Announcing the MLflow 1.1 Release
by Max Allen, Andrew Chen, Apurva Koti, Clemens Mewald, Matei Zaharia and Corey Zumar
We’re excited to announce today the release of MLflow 1.1. In this release, we’ve focused on fleshing out the tracking component of MLflow and improving visualization components in the UI.
Some of the major features include:
- Automatic logging from TensorFlow and Keras
- Parallel coordinate plots in the tracking UI
- Pandas DataFrame based search API
- Java Fluent API
- Kubernetes execution backend for MLflow projects
- Search Pagination
A full list of all the features can be found in the change log. You can find MLflow 1.1 on PyPI, Maven, and CRAN. Check out the documentation and provide feedback on GitHub.
What’s New in MLflow 1.1
Autologging from TensorFlow and Keras
MLflow 1.1 provides lightweight autologging of metrics, parameters, and models from your TensorFlow and Keras model training runs - call mlflow.tensorflow.autolog() or
mlflow.keras.autolog() for the framework you’re using. Autologging eliminates the need for manual metric and parameter log statements and provides out-of-the-box model tracking without any modification to training code.
Here is an example using Keras’ IMDB sentiment classification example:
We can then view the auto-logged metrics in the MLflow UI:
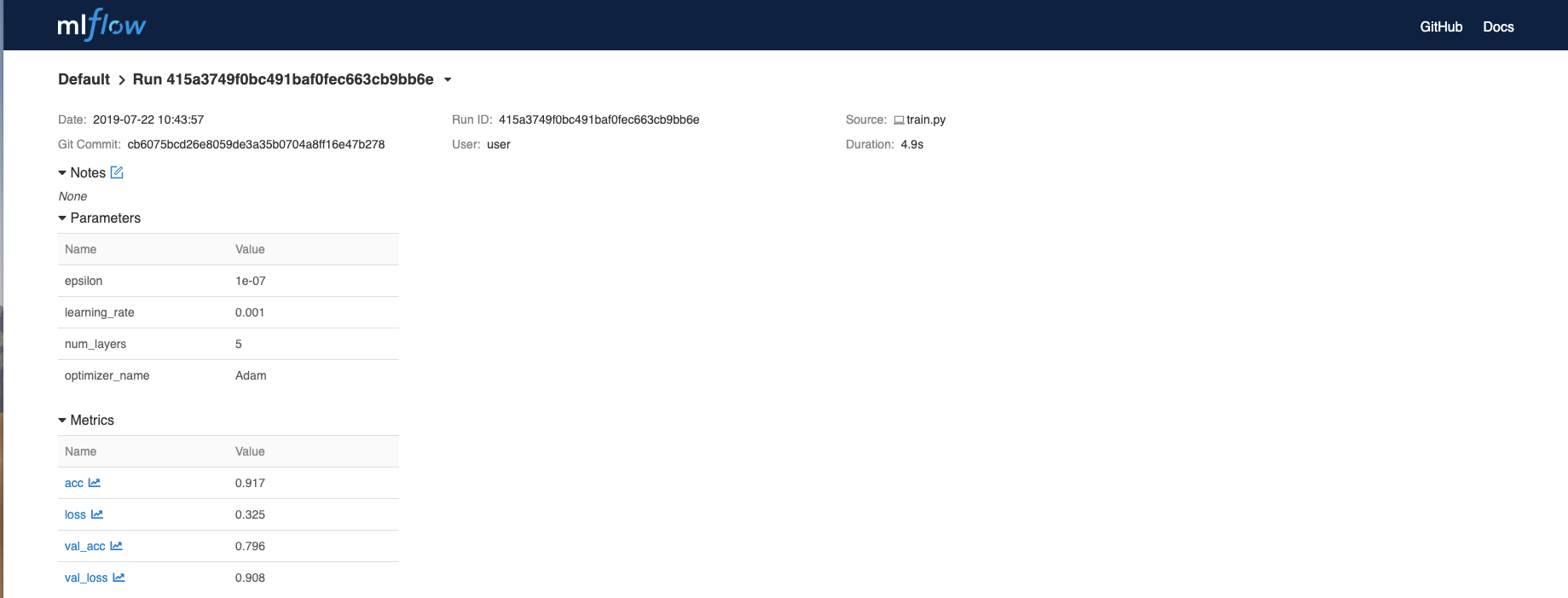
You can also view example usages with Keras and TensorFlow in the MLflow GitHub repository.
Parallel coordinates plot
Visualizing relationships in an n-dimensional space is especially important for applications in machine learning. When comparing MLflow runs, you’d like to understand how a different set of hyperparameters will affect model evaluation metrics such as validation loss. To achieve this, we’ve added support to display a parallel coordinates plot when comparing different MLflow runs.
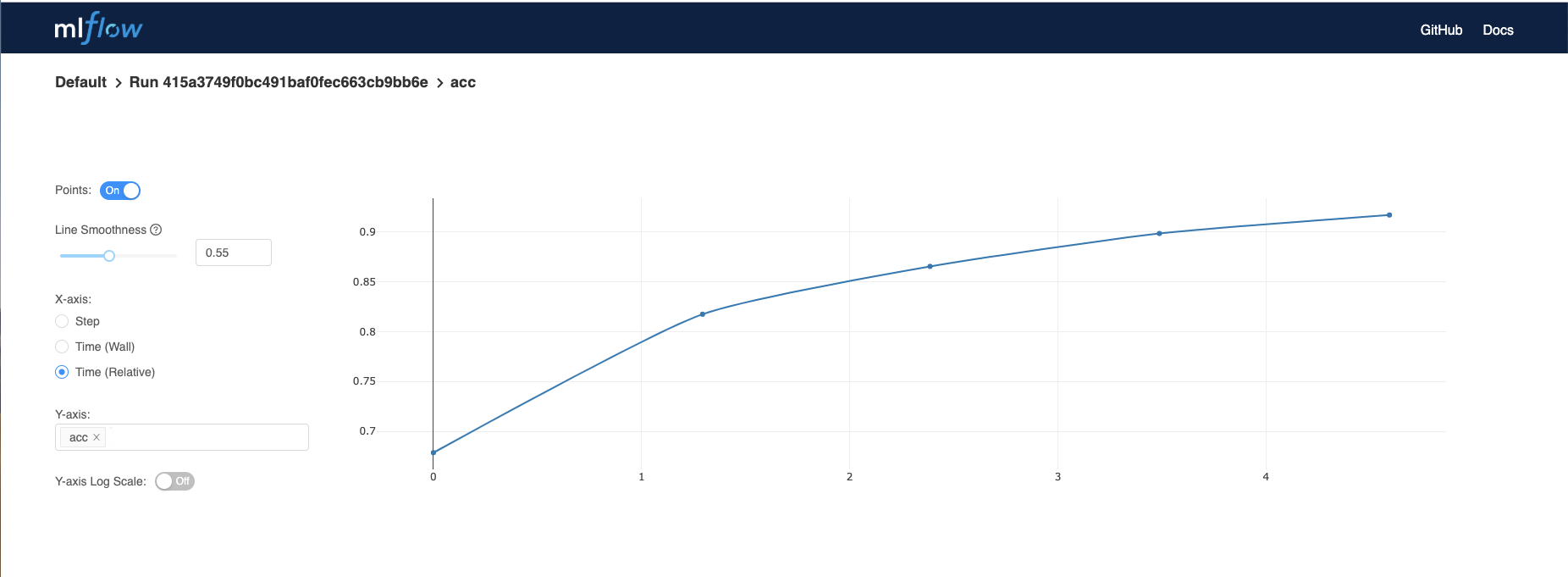
Here is an example with data autologged from TensorFlow’s Iris example:
https://www.youtube.com/watch?v=pBr7jlXjqHs
For this example, we can see that using only 2 layers gives a consistently high accuracy. With 3 or 4 layers, accuracy decreases because we are likely overfitting the model to the training data.
Pandas DataFrame based search API
Comparing and searching through runs within an experiment is very important when deciding which models should move forward to testing and deployment. While you can use the MLflow UI to search and compare runs, this becomes difficult as the number of runs gets large. This is why we’ve implemented a new search_runs API in the MLflow Python client that returns experiment runs in a pandas DataFrame. This way, you can use pandas and other plotting libraries to programmatically analyze your runs.
The DataFrame contains run_id, experiment_id, status, and artifact_uri. It also will contain the metrics, parameters, and tags for each run. For example:
| run_id | experiment_id | metrics.foo | params.param1 | ... | tags.mlflow.source.git.commit | tags.mlflow.user |
| a3edc64fd9a042f2a8d4816be92555d5 | 0 | 2.84 | 39 | 2ef523a6f5b60f971df261274fe2bc1cc809ca0f | john |
Java Fluent API
The Java Fluent API provides a higher level interface to creating and logging to MLflow runs. This API is in contrast to the lower level MlflowClient API which is essentially a wrapper over the REST APIs. The example below shows a simple use of the new API to create and log to a new run.
Kubernetes Execution Backend for Projects
With MLflow 1.1, you can now run MLflow Projects on Kubernetes clusters. Any MLflow Project with a Docker Environment is supported. MLflow executes your Project code as a Kubernetes Job and periodically monitors its status until completion. You can select a target Kubernetes cluster and Docker registry for your Project run using a simple backend configuration file. For more information, please check out the new feature documentation and the updated example on GitHub. We would like to thank @marcusrehm for contributing this exciting new feature!
Search Pagination
In order to make MLflow scale to experiments with thousands of runs, we’ve changed the search API and UI to use a paginated interface.
https://www.youtube.com/watch?v=5J5Q7xEsG-g
Other Features and Updates
We’ve highlighted out a small portion of the features released in MLflow 1.1 above. We welcome more input on mlflow-users@googlegroups.com or by filing issues or submitting patches on GitHub. For usage questions about MLflow, we have a MLflow tag on Stack Overflow. You can follow @MLflow on Twitter as well.
What’s Next After 1.1
Moving beyond the 1.1 release, the next major feature we are currently working on is the MLflow Model Registry, which will allow you to manage the lifecycle of your model from experimentation to deployment and monitoring. We announced this along with other MLflow roadmap updates at the Spark AI Summit Keynote on MLflow last April.
Coming up, we’re also excited to have Spark AI Summit Europe from October 15th to 17th. At the summit we’ll have a training session dedicated to MLflow and model deployment. Early bird registration ends on August 16th 2019.
Finally, we’ll also have a webinar on August 1st on Productionizing Machine Learning with Clemens Mewald, product manager for MLflow and Joel Thomas, senior solutions architect.
Read More
To get started with MLflow on your laptop or on Databricks you can:
- Read the quickstart guide
- Work through the tutorial
- Try Managed MLflow on Databricks
Credits
We want to thank the following contributors for updates, doc changes, and contributions in MLflow 1.1: Avinash Raghuthu, Aaron Davidson, Akshaya Annavajhala, Amrit Baveja, Andrew Chen, Andrew Crozier, Ankit Mathur, Henning, Javier Luraschi, Liza Shakury, Marcus Rehm, Matei Zaharia, Max Allen, Nicolas Laille, Richard Zang, Sid Murching, Siddharth Murching, Stephanie Bodoff, Sue Ann Hong, Taur1ne, Uwe L. Korn, ahutterTA, Apurva Koti, Corey Zumar, kafendt, lennon310, nathansuh, Tomas Nykodym
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.