Celebrating Growth at Databricks and 1,000 Employees!

This November, Databricks hired our 1,000th full-time employee! Founded in Berkeley in 2013, our six co-founders created Databricks to help data teams solve the world’s toughest problems - and since then, we’ve grown tremendously! Not only have we had some major milestones like our Microsoft partnership, resulting in Azure Databricks and the creation of new open source projects like Delta Lake and MLflow, but we have also expanded our employee count and global presence. We now have offices across the world, including London, Amsterdam, Singapore, New York and our headquarters in SF! We are so excited for what’s to come and owe a big thank you to our employees, partners, and customers who have been on this journey with us.
How did we reach 1,000 employees?
At Databricks, we recognize that hiring a new member for our team is a great example of how our employees embody one of our core values "Teamwork makes the dream work!” Providing an excellent candidate experience requires the coordination and collaboration of many teams. With the help of our awesome teammates, Databricks has been able to scale quickly and effectively.
Take a look at all the teams that go into helping a new hire have a great experience!
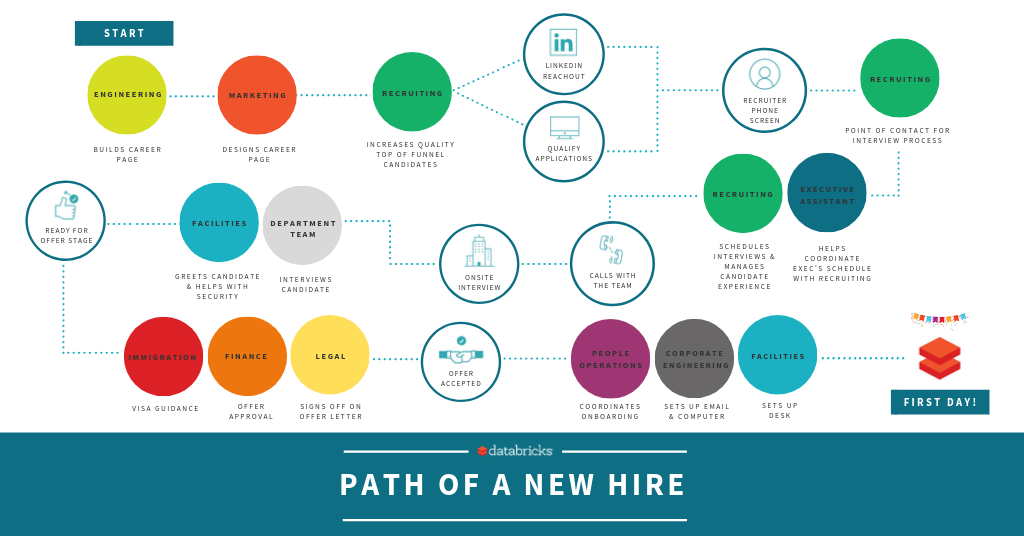
The path a candidate takes to become a new Brickster
How has our company changed from our first year in 2013?
We asked our employees to talk about the biggest changes and growth that they’ve noticed at Databricks from the year that they first started to now, both in the role they play here and the company itself. Learn from their perspective below!
2013: Meet Michael Armbrust, Principal Software Engineer
 |
Michael was one of the first engineers hired at Databricks and is a frequent speaker at Spark+AI Summit. He is a committer and PMC member of Apache Spark and the original creator of Spark SQL. He currently leads the team at Databricks that designed and built Structured Streaming and Delta Lake. |
Before Databricks, I was a post-doc at Google doing research on building composable optimizers as part of the F1 team. When I joined Databricks, I was really excited to get to put many of the ideas we came up with during that project into production. This lead to the catalyst optimizer that powers Spark SQL today. Even though I studied Databases in grad school, I had never built a "real" one before, and being able to create something like that from scratch at my first job was an amazing opportunity. It was also really gratifying to see hundreds of global contributors from the Apache® Spark community help grow the engine after we released it as open source. Working with such a vibrant community was a big change from working on it on my own for a year.
More recently I got the opportunity to open-source another really cool piece of technology, called “Delta”. Delta started as this proprietary product, that was inspired by a conversation I had with a potential customer at Data + AI Summit. He was at a large Fortune 100 company, and he wanted to ingest petabytes of data per week into a massive data lake that could be queried in real time by analysts around the world. I knew that a workload like that would overload Spark's metadata management layer. However, this challenge sparked the idea of creating a scalable transaction log. It was cool to see how many different factors contributed to the start of Delta Lake: the Spark Community, Spark Summit, our sales team, leadership (including our CEO Ali) and the awesome members of the "streamteam" at Databricks. We worked really closely with the customer and in around six months we had gone from an idea to actually running in production! Before long, we decided to share this technology with the world, and earlier this year the Delta Lake open source project was born. While this project is still young, I'm really excited with the momentum so far, and I can't wait to see where it goes!
2014: Meet Tim Hunter, Technical Lead, Jobs Team
 |
Tim started off at Databricks as a Software Engineer on the Machine Learning Team. He did his Ph.D. in the AMPLab, the UC Berkeley lab that created Apache Spark. As part of his research, he wrote Machine Learning algorithms using Spark 0.0.2. Wanting to learn more about the impact of our product, he transferred over to become a Solutions Architect in London, and recently moved to Amsterdam to lead our Jobs Team. |
When I started at Databricks, there were 15 employees cramped in tiny office right down the hill from UC Berkeley. Back then, a lot of our work was groundbreaking and done in a semi-stealth session. It was finally unveiled during the first Spark Summit, in what we used to call the "Mother of all demos". My early work was to make Spark much easier to use with a service called the "chauffeur", that connects data science to clusters - so people could point and click and not have to worry about the details behind the scenes. After the first two years, I worked on the ML team, with a focus on deep learning, deployment and AI efforts inside Databricks. This is where I looked at how we could add and scale more intricate functions of machine learning like DBUs, image processing, geospatial processing, and graph processing.
One thing that I enjoy about engineering at Databricks is that you’re not just writing code, you’re also thinking globally about how to present your work to users and getting feedback on it. If you also enjoy speaking, like I do, there are a lot of opportunities to give presentations about your work, especially at Meetups or Spark Summit. Since I wanted to understand how the ML system I was building was being used, I asked to do a rotation as a Solutions Architect in our London office. The excitement and the small team reminded me of the original small startup form a few years ago - except that it had the full backing of the U.S. team and a proven, very successful product to sell. There, I helped large European companies put together some ML/AI solutions on top of Databricks in a wide variety of industries such as car manufacturing, drug processing, and chemical processing. After this rotation, I moved to our Amsterdam office to be the Tech Lead of our newly formed Jobs team. It is amazing to see that the service maintained by the jobs team, which sprouted out as a quick hackathon project a few years ago, has developed into an industrial strength system that is pretty much used by every Databricks user! The flexibility that Databricks has given me to explore different offices and roles within the company has really helped me grow as an engineer, and allowed me to see the different areas of growth that we have gone through in our product.
2015: Meet Jen Aman, Senior Event Manager
 |
Jen started off as a Marketing Manager and helped Databricks launch our third Spark Summit when it was still only being held in the United States. She is now a Senior Event Manager, and plans and develops the strategy for large scale global events for Databricks, including our annual Spark + AI Summit (Americas and Europe) and company retreat. |
I started two weeks before our third Spark Summit, which at the time was only being held in both San Francisco (around 2,000 attendees) and the east coast (around 1,400 attendees). We decided that year that it would be a good time to launch Spark Summit Europe for the first time in Amsterdam. This year, we held our 5th Spark Summit in Europe - which sold out! We eventually decided to only have the Americas Summit in San Francisco and moved from hosting it in hotel ballrooms at the Hilton to Moscone Center (one of the largest convention centers in SF), where we now have around 5,000 attendees. My first year, my core responsibility was to figure out booth duty schedule for everybody. Having started only two weeks before, I had no idea who anyone was and had to look at their pictures to figure out names. Eventually, I took on more responsibility for Summit: owning the agenda process, call for papers (community to submit talks), the marketing and execution of these talks, managing speaker attendance, keynote process, swag, catering, space planning and managing the creative.
The content of our Spark + AI Summit conference has also expanded, outside of just additional keynotes and tracks running at the same time. We now have vertical events - health and life sciences and FinTech, as well as networking events, meetups, tutorials, lightning talks and an advisory bar for questions on Apache Spark™ and Databricks. It’s also been a huge change managing our internal attendance - we only had 54 Databricks employees during the 3rd Spark Summit and in 2019’s Summit, we had 800+ employees! Our external audience has also expanded from mainly Spark enthusiasts to adding on Databricks customers and partners, data professionals networks, and our Women in Unified Analytics program. Seeing the evolution of Spark Summit, in addition to other internal events I help launch, has made it really rewarding to see the impact and growth of our events!
2016: Meet Shelby Ferson, Geo Enterprise Account Executive
 |
Shelby started off at Databricks as a Mid Market Rep, when the sales team was less than 20 people. She has since been promoted to a Commercial Account Executive, and now is an Enterprise Account Executive, helping evangelize Databricks and communicating its value to customers and system integrators, while also helping build out regions around the world. . |
I had the exciting opportunity to join Databricks when our team was fairly small, our sales team only had less than 20 people globally at that time! Throughout my time here, it has been rewarding to work with customers that are continuously innovating and seeing how our product has been able to support them and their initiatives over these past three years. It’s also refreshing that with our size, I can still walk down to the engineering floor and have technical conversations and learn more about our product, no matter how busy they are. Everyone is willing to help to get customers on board and work as a team to create the best experience for our customers. It’s a great testament that when sales, product, engineering and customer success, work really closely, amazing things happen!
I’ve also been lucky to be closely supported by our sales leadership, who encouraged me to challenge myself and helped accelerate my growth within Databricks. Our executives invest in building a positive sales team culture and have supported initiatives that I’ve worked (along with the team) to help launch, such as our Women of Databricks events and external events like Databricks’ co-sponsored talk with Tableau. This support also extends to when we build out new regions, and how we emphasize the importance of training and embedding our sales culture to our new teammates. Recently, I had the opportunity to help ramp up and support our sales team in our Australia office, and share all the knowledge I had around our product and company. It’s been a once in a lifetime opportunity to be part of the first sales team here, and now getting to see us expanding our sales team to almost 300 people and expanding in regions all over the world!
2017: Meet Yvette Ramirez, Junior Recruiter
 |
Yvette joined Databricks in 2017 as a Recruiting Coordinator in the San Francisco office. After focusing on candidate interviewing and hiring experiences, Yvette supported the Field Engineering, Customer Success, and Professional Services teams as a sourcer for a year. Most recently, she transitioned into a role at the Amsterdam office as a Junior Recruiter to help build the Go-To-Market team in EMEA. |
When I started as a Recruiting Coordinator, there were a little less than 250 employees, and the recruiting team was just 9 people. The size, chaos, and growth of the startup world drives you to be scrappy and create organization from the ambiguity. This was the main reason why I moved from Florida to California, for the opportunity to grow with a company like Databricks that I believed was going to be really successful. After just one year, our team helped to more than double the size of the company, reaching 600+ employees. As the growth continued globally into EMEA and Sydney, the size and complexity of our team’s work followed. I saw this opportunity allowing me to expand my skill set, working with the help of many teammates to jump into the Sourcing role, and mentoring the RCs who came afterward.
My most recent move brought me to Amsterdam as a Jr. Recruiter, helping build out our EMEA Go-To-Market teams. With a smaller European recruiting team, it’s really exciting to again get the chance to help build out our offices that are rapidly growing. An influx of people creates the opportunity for more diverse perspectives, which leads to better systems, processes, and ultimately can transform the way we operate and hire. Diversity has always been a passion of mine, having helped our diversity committee at the early stages of its inception. Through events like Lunch & Learns and Women in Analytics events at Spark Summit, we’ve strived to make Databricks a more inclusive environment. Building on that work, we strive to think on a larger scale on how Databricks can become one of the most diverse and inclusive places out there. It has been amazing to grow alongside Databricks, and I’m so excited to see what else we accomplish globally!
2018: Meet Kunal Taneja, Senior Manager, Field Engineering, APJ
 |
Kunal started off as our first employee in the southern hemisphere as our Sr. Manager of Field Engineering. Within 6 months, he eventually took on building out all of our field engineering teams in APJ. He is now responsible for leading, managing and recruiting a team of field engineers in APJ, who help organizations adopt and use Databricks for driving business value from AI, ML and Unified Analytics. |
I joined Databricks in Sydney around employee 370 and was the first hire for our Asia-Pacific Region (APJ). I was paired up with an account representative who started about a month after me, and we were tasked to help grow out our region and the investment in APJ. We then brought in an SVP General Manager for our region based out of Singapore, the hub for our central functions, with the focus of ramping up hiring and building out APJ. Within the first 6 months, we had hired 8 people, and my manager asked if I wanted to help build out our region of Solutions Architects to keep up with the growth of our account representatives. From there, I was asked to lead and grow the APJ Solutions Architect team.
It’s crazy to think about how when we first started, we had only 2 employees and no office for 7 months. Now, approaching 1 year, we had to move offices twice just because of our growth in Australia, and have team members everywhere in the APJ region! Because we’re a smaller office, I’ve really enjoyed that we get to work so closely together, and hang out outside of work at happy hours, lunches and boat cruises! From a region perspective, we’ve also been growing tremendously in Australia, Japan, and India, where the cloud market is booming. We now have 8 Solutions Architects on board, and next year we are expected to at least double. Databricks has offered such a unique opportunity to work with some of the best people in the industry and I’m so excited to see our presence in APJ continue to expand!
2019: Meet Amy Reichanadter, Chief People Officer
 |
Amy is our Chief People Officer, and joined Databricks with a strong background in creating highly scalable hiring and retention programs, and driving culture, organization development, and total rewards strategies to support the company’s accelerated global expansion. She has some exciting plans for our growth as a company! |
When I joined Databricks in May 2019, I was so excited by the people, market opportunity, growth, and the opportunity to help build an amazing company. As I think about the future of Databricks and what we want to accomplish, my main goal is to create an extraordinary and consistent employee experience. My vision is for all employees, globally, to see Databricks as the most important experience in their career, and as a place where they can bring their best selves to work. Regardless of who they are and where they come from, we want them to feel connected to Databricks, understand our mission and feel empowered to make the company better.
This means that we need to be thoughtful about not only keeping the talent bar high, but also how we can create opportunities for our own teams to grow their career internally as Databricks grows. With doing this, we want to ensure our hiring adds strategic value to the business, and that we evolve the culture and operations in a way that helps us achieve our potential as a company. Our team is really excited about creating extraordinary candidate and employee experiences as we scale, and I’m looking forward to seeing us continue to hire the best talent and build amazing teams around the world!
We are so proud of the team that we have been able to grow with our company and we’re not stopping! Interested? Find your place at Databricks.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.