How Tilting Point Does Streaming Ingestion into Delta Lake
by Diego Link and Vini Jaiswal
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
Diego Link is VP of Engineering at Tilting Point
Tilting Point is a new-generation games partner that provides top development studios with expert resources, services, and operational support to optimize high quality live games for success. Through its user acquisition fund and its world-class technology platform, Tilting Point funds and runs performance marketing management and live games operations to help developers achieve profitable scale.
At Tilting Point, we were running daily / hourly batch jobs for reporting on game analytics. We wanted to make our reporting near real-time and make sure that we get insights in 5 to 10 mins. We also wanted to make our in-game live-ops decisions based on real-time player behavior for giving real time data to a bundles and offer system, provide up-to-the-minute alerting on LiveOPs changes that actually might have unforeseen detrimental effects and even alert on service interruptions in game operations. Additionally, we had to store encrypted Personally Identifiable Information (PII) data separately for GDPR purposes.
How data flows and associated challenges
We have a proprietary SDK that developers integrate with to send data from game servers to an ingest server hosted in AWS. This service removes all PII data and then sends the raw data to an Amazon Firehose endpoint. Firehose then dumps the data in JSON format continuously to S3.
To clean up the raw data and make it available quickly for analytics, we considered pushing the continuous data from Firehose to a message bus (e.g. Kafka, Kinesis) and then use Apache Spark’s Structured Streaming to continuously process data and write to Delta Lake tables. While that architecture sounds ideal for low latency requirements of processing data in seconds, we didn’t have such low latency needs for our ingestion pipeline. We wanted to make the data available for analytics in a few minutes, not seconds. Hence we decided to simplify our architecture by eliminating a message bus and instead using S3 as a continuous source for our structured streaming job. But the key challenge in using S3 as a continuous source is identifying files that changed recently.
Listing all files every few minutes has 2 major issues:
- Higher latency: Listing all files in a directory with a large number of files has high overhead and increases processing time.
- Higher cost: Listing lot of files every few minutes can quickly add to the S3 cost.
Leveraging Structured Streaming with Blob Store as Source and Delta Lake Tables as Sink
To continuously stream data from cloud blob storage like S3, we use Databricks’ S3-SQS source. The S3-SQS source provides an easy way for us to incrementally stream data from S3 without the need to write any state management code on what files were recently processed. This is how our ingestion pipeline looks:
- Configure Amazon S3 event notifications to send new file arrival information to SQS via SNS.
- We use the S3-SQS source to read the new data arriving in S3. The S3-SQS source reads the new file names that arrived in S3 from SQS and uses that information to read the actual file contents in S3. An example code below:
- Our structured streaming job then cleans up and transforms the data. Based on the game data, the streaming job uses the foreachBatch API of Spark streaming and writes to 30 different Delta Lake tables.
- The streaming job produces lot of small files. This affects performance of downstream consumers. So, an optimize job runs daily to compact small files in the table and store them as right file sizes so that consumers of the data have good performance while reading the data from Delta Lake tables. We also run a weekly optimize job for a second round of compaction.
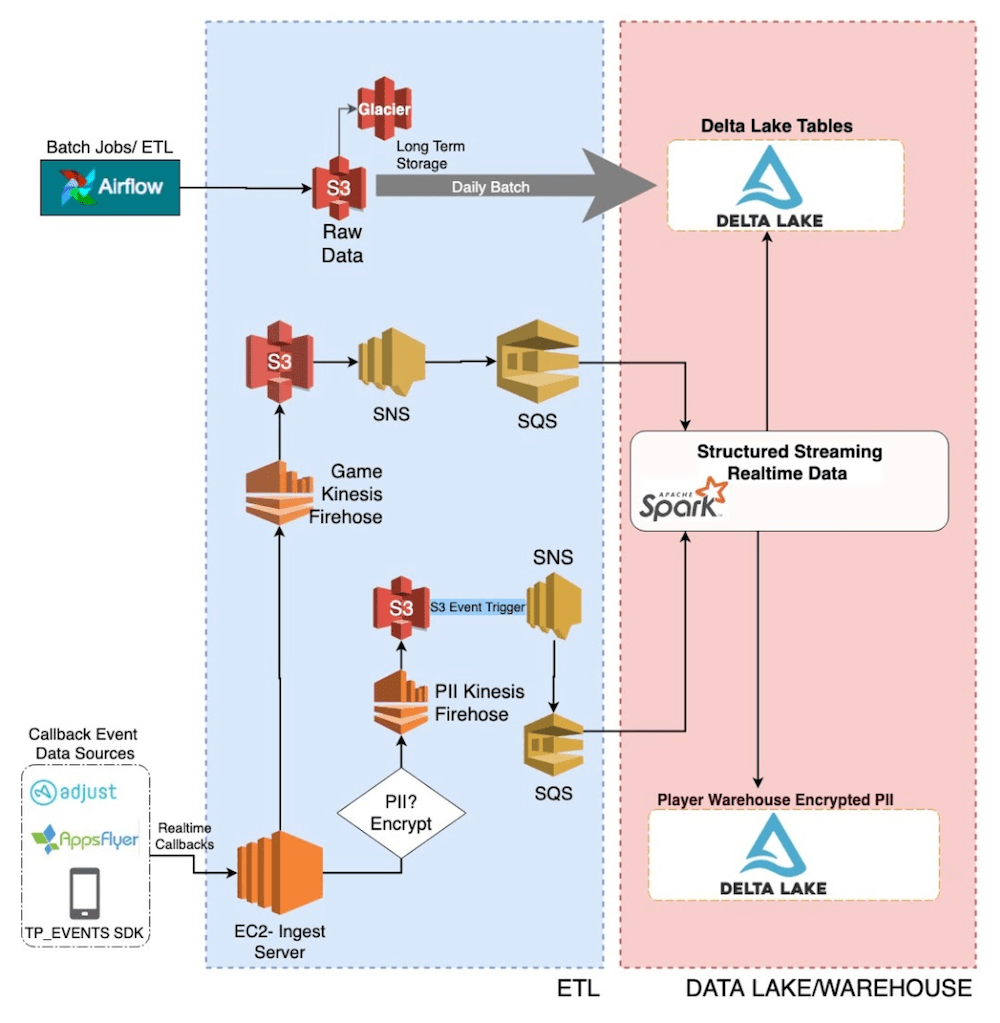
The above Delta Lake ingestion architecture helps in the following ways:
- Incremental loading: The S3-SQS source incrementally loads the new files in S3. This helps quickly process the new files without too much overhead in listing files.
- No explicit file state management: There is no explicit file state management needed to look for recent files.
- Lower operational burden: Since we use S3 as a checkpoint between Firehose and structured streaming jobs, the operational burden to stop streams and re-process data is relatively low.
- Reliable ingestion: Delta Lake uses optimistic concurrency control to offer ACID transactional guarantees. This helps with reliable data ingestion.
- File compaction: One of the major problems with streaming ingestion is tables ending up with a large number of small files that can affect read performance. Before Delta Lake, we had to setup a different table to write the compacted data. With Delta Lake, thanks to ACID transactions, we can compact the files and rewrite the data back to the same table safely.
- Snapshot isolation: Delta Lake’s snapshot isolation allows us to expose the ingestion tables to downstream consumers while data is being appended by a streaming job and modified during compaction.
- Rollbacks: In case of bad writes, Delta Lake's Time Travel helps us rollback to a previous version of the table.
Conclusion
In this blog, we walked through our use cases and how we do streaming ingestion using Databricks’ S3-SQS source into Delta Lake tables efficiently without too much operational overhead to make good quality data readily available for analytics.
Visit the Delta Lake online hub to learn more, download the latest code and join the Delta Lake community.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.