Security that Unblocks the True Potential of your Data Lake
by Vinay Wagh
Over the last few years, Databricks has gained a lot of experience deploying data analytics at scale in the enterprise. In many cases, our customers have thousands of people using our product across different business units for a variety of different use cases —all of which involve accessing various data classifications from private and sensitive data to public data. This has brought forth to us various challenges that come with deploying, operating and securing a data analytics platform at scale. In this blog post, I want to talk about some of those learnings.
Challenges with securing a data lake
As they move to break down data silos, many organizations push all of their data, from different sources, into a data lake where data engineers, data scientists and business analysts can process and query the data. This addresses the challenge of making data available to users but creates a new challenge of protecting and isolating different classes of data from users who are not allowed to access it.
What we have learned from our experience is that scaling from operationalizing a single use case in production to operationalizing a platform that any team in the enterprise could leverage poses a lot of security questions:
- How can we ensure that every compute environment accessing the data lake is secure and compliant with enterprise governance controls?
- How do we ensure that each user can only access the data they are allowed to access?
- How do we audit who is accessing the data lake and what data are they reading/writing to?
- How do we create a policy-governed environment without relying on users to follow best practices to protect our company’s most sensitive data?
These questions are simple to answer and implement for a small team or small datasets for a specific use case. However, it is really hard to operationalize data at scale such that every data scientist, engineer, and analyst can make most use of the data. That’s exactly what the Databricks platform is built for — simplifying and enabling data analytics securely at enterprise scale.
Based on our experience here are some themes that platforms need to pay attention to
Cloud-native controls for core security
Enterprises spend a lot of money and resources in creating and maintaining a data lake with the promise that the data can be used for a variety of products and services across the enterprise. No one platform can solve all enterprise needs which implies that this data will be used by different products either homegrown, vendor acquired or cloud-native. For this reason, data has to be unified in an open format and secured using cloud-native controls where possible. Why? Two reasons. One, because cloud providers have figured out how to scale their core security controls. Two, if protecting and accessing data requires proprietary tools, then you will have to integrate those tools with everything that accesses the data. This can be a nightmare to scale. So, when in doubt go cloud-native.
This is exactly what the databricks platform does. It integrates with IAM, AAD for identity and KMS/Key vault for encryption of data, STS for access tokens, security groups/NSGs for instance firewalls. This gives enterprises control over their trust anchors, centralize their access control policies in one place and extend them to Databricks seamlessly.

Isolate the environment
Separation of compute and storage is an accepted architecture pattern to store and process large amounts of data. Securing and protecting the compute environment that can access the data is the most important step when it comes to reducing the overall attack surface. How do you secure the compute environment ? Reminds me of a quote by Dennis Hughes from the FBI that said “The only secure computer is one that's unplugged, locked in a safe, and buried 20 feet under the ground in a secret location and I'm not even too sure about that one” - well sure but that does not help us with the goal to enable all enterprise data scientists and engineers to get going with new data projects in minutes across the globe and at scale. So what does? Isolation, isolation, isolation.
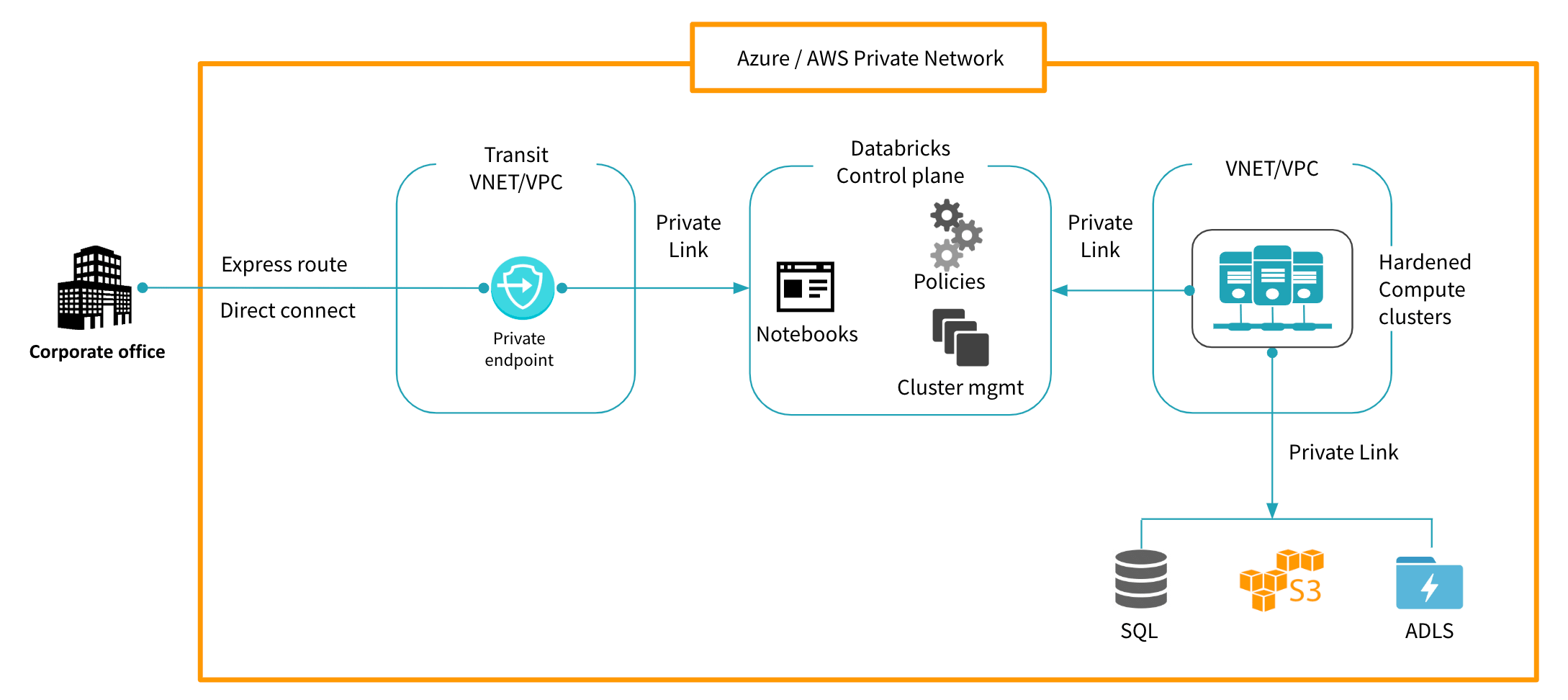
Step 1. Ensure that the cloud workspaces for your analytics are only accessible from your secured corporate perimeters. If employees need to work from remote locations they need to VPN into the corporate network to access anything that can touch data. This will allow enterprise IT to monitor, inspect and enforce policies on any access to workspaces in the cloud.
Step 2. Go invisible, and by that I mean, implement Azure Private Link or AWS privateLink. Ensure that all traffic between users of your platform,the notebooks and the compute clusters that process queries is encrypted and transmitted over the cloud provider’s network backbone, inaccessible to the outside world. This also works to mitigate against data exfiltration because compromised or malicious users cannot send data externally. VPC/VNET peering addresses a similar requirement but is operationally more intensive and can’t scale as well.
Step 3. Restrict and monitor your compute. The compute clusters that execute the queries should be protected by restricting ssh and network access. This prevents installation of arbitrary packages, and ensures you’re only using images that are periodically scanned for vulnerabilities and continuously monitored to verify so. This can be accomplished with Databricks by simply clicking: “launch cluster.” Done!
Databricks makes it really easy to do the above. Dynamic IP access lists allow admins to access workspaces only from their corporate networks. Furthermore, Private Link ensures that the entire network traffic between users->databricks->clusters->data stays within cloud provider networks. Every cluster that is launched is started with images that have been scanned for vulnerabilities and are locked down so that changes that violate compliance can be restricted - all this is built-in to the workspace creation and cluster launch.
Secure the data
The challenge with data security/protection of a data lake is that the data lake has large amounts of data that can have different levels of classification and sensitivity. Often this data is accessed by users through different products and services and can contain PII data. How do you provide data access to 100’s / 1000’s of engineers while ensuring that they can only access the data they are allowed to?
Remove PII data
Before data lands into the data lake, remove PII data. This should be possible in many cases. This has proven to be the most successful route when minimizing the scope of compliance and ensuring that users don’t accidentally use/leak PII data. There are several ways to accomplish this but incorporating this as part of your ingest is the best approach. If you must have data that can be classified as PII in the data lake be sure to build in the capability to query for it and delete it if required (by CCPA, GDPR). This article demonstrates how this can be achieved using delta.
Strong access control
Most enterprises have some form of data classification in place. The access control strategy depends on how the data is stored in the data lake. If data categorized under different classifications is separated into different folders, then having IAM roles map to the segregated storage enables clean separation, and users/groups in the identity provider can be associated with one or more of these roles. If this approach suffices it’s easier to scale than implementing granular access control.
If classification is defined at the data object level, or access control needs to be implemented at the row/column/record level, the architecture requires a centralized access control layer that can enforce granular access control policies on every query. The reason this should be centralized is because there may be different tools/products that access the data lake and having different solutions for each will require maintaining policies in multiple places. There are products that have rich features in this area of attribute-based access control and the cloud providers are also implementing this functionality. The winner will have the right combination of ease-of-use and scalability.
Whatever you do it's important to ensure that you can attribute access back to an individual user. A query executed by a user should assume the identity and role of that user before accessing the data, which will not only give you granular access control but also provide a required audit trail for compliance.
Encryption
Encryption not only acts as a way to gain “ownership” of data on third-party infrastructure but can also be used as an additional layer of access control. Use cloud provider key-management systems over third parties here because they are tightly integrated with all services. Achieving the same level of integration for all the cloud services that you want to use with third party encryption providers is near impossible.
Enterprises that want to go the extra mile in security should configure policies on customer-managed keys used to encrypt/decrypt data and combine that with access control of the storage folder itself. This approach ensures separation of duties between users who manage storage environments vs those who need to access the data in the storage environment. Even if new IAM roles are created to access data they will not be authorized to access the KMS key to decrypt it, thus creating a second level of enforcement.
Unblock your data lake’s potential
The true potential of data lakes can only be realized when the data in the lake is available to all of the engineers and scientists who want to use it. Accomplishing this requires a strong security fabric woven into the data platform. Building such a data platform that can also scale to all users across the globe is a complex undertaking. Databricks delivers such a platform that is trusted by some of the largest companies in the world as the foundation of their AI-driven future.
Learn more about other steps in your journey to create a simple, scalable and production-ready data platform, ready the following blogs
Enabling Massive Data Transformation Across Your Organization
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.