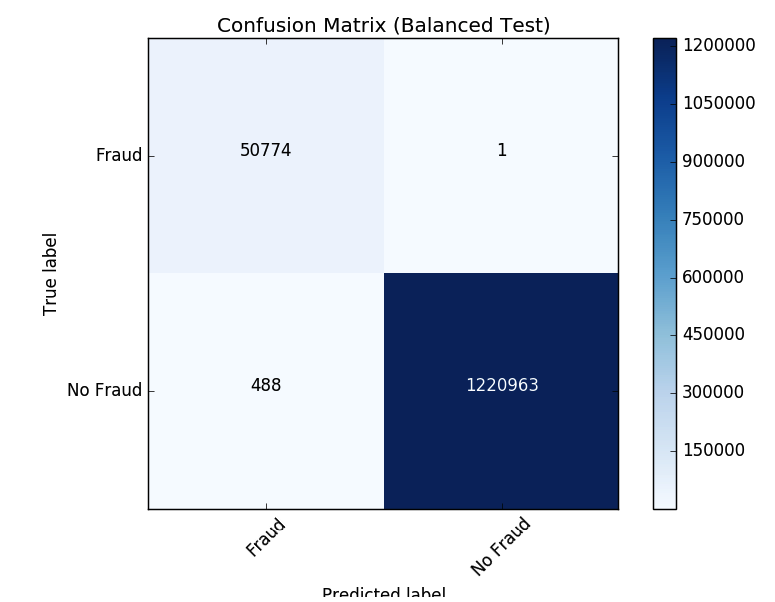
Review the Results
Now let's look at the results of our new confusion matrix. The model misidentified only one fraudulent case. Balancing the classes seems to have improved the model.
Model Feedback and Using MLflow
Once a model is chosen for production, we want to continuously collect feedback to ensure that the model is still identifying the behavior of interest. Since we are starting with a rule-based label, we want to supply future models with verified true labels based on human feedback. This stage is crucial for maintaining confidence and trust in the machine learning process. Since analysts are not able to review every single case, we want to ensure we are presenting them with carefully chosen cases to validate the model output. For example, predictions, where the model has low certainty, are good candidates for analysts to review. The addition of this type of feedback will ensure the models will continue to improve and evolve with the changing landscape.
MLflow helps us throughout this cycle as we train different model versions. We can keep track of our experiments, comparing the results of different model configurations and parameters. For example here, we can compare the PR and AUC of the models trained on balanced and unbalanced data sets using the MLflow UI. Data scientists can use MLflow to keep track of the various model metrics and any additional visualizations and artifacts to help make the decision of which model should be deployed in production. The data engineers will then be able to easily retrieve the chosen model along with the library versions used for training as a .jar file to be deployed on new data in production. Thus, the collaboration between the domain experts who review the model results, the data scientists who update the models, and the data engineers who deploy the models in production, will be strengthened throughout this iterative process.
https://www.youtube.com/watch?v=x_4S9r-Kks8
https://www.youtube.com/watch?v=BVISypymHzw
Conclusion
We have reviewed an example of how to use a rule-based fraud detection label and convert it to a machine learning model using Databricks with MLflow. This approach allows us to build a scalable, modular solution that will help us keep up with ever-changing fraudulent behavior patterns. Building a machine learning model to identify fraud allows us to create a feedback loop that allows the model to evolve and identify new potential fraudulent patterns. We have seen how a decision tree model, in particular, is a great starting point to introduce machine learning to a fraud detection program due to its interpretability and excellent accuracy.
A major benefit of using the Databricks platform for this effort is that it allows for data scientists, engineers, and business users to seamlessly work together throughout the process. Preparing the data, building models, sharing the results, and putting the models into production can now happen on the same platform, allowing for unprecedented collaboration. This approach builds trust across the previously siloed teams, leading to an effective and dynamic fraud detection program.
Try this notebook by signing up for a free trial in just a few minutes and get started creating your own models.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.