Using AutoML Toolkit's FamilyRunner Pipeline APIs to Simplify and Automate Loan Default Predictions
Try this Loan Risk with AutoML Pipeline API Notebook in Databricks
Introduction
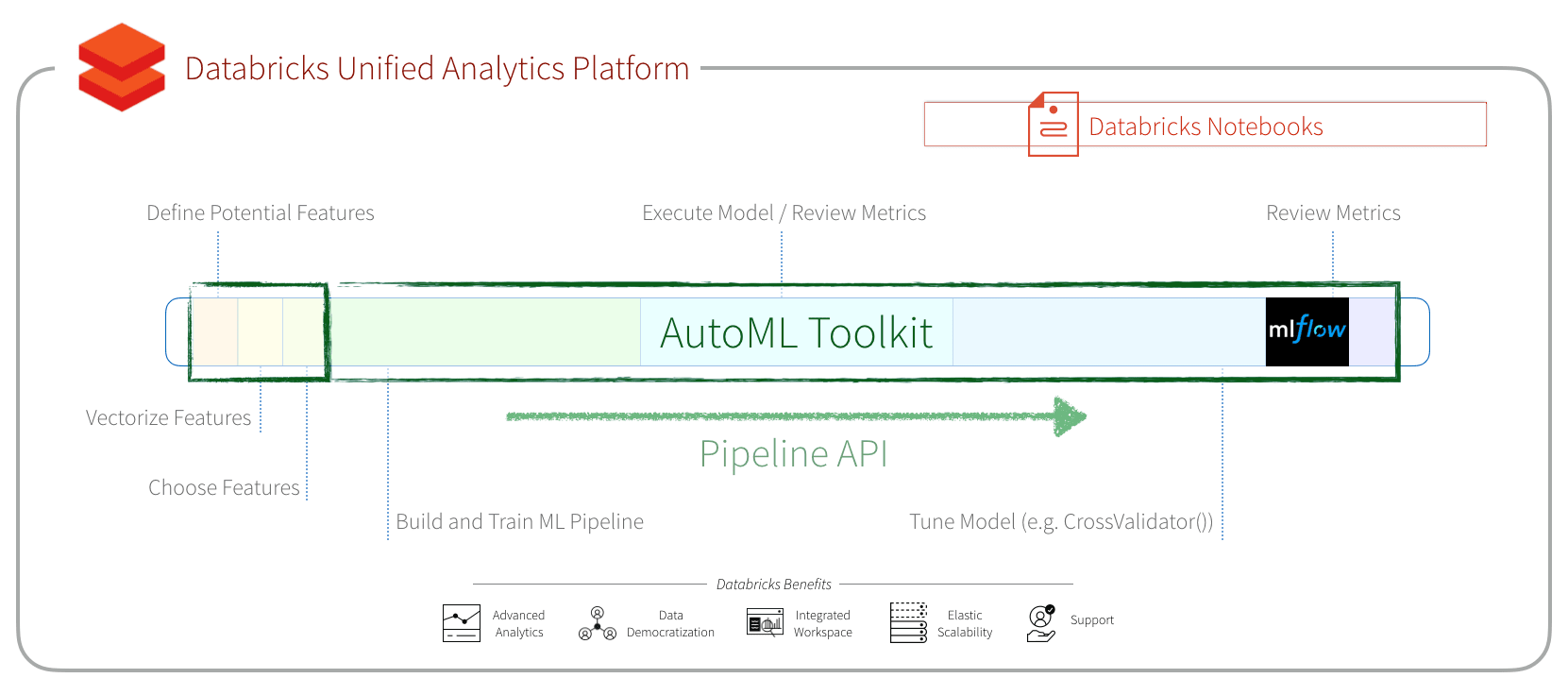
In the post Using AutoML Toolkit to Automate Loan Default Predictions, we had shown how the Databricks Labs’ AutoML Toolkit simplified Machine Learning model feature engineering and model building optimization (MBO). It also had improved the area-under-the-curve (AUC) from 0.6732 (handmade XGBoost model) to 0.723 (AutoML XGBoost model). With AutoML Toolkit’s Release 0.6.1, we have upgraded to MLflow version 1.3.0 and introduced a new Pipeline API that simplifies feature generation and inference.
In this post, we will discuss:
- Family Runner API that allows you to easily try different model families to determine the best model
- Simplify Inference with the Pipeline API
- Simplify Feature Engineering with the Pipeline API
It’s all in the Family...Runner
As noted in the original post Loan Risk Analysis with XGBoost and Databricks Runtime for Machine Learning, we had tried three different model families: GLM, GBT, and XGBoost. Without diving into the details, this comprised hundreds of lines of code for each model type.

As noted in Using AutoML Toolkit to Automate Loan Default Predictions, we had reduced this to a few lines of code for each model type. With AutoML Toolkit FamilyRunner API, we have simplified this further by allowing you to use it to run multiple model types concurrently distributed across the nodes of your Databricks cluster. Below are the three lines of code required to run two models (Logistic Regression and XGBoost).
Within the output cell of this code snippet, you can observe the FamilyRunner API execute multiple tasks, each working to find the best hyperparameters for your selection of model types.
With AutoML Toolkit’s Release 0.6.1, we have upgraded to utilize the latest version of MLflow (1.3.0). The following clip shows the results of this AutoML FamilyRunner experiment logged within MLflow allowing you to compare the results of the logistic regression model (AUC=0.716) and XGBoost (AUC=0.72).
https://www.youtube.com/watch?v=3mgLronGsdI
Simplifying Inference with the Pipeline API
Pipeline APIs on the FamilyRunner allow the functionality of running inference using either an MLflow Run ID or PipelineModel object. These pipelines contain a sequence of stages that are directly built from AutoML’s main configuration. By running inference one of these ways, it ensures that the prediction dataset goes through the identical set of feature engineering steps that are used for the training. This makes for fully-contained, portable and serializable pipelines that can be exported and served for standalone requirements, without the need to manually apply feature engineering tasks. The following code provides a snippet of running an inference.
Using MLflow Run ID
When you are using MLFlow with your AutoML run, you can run inference by simply using MLflow Run ID (and MLflow config) as noted in the code snippet below.
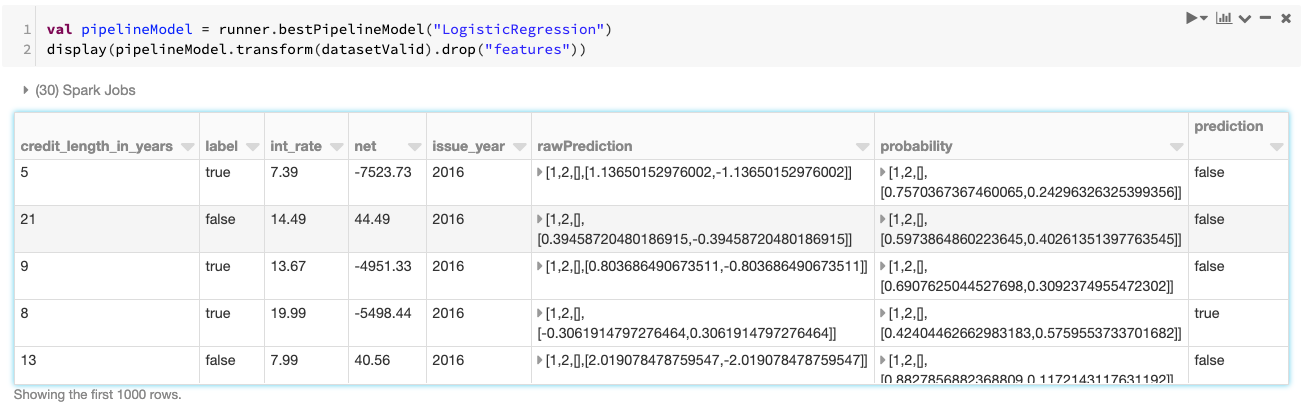
As can be seen in the cell output, the AutoML Pipeline API executes all of the stages originally created against the training data, now applied to the validation dataset. In this example, below is the abridged pipeline API cell output showing the stages it had executed.
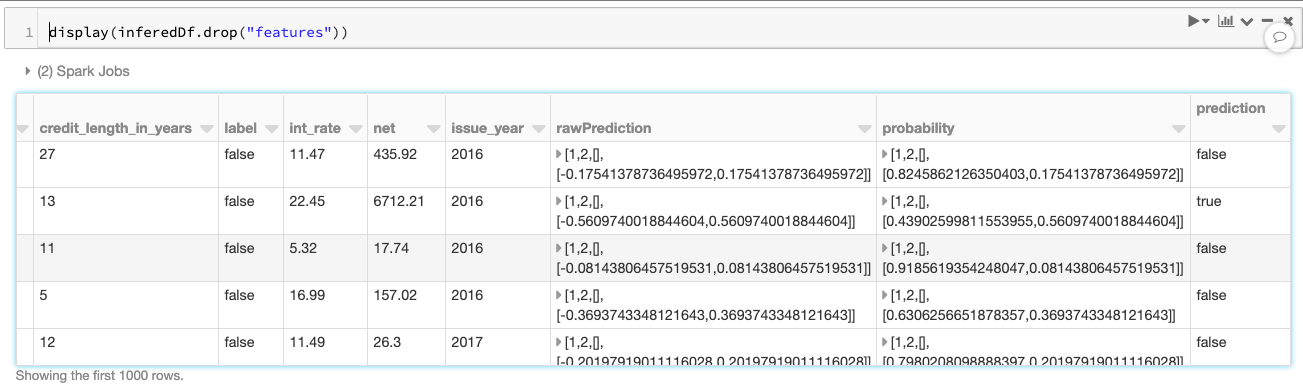
As noted in the previous code snippet (expand to review it), the inference DataFrame inferredDf generated by the Pipeline API contains the validation dataset including the prediction calculated (as noted in the screenshot below).
As can be seen, only MLflow Run ID was required to fetch pipeline and run an inference. This is because Pipeline APIs internally log all artifacts to a run under an experiment in the MLflow project. The notebook on Using AutoML Toolkit's FamilyRunner Pipeline APIs to Simplify and Automate Loan Default Predictions further demonstrates all the tags added to MLflow Run.
Use PipelineModel to Manually Save and Load your AutoML Pipelines
Even if MLflow is not enabled, the PipelineModel provides the flexibility to manually save these pipeline models under a custom path.
Simplifying Feature Engineering with the Pipeline API
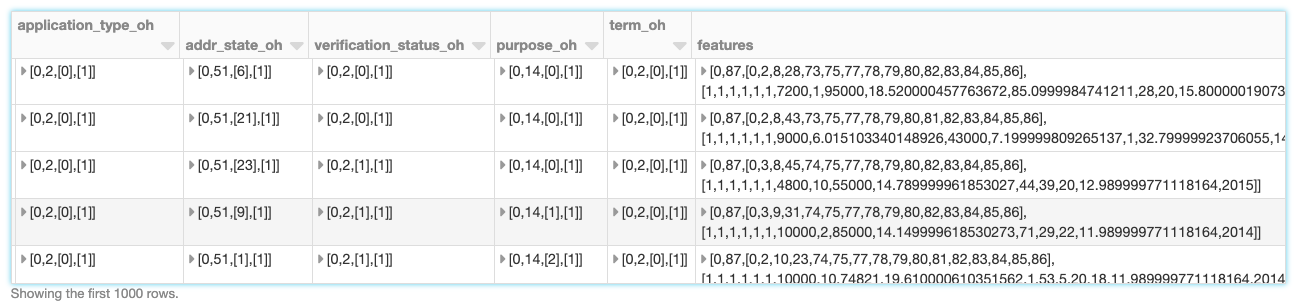
In addition to the full inference pipeline, FamilyRunner also exposes an API to run only feature engineering steps, without executing feature selection or computing feature importances. It takes AutoML’s main configuration object and converts that into a pipeline. This can be useful for doing analysis on feature engineering datasets, without having to manually apply Pearson filters, covariance, outlier filters, cardinality limits, and more. It enables the use of models, which aren’t yet part of the AutoML toolkit, but still leverages AutoML’s advanced feature engineering stages.
Discussion
With the Family Runner API, you can run multiple model types concurrently to find the best model and its hyperparameters across multiple models. With AutoML Toolkit’s Release 0.6.1, we have upgraded to MLflow 1.3.0 and introduced a new Pipeline API that significantly simplifies feature generation and inference. Try the AutoML Toolkit and the Using AutoML Toolkit's FamilyRunner Pipeline APIs to Simplify Loan Risk Analysis notebook today!
Contributions
We'd like to thank Sean Owen, Ben Wilson, Brooke Wenig, and Mladen Kovacevic for their contributions to this blog.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.