Scalable Near Real-Time S3 Access Logging Analytics with Apache Spark™ and Delta Lake
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
The original blog is from Viacheslav Inozemtsev, Senior Data Engineer at Zalando, reproduced with permission.
Introduction
Many organizations use AWS S3 as their main storage infrastructure for their data. Moreover, by using Apache Spark™ on Databricks they often perform transformations of that data and save the refined results back to S3 for further analysis. When the size of data and the amount of processing reach a certain scale, it often becomes necessary to observe the data access patterns. Common questions that arise include (but are not limited to): Which datasets are used the most? What is the ratio between accessing new and past data? How quickly a dataset can be moved to a cheaper storage class without affecting the performance of the users? Etc.
In Zalando, we have faced this issue since data and computation became a commodity for us in the last few years. Almost all of our ~200 engineering teams regularly perform analytics, reporting, or machine learning meaning they all read data from the central data lake. The main motivation to enable observability over this data was to reduce the cost of storage and processing by deleting unused data and by shrinking resource usage of the pipelines that produce that data. An additional driver was to understand if our engineering teams needed to query historical data or if they are only interested in the recent state of the data.
To answer these types of questions S3 provides a useful feature - S3 Server Access Logging. When enabled, it constantly dumps logs about every read and write access in the observed bucket. The problem that appears almost immediately, and especially at a higher scale, is that these logs are in the form of comparatively small text files, with a format similar to the logs of Apache Web Server.
To query these logs we have leveraged capabilities of Apache Spark™ Structured Streaming on Databricks and built a streaming pipeline that constructs Delta Lake tables. These tables - for each observed bucket - contain well-structured data of the S3 Access Logs, they are partitioned, can be sorted if needed, and, as a result, enable extended and efficient analysis of the access patterns of the company’s data. This allows us to answer the previously mentioned questions and many more. In this blog post we are going to describe the production architecture we designed in Zalando, and to show in detail how you can deploy such a pipeline yourself.
Solution
Before we start, let us make two qualifications.
The first note is about why we chose Delta Lake, and not plain Parquet or any other format. As you will see, to solve the problem described we are going to create a continuous application using Spark Structured Streaming. The properties of the Delta Lake, in this case, will give us the following benefits:
- ACID Transactions: No corrupted/inconsistent reads by the consumers of the table in case write operation is still in progress or has failed leaving partial results on S3. More information is also available in Diving into Delta Lake: Unpacking the Transaction Log.
- Schema Enforcement: The metadata is controlled by the table; there is no chance that we break the schema if there is a bug in the code of the Spark job or if the format of the logs has changed. More information is available in Diving Into Delta Lake: Schema Enforcement & Evolution.
- Schema Evolution: On the other hand, if there is a change in the log format - we can purposely extend the schema by adding new fields. More information is available in Diving Into Delta Lake: Schema Enforcement & Evolution.
- Open Format: All the benefits of the plain Parquet format for readers apply, e.g. predicate push-down, column projection, etc.
- Unified Batch and Streaming Source and Sink: Opportunity to chain downstream Spark Structured Streaming jobs to produce aggregations based on the new content
The second note is about the datasets that are being read by the clients of our data lake. For the most part, the mentioned datasets consist of 2 categories: 1) snapshots of the data warehouse tables from the BI databases, and 2) continuously appended streams of events from the central event bus of the company. This means that there are 2 types of patterns of how data gets written in the first place - full snapshot once per day and continuously appended stream, respectively.
In both cases we have a hypothesis that the data generated in the last day is consumed most often. For the snapshots we also know of infrequent comparisons between the current snapshot and past versions, for example one from a year ago. We are aware of the use case when the whole month or even year of historical data for a certain stream of event data has to be processed. This gives us an idea of what to look for, and this is where the described pipeline should help us to prove or disprove our hypotheses.
Let us now dive into the technical details of the implementation of this pipeline. The only entity we have at the current stage is the S3 bucket. Our goal is to analyze what patterns appear in the read and write access to this bucket.
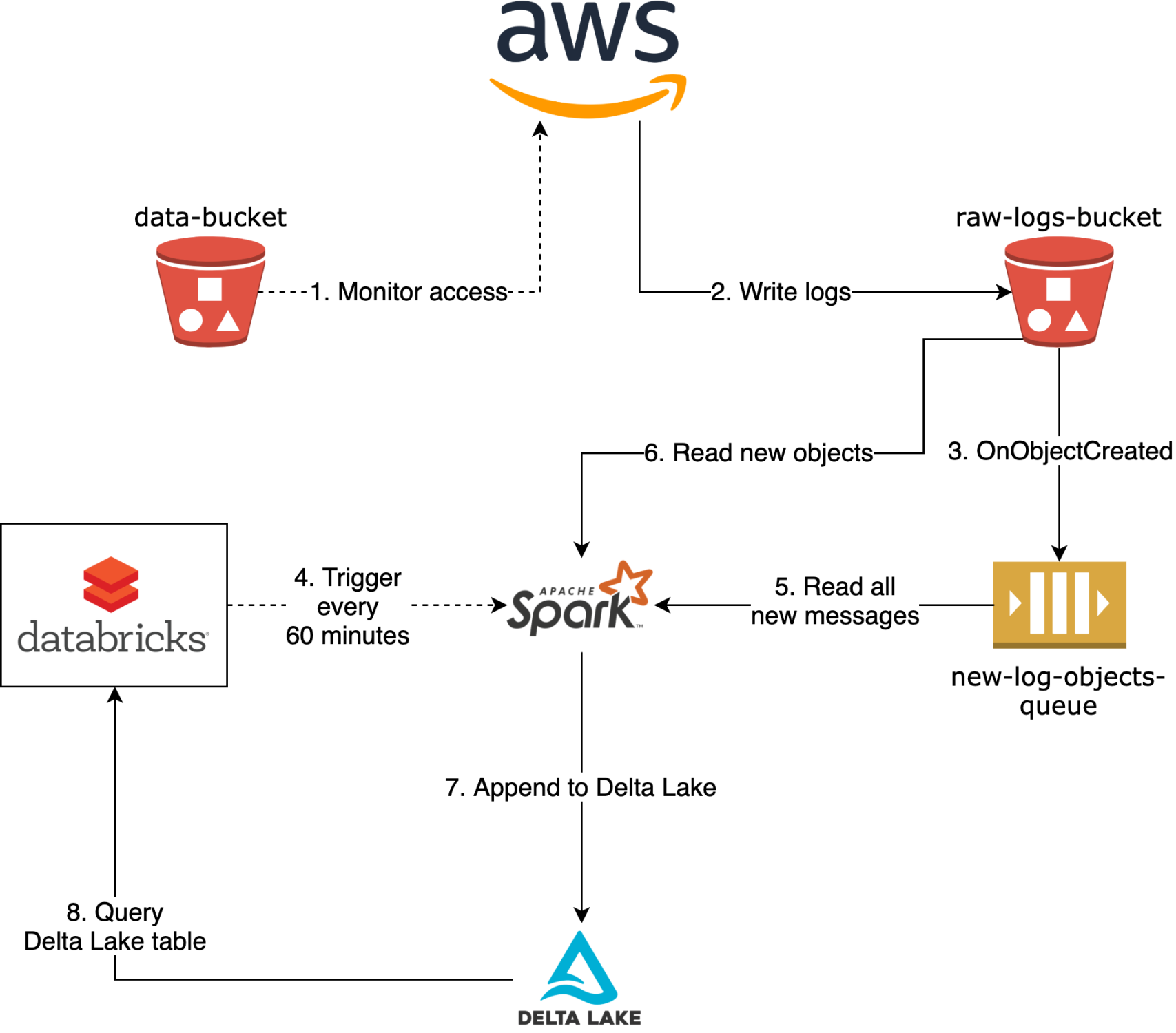
To give you an idea of what we are going to show, on the diagram below you can see the final architecture, that represents the final state of the pipeline. The flow it depicts is the following:
- AWS constantly monitors the S3 bucket data-bucket
- It writes raw text logs to the target S3 bucket raw-logs-bucket
- For every created object an Event Notification is sent to the SQS queue new-log-objects-queue
- Once every hour a Spark job gets started by Databricks
- Spark job reads all the new messages from the queue
- Spark job reads all the objects (described in the messages from the queue) from raw-logs-bucket
- Spark job writes the new data in append mode to the Delta Lake table in the delta-logs-bucket S3 bucket (optionally also executes OPTIMIZE and VACUUM, or runs in the Auto-Optimize mode)
- This Delta Lake table can be queried for the analysis of the access patterns
Administrative Setup
First we will perform the administrative setup of configuring our S3 Server Access Logging and creating an SQS Queue.
Configure S3 Server Access Logging
First of all you need to configure S3 Server Access Logging for the data-bucket. To store the raw logs you first need to create an additional bucket - let’s call it raw-logs-bucket. Then you can configure logging via UI or using API. Let’s assume that we specify target prefix as data-bucket-logs/, so that we can use this bucket for S3 access logs of multiple data buckets.
After this is done - raw logs will start appearing in the raw-logs-bucket as soon as someone is doing requests to the data-bucket. The number and the size of the objects with logs will depend on the intensity of requests. We experienced three different patterns for three different buckets as noted in the table below.
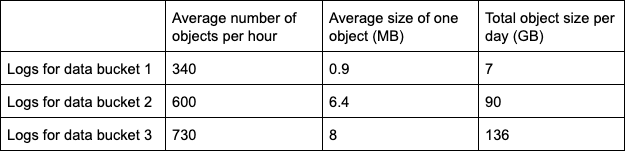
You can see that the velocity of data can be rather different, which means you have to account for this when processing these disparate sources of data.
Create an SQS queue
Now, when logs are being created, you can start thinking about how to read them with Spark to produce the desired Delta Lake table. Because S3 logs are written in the append-only mode - only new objects get created, and no object ever gets modified or deleted - this is a perfect case to leverage the S3-SQS Spark reader created by Databricks. To use it, you need first of all to create an SQS queue. We recommend to set Message Retention Period to 7 days, and Default Visibility Timeout to 5 minutes. From our experience, these are good defaults, that as well match defaults of the Spark S3-SQS reader. Let’s refer to the queue with the name new-log-objects-queue.
Now you need to configure the policy of the queue to allow sending messages to the queue from the raw-logs-bucket. To achieve this you can edit it directly in the Permissions tab of the queue in the UI, or do it via API. This is how the statement should look like:
Configure S3 event notification
Now, you are ready to connect raw-logs-bucket and new-log-objects-queue, so that for each new object there is a message sent to the queue. To achieve this you can configure the S3 Event Notification in the UI or via API. We show here how the JSON version of this configuration would look like:
Operational Setup
In this section, we will perform the necessary cluster configurations including creating IAM roles and prepare the cluster configuration.
Create IAM roles
To be able to run the Spark job, you need to create two IAM roles - one for the job (cluster role), and one to access S3 (assumed role). The reason you need to additionally assume a separate S3 role is that the cluster and its cluster role are located in the dedicated AWS account for Databricks EC2 instances and roles, whereas the raw-logs-bucket is located in the AWS account where the original source bucket resides. And because every log object is written by the Amazon role - there is an implication that cluster role doesn’t have permission to read any of the logs in accordance to the ACL of the log objects. You can read more about it in Secure Access to S3 Buckets Across Accounts Using IAM Roles with an AssumeRole Policy.
The cluster role, referred here as cluster-role, should be created in the AWS account dedicated for Databricks, and should have these 2 policies:
and
You will also need to add the instance profile of this role as usual to the Databricks platform.
The role to access S3, referred here as s3-access-role-to-assume, should be created in the same account, where both buckets reside. It should refer to the cluster-role by its ARN in the assumed_by parameter, and should have these 2 policies:
and
where delta-logs-bucket is another bucket you need to create, where the resulting Delta Lake tables will be located.
Prepare cluster configuration
Here we outline the spark_conf settings that are necessary in the cluster configuration so that the job can run correctly:
If you go for more than one bucket, we also recommend these settings to enable FAIR scheduler, external shuffling, and RocksDB for keeping state:
Generate Delta Lake table with a Continuous Application
In the previous sections you completed the perfunctory administrative and operational setups. Now that this is done, you can write the code that will finally produce the desired Delta Lake table, and run it in a Continuous Application mode.
The notebook
The code is written in Scala. First we define a record case class:

Then we create a few helper functions for parsing:



And finally we define the Spark job: 
Create Databricks job
The last step is to make the whole pipeline run. For this you need to create a Databricks job. You can use the “New Automated Cluster” type, add spark_conf we defined above, and schedule it to be run, for example, once every hour using “Schedule” section. This is it - as soon as you confirm creation of the job, and when it starts running by scheduler - you should be able to see that messages from the SQS queue are getting consumed, and that the job is writing to the output Delta Lake table.
Execute Notebook Queries
At this point data is available, and you can create your notebook and execute your queries to answer questions we started with in the beginning of this blog post.
Create interactive cluster and a notebook to run analytics
As soon as Delta Lake table has the data - you can start querying it. For this you can create a permanent cluster with the role that only needs to be able to read the delta-logs-bucket. This means it doesn’t need to use the AssumeRole technique, but only need ListBucket and GetObject permissions. After that you can attach a notebook to this cluster and execute your first analysis.
Queries to analyze access patterns
Let’s get back to one of the questions that we asked in the beginning - which datasets are used the most? If we assume that in the source bucket every dataset is located under prefix data/{DATASET_NAME}/, then to answer it, we could come up with a query like this one:
The outcome of the query can look like this:
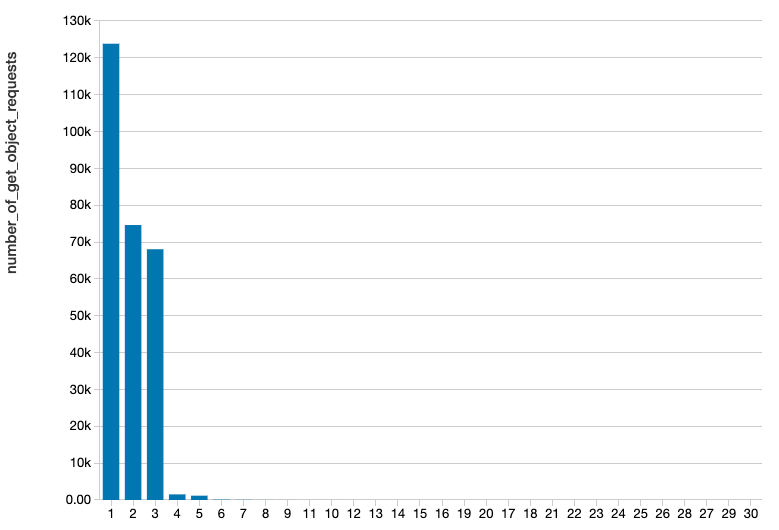
This query tells us how many individual GetObject requests were made to each dataset during one day, ordered from the top most accessed down to the less intensively accessed. By itself it might not be enough to say, if one dataset is accessed more often. We can normalize each aggregation by the number of objects in each dataset. Also, we can group by dataset and day, so that we also see the correlation in time. There are many further options, but the point is that having at hand this Delta Lake table we can answer any kind of question about what access patterns in the bucket.
Extensibility
The pipeline we have shown is extensible out of the box. You can fully reuse the same SQS queue and add more buckets with logging into the pipeline, by simply using the same raw-logs-bucket to store S3 Server Access Logs. Because the Spark job already partitions by date and bucket, it will keep working fine, and your Delta Lake table will contain log data from the new buckets.
One piece of advice we can give is to use AWS CDK to handle infrastructure, i.e. to configure the buckets raw-logs-bucket and delta-logs-bucket, SQS queue, and the role s3-access-role-to-assume. This will simplify operations and make the infrastructure become code as well.
Conclusion
In this blog post we have described how S3 Server Access Logging can be transformed into Delta Lake in a continuous fashion, so that analysis of the access patterns to the data can be performed. We showed that Spark Structured Streaming together with the S3-SQS reader can be used to read raw logging data. We described what kind of IAM policies and spark_conf parameters you will need to make this pipeline work. Overall, this solution is easy to deploy and operate, and it can give you a good benefit by providing observability over the access to the data.
Related links
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.