Data Exfiltration Protection with Azure Databricks
Learn details of how you could set up a secure Azure Databricks architecture to protect data exfiltration
Last updated on: October 30, 2025
Essential Reading
Before you begin, please make sure that you are familiar with these topics
- Azure Databricks Serverless Compute Architecture
- Key Databricks terminology
- What is Front and Backend Azure Databricks Private Link (PL)?
- Private Link enabled workspace requirements
- What is Service Endpoint Policies for Azure workspaces
- Ingress controller IP Access List
- Secure Cluster Connectivity
- Databricks Networking
- Unity Catalog
The Azure Databricks Lakehouse Platform provides a unified set of tools for building, deploying, sharing, and maintaining enterprise-grade data solutions at scale. Databricks integrates with cloud storage and security in your cloud account, and manages and deploys cloud infrastructure on your behalf.
The overarching goal of this article is to mitigate the following risks:
- Data access from a browser on the internet or an unauthorized network using the Databricks web application.
- Data access from a client on the internet or an unauthorized network using the Databricks API.
- Data access from a client on the internet or an unauthorized network using the Azure Private Link or Service Endpoints.
- A compromised workload on the Azure Databricks cluster writing data to an unauthorized storage resource on Azure or on the internet.
Azure Databricks is a first party service and supports Azure’s native tools and services that help protect data in transit and at rest. Azure Databricks supports network security controls, such as user defined routes, firewall rules and Network Security Groups.
On top of the technical goals for this blog, we also want to be sure that the concepts we are presenting consider:
- Simplicity, any security design should be well understood and maintainable, and fit within the skill sets of your organization. A security solution that gets implemented and not fully understood can be inadvertently compromised.
- Operational cost of the solution should always be taken into account. If a security design is abandoned because the cost is too high - then the solution was not effective. Security should be cost conscious and sustainable.
We will point out areas for cost saving or cost concerns along with trying to clarify why and how things work whenever we can.
Before we begin, let’s have a quick look at the Azure Databricks deployment architecture here:
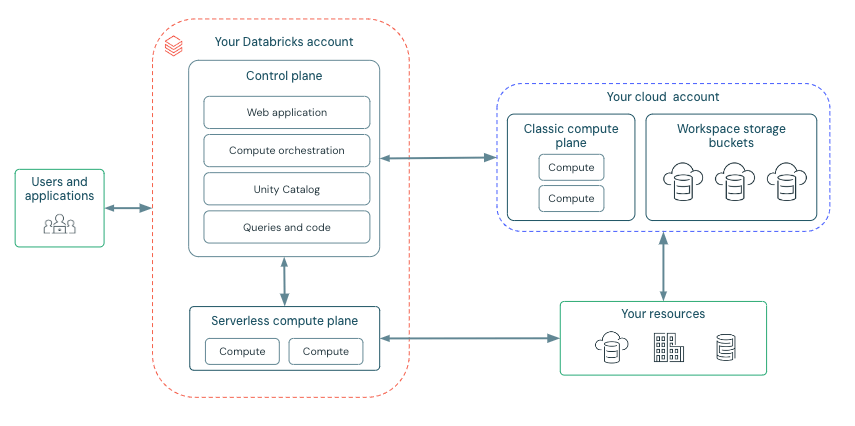
Azure Databricks is structured to facilitate secure collaboration across teams, while it handles the management of many backend services, allowing you to concentrate on data science, data analytics, and data engineering.
Azure Databricks is structured around two key components: the control plane and the compute plane.
Control Plane:
The Azure Databricks control plane, managed by Databricks within its own Azure account, acts as the platform's core intelligence. It provides backend services for user authentication, cluster and job orchestration, and workspace management, offering the web interface and API endpoints for service interaction.
While it orchestrates the lifecycle of compute resources, it does not directly process data. Instead, the control plane directs data processing to the separate compute plane, which operates either within the customer's Azure subscription or the Databricks tenant for serverless deployments. Notebook commands and many other workspace configurations are stored in the control plane and encrypted at rest.
Compute Plane:
The compute plane is responsible for processing your data. The specific type of compute used, serverless or classic, depends on your chosen compute resources and workspace configuration. Both serverless and classic compute share some resources such as default workspace storage (dbfs) and managed identities that are tied to your Azure tenant.
Serverless Compute
For serverless compute, resources operate within a compute plane in Azure managed by Databricks. Azure Databricks handles almost all the entire underlying infrastructure, including provisioning, scaling, and maintenance. This approach offers:
- Simplified Operations: Users can focus on data engineering and data science tasks without the need to manage clusters or virtual machines.
- Cost Efficiency: Users are billed only for the compute resources actively consumed during workload execution, eliminating costs associated with idle clusters.
Serverless resources are available as needed, reducing idle time costs. They also run within a secure network boundary in the Azure Databricks account, with multiple layers of security and network controls.
Classic Azure Databricks Compute
With classic Azure Databricks compute, resources are situated within your Azure Cloud tenant. This provides customer-managed compute, where Databricks clusters run on resources within your Azure subscription, not the Databricks tenant. This offers:
- Natural Isolation: Operations occur within your own Azure subscription and virtual network.
- Secure Connections: Enables secure connections to other Azure services through service endpoints or private endpoints that you manage and control.
Important Note: Classic clusters, including classic SQL warehouses, may experience longer startup times compared to serverless options due to the requirement of provisioning resources from your Azure subscription.
Serverless Only Databricks Workspace deployment (new): Serverless only workspaces are workspaces that can only run serverless compute. There is no classic compute so all system resources are managed by Azure Databricks, which handles all the entire underlying infrastructure, including workspace default storage.
High-level Architecture
Network Communication Path
Let’s understand the communication path that we would like to secure. Azure Databricks could be consumed by users and applications in numerous ways as shown below:
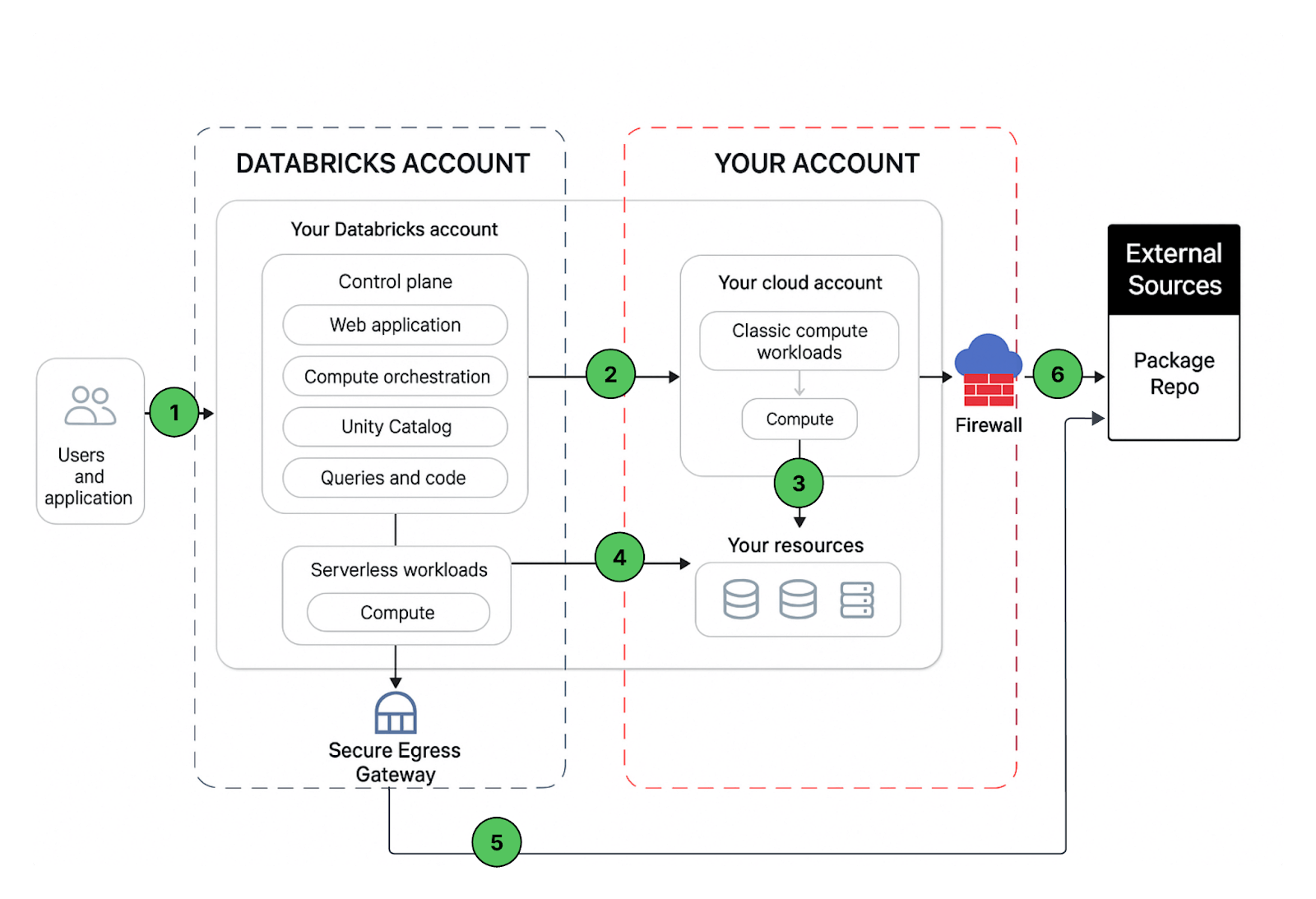
A Databricks workspace deployment includes the following network paths that you could secure:
- User or Applications to Azure Databricks web application aka workspace or Databricks REST APIs
- Azure Databricks classic compute plane virtual network to the Azure Databricks control plane service. This includes the secure cluster connectivity relay and the workspace connection for the REST API endpoints.
- Classic compute plane to your storage services (ex:ADLS gen2, SQL database)
- Serverless compute plane to to your storage services (ex:ADLS gen2, SQL database)
- Secure egress from serverless compute plane via network policies (egress firewall) to external data sources e.g. package repositories like pypi or maven
- Secure egress from classic compute plane via egress firewall to external data sources e.g. package repositories like pypi or maven (it could be any egress appliance running on Azure ex: Palo Alto)
From an end-user perspective, item 1 requires ingress controls, and items 2 to 6 require egress controls.
In this article our focus area is to secure egress traffic from your databricks workloads, provide the reader with a prescriptive guidance on the proposed deployment architecture and while we are at it, we’ll share best practices to secure ingress (user/client into Databricks) traffic as well.
Workspace Deployment Options
There are multiple options available to create a secure Azure Databricks workspace that is accessible from on-premise or VPN connections (no internet access). As a best practice, we recommend securing access to the workspace using private endpoints (Private Link) using either a standard or simplified deployment. The recommended option is standard deployment. The workspace can be deployed via Azure Portal or All in one ARM templates or using Security Reference Architecture (SRA) Terraform templates which enables deployment of Databricks workspaces and cloud infrastructure configured with security best practices
Front End vs Back End private link: Front-end Private Link, also known as user to workspace. Back-end Private Link, also known as compute plane to control plane:
Standard deployment (recommended): For improved security, Databricks recommends you use a separate private endpoint for your front-end (client) connections from a separate transit VNet. You can implement both front-end and back-end Private Link connections or just the back-end connection. Use a separate VNet to encapsulate user access, separate from the VNet that you use for your compute resources in the Classic data plane. Create separate Private Link endpoints for back-end and front-end access. Follow the instructions in Enable Azure Private Link as a standard deployment.
Additional consideration is needed for system storage, messaging and metadata access from the compute plane since these services cannot be accessed via the back-end private endpoint.
System managed storage accounts (classic compute plane only): These storage accounts are needed to boot and monitor Databricks clusters. These storage accounts are in the Databricks tenant and need to be allowed via service endpoint policies (recommended), alternatives would be using storage service tags which tend to be overbroad and make it easier to exfiltrate data, or individual allowlisting of the FQDN or ip addresses (not recommended):
- Artifact: Read only Databricks Runtime images > 11gb / cluster node
- Logging: Read / Write heavy weight messaging including audit logging.
- System Tables: Read only audit, UC and system data.
Workspace default storage (DBFS): Common distributed file system used for scratch space, services, temporary SQL results (cloud fetch), drivers. Can be secured via private endpoints using the private DBFS feature for classic compute and service endpoint or private endpoint for serverless compute.
Messaging: (Event Hub, classic compute plane only) This is a publicly accessible resource used for lineage tracking and other light weight messaging. Can be allowed via EventHub service tag at the UDR and/or Firewall.
Metadata: (SQL, classic compute plane only): This is a publicly accessible resource used for legacy Hive metastore traffic.
User level storage account access: ALDS and Blob Storage accounts used for customer data as opposed to system data.
First party resources: Cosmos DB, Azure SQL, DataFactory etc…
External resources: S3, BigQuery , Snowflake etc…
High-level Data Exfiltration Protection Architecture
We recommend a hub and spoke reference architecture. In this model, the hub virtual network hosts the shared infrastructure necessary for connecting to validated sources and, optionally, to on-premises environments. The spoke virtual networks peer with the hub and contain isolated Azure Databricks workspaces for different business units or teams.
This hub-and-spoke architecture enables the creation of multiple-spoke VNETs tailored for various purposes and teams. Isolation can also be achieved by creating separate subnets for different teams within a single, large virtual network. In these cases, you can establish multiple isolated Azure Databricks workspaces, each within its own subnet pair, and deploy Azure Firewall in a separate subnet within the same virtual network.
Pre-requisites
| Item | Details |
|---|---|
| Virtual Network |
|
| Subnets | Three subnets Host (Public) , Container (Private) and Private endpoint Subnet (to hold private endpoints for the storage, DBFS and other azure services that you may use) |
| Route Tables | Channel Egress traffic from the Databricks Subnets to network appliance, Internet or On-prem data sources |
| Azure Firewall | Inspect any egress traffic and take actions according to allow / deny policies |
| Private DNS Zones | Provide reliable, secure DNS service to manage and resolve domain names in a virtual network (can be automatically created as part of the deployment if not available) |
| Service Endpoint Policies | Policies for allowing access to any non-private endpoint based storage accounts including system storage for workspace storage account (dbfs), artifact and logging storage, and system tables. |
| Azure Key Vault | Stores the CMK for encrypting DBFS, Managed Disk and Managed Services. |
| Azure Databricks Access Connector | Required if enabling Unity Catalog. To connect managed identities to an Azure Databricks account for the purpose of accessing data registered in Unity Catalog |
| List of Azure Databricks services to allow list on Firewall | Please follow this public doc and make a list of all the ip’s and domain names relevant to your databricks deployment |
Deployment Architecture
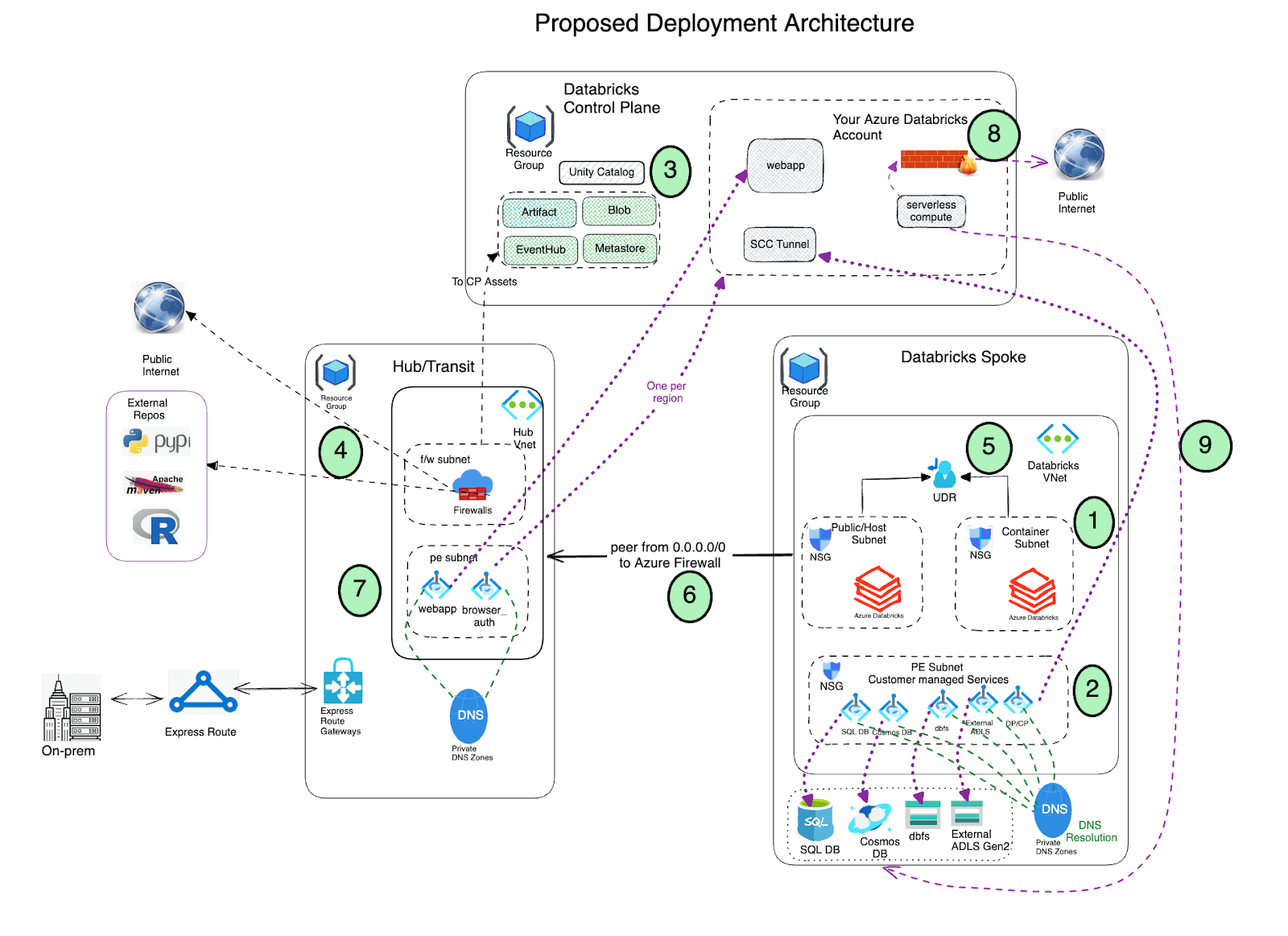
- Deploy Azure Databricks with secure cluster connectivity (SCC) enabled in a spoke virtual network using VNet injection and Private link.
- The virtual network must include two subnets dedicated to each Azure Databricks workspace: a private subnet and public subnet (feel free to use a different nomenclature). Note that there is a one-to-one relationship between these subnets and an Azure Databricks workspace. You cannot share multiple workspaces across the same subnet pair, and must use a new subnet pair for each different workspace.
- Azure Databricks creates a default blob storage (a.k.a root storage) during the deployment process which is used for storing logs and telemetry. Even though public access is enabled on this storage, the Deny Assignment created on this storage prohibits any direct external access to the storage; it can be accessed only via the Databricks workspace. Azure Databricks deployments now support private connectivity to the default workspace storage account (DBFS).
- Important : As a best practice It is NOT recommended to store any application data in the root container (DBFS) storage. Access to the DBFS root container can now be disabled and instead we recommend using Unity catalog volumes. Unity Catalog volumes offer modern governance and security over DBFS root storage.
- Set up Private Link endpoints for your Azure Data Services (Storage accounts, Eventhub, SQL databases etc) in a separate subnet within the Azure Databricks spoke virtual network. This would ensure that all workload data is being accessed securely over Azure network backbone with default data exfiltration protection in place (refer to this blog for more details). Also in general it’s completely fine to deploy these endpoints in another virtual network that’s peered to the one hosting the Azure Databricks workspace. Note that Private Endpoints incurs additional cost and it is fine to leverage (based on your organization’s security policies) Service Endpoints instead of Private Endpoints to access the Azure Data services, specifically using Service Endpoint Policies for secure storage account access
- Leverage Azure Databricks Unity Catalog for unified governance solution.
Deploy Azure Firewall (or other Network Virtual Appliance) in a hub virtual network. With Azure Firewall, you could configure:
- Application rules that define fully qualified domain names (FQDNs) that are accessible through the firewall. It is highly recommended that you use Application rules for Azure Databricks control plane resources ex: control plane, web app and scc relay.
- Network rules that define IP address, port and protocol for endpoints that can’t be configured using FQDNs. Some of the required Azure Databricks traffic needs to be whitelisted using the network rules.
If you happen to use a third-party firewall appliance instead of Azure Firewall, that works as well. Though please note that each product has its own nuances and it’s better to engage relevant product support and network security teams to troubleshoot any pertinent issues.
- AzureDatabricks Service Tag is not required if private endpoints are enabled for the workspace.
- When using Service Endpoint Policies, there is no need for network rules for Databricks service storage accounts (artifact, logging, and system tables) in the firewall. Also, no storage service tags are needed or recommended.
- Azure Databricks also makes additional calls to NTP service, CDN, cloudflare, GPU drivers and external storages for demo datasets which need to be whitelisted appropriately.
Non-local network traffic from Databricks compute plane subnets should be routed through an egress appliance like Azure Firewall using a user-defined route (for example a default route 0.0.0.0/0). This ensures all outbound traffic is inspected. However, egress to the control plane, utilizing private endpoints, will bypass these route tables and egress appliances. Other control plane components, such as SQL, Event Hubs, and storage, will, however, be routed through your egress appliance.
- For Databricks service storage accounts (artifact, logging, and system tables), you might consider the option of bypassing your egress appliance (NVA or firewall) to avoid potential throttling and reduce data transfer costs. Access to artifact storage alone can account for up to 11GB downloaded per cluster node. We recommend using service endpoints for storage in conjunction with Service Endpoint Policies. These policies ensure that the workspace can only access the designated artifact, logging, and system tables storage accounts included in its attached policy via its subnet. Service Endpoint Policies are also compatible with other non-private link storage account access. With service endpoint policies, no storage service tags are needed or recommended.
- Alternatively, egress traffic to Control Plane assets can be routed directly to the internet by adding Service tag rules to the route table, bypassing the firewall. This can help avoid throttling and additional data transfer costs associated with Network Virtual Appliances.
Important Consideration: Please note that this will allow egress to storage accounts and services across the entire region, not just the ones you intend to reach. This is a critical factor to carefully consider when designing your security architecture.
- Configure virtual network peering between the Azure Databricks spoke and Azure Firewall hub virtual networks.
- Deploy Private endpoints for the Front end and browser auth (for SSO) on the Hub Vnet (private end point subnet)
- Configure serverless compute network policies to govern egress network traffic. Note that Serverless compute is tied to your Azure Databricks Account
- Configure Azure Databricks Network Connectivity Config (NCC) to establish a secure connection between your serverless compute resources and your Azure storage services (such as ADLS Gen2 and SQL Database) using Azure Private Link.
Common Questions with Data Exfiltration Protection Architecture
Can I use service endpoints to secure data egress to Azure Data Services?
Yes, Service Endpoints provide secure and direct connectivity to Azure services owned and managed by customers (ex: ADLS gen2, Azure KeyVault or eventhub) over an optimized route over the Azure backbone network. Service Endpoints can be used to secure connectivity to external Azure resources to only your virtual network.
Can I use service endpoint policies with Databricks managed storage services?
Yes Service Endpoint Policies are available in public preview as of 10/1/2025. See: Configure Azure virtual network service endpoint policies for storage access from classic compute
Can I use a Network Virtual Appliance (NVA) other than Azure Firewall?
Yes, you could use a third-party NVA as long as network traffic rules are configured as discussed in this article. Please note that we have tested this setup with Azure Firewall only, though some of our customers use other third-party appliances. It’s ideal to deploy the appliance in the cloud rather than have them be on-premises.
Can I have a firewall subnet in the same virtual network as Azure Databricks?
Yes, you can. As per Azure reference architecture, it is advisable to use a hub-spoke virtual network topology to plan better for the future. Should you choose to create the Azure Firewall subnet in the same virtual network as Azure Databricks workspace subnets, you wouldn’t need to configure virtual network peering as discussed in Step 6 above.
Can I filter Azure Databricks control plane SCC Relay IP traffic through Azure Firewall?
Yes you can but we would like you to keep these points in mind:
- When using private endpoints for the Databricks control plane, the traffic between Azure Databricks clusters (data plane) and the SCC Relay service stays private over Azure Network and does not flow over the public internet. This is primarily management traffic to make sure Azure Databricks workspace is functioning properly.
- When using non private link access to the Databricks control plane, SCC Relay and WebUI CIDR ranges are covered by the AzureDatabricks service tag. For other firewall / NVA types refer to the latest version of IP addresses and domains for Azure Databricks services and assets. We highly recommend using an application rule FDQN for the SCC tunnel in your firewall rule configs.
- SCC Relay service and the data plane needs to have stable and reliable network communication in place, having a firewall or a virtual appliance between them introduces a single point of failure e.g. in case of any firewall rule misconfiguration or scheduled downtime which may result in excessive delays in cluster bootstrap (transient firewall issue) or won't be able to create new clusters or affect scheduling and running jobs.
Can I analyze accepted or blocked traffic by Azure Firewall?
Yes, we recommend using Azure Firewall Logs and Metrics for that requirement.
Can I upgrade an existing non-NPIP (managed Databricks deployment) to NPIP or PL Enabled workspace?
Yes, managed databricks deployment can be upgraded to a VNet Injected workspace.
Why do we need two subnets per workspace?
A workspace requires two subnets, popularly known as “host” (a.k.a “public”) and “container” (a.k.a “private”) subnets. Each subnet provides an ip-address to the host (Azure VM) and the container (Databricks runtime aka dbr) which runs inside the VM.
Does the public or host subnet have public ips?
No, when you create a workspace using secure cluster connectivity aka SCC, none of Databricks’ subnets have public IP addresses. It is just that the default name of the host subnet is public-subnet. SCC makes sure that no network traffic from outside of your network enters e.g. SSH into one of the Databricks workspace compute instances.
Is it possible to resize/change the subnet sizes after the deployment?
Yes, it is possible to resize or change the subnet sizes after the deployment. � It is also possible to change the virtual network or change the subnet names. (gated public preview). Please reach out to Azure support, and submit a support case for resizing the subnets.
Is it possible to swap out / change Virtual Networks after the deployment?
Yes, please refer to the public docs.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.