Manage and Scale Machine Learning Models for IoT Devices
by Conor Murphy
A common data science internet of things (IoT) use case involves training machine learning models on real-time data coming from an army of IoT sensors. Some use cases demand that each connected device has its own individual model since many basic machine learning algorithms often outperform a single complex model. We see this in supply chain optimization, predictive maintenance, electric vehicle charging, smart home management, or any number of other use cases. The problem is this:
- The overall IoT data is so large that it won’t fit on any one machine
- The per device data does fit on a single machine
- An individual model is needed for each device
- The data science team is implementing using single node libraries like sklearn and pandas, so they need low friction in distributing their single-machine proof of concept
In this blog, we demonstrate how you solve this problem with two distinct schemes for each IoT device: Model Training and Model Scoring.
The Multi-IoT Device ML Solution
This is a canonical big data problem. IoT devices such as weather sensors and vehicles produce an awe-inspiring amount of data points. Single-machine solutions won’t scale to a problem of this complexity and often don’t integrate as well into production environments. And data science teams don’t want to worry about whether the DataFrame they’re using is a single-machine pandas object or is distributed by Apache Spark. And one more thing: we need to log our models and their performance somewhere for reproducibility, monitoring, and deployment.
Here are the two schemas we need to solve this problem:
- Model Training: create a function that takes the data for a single device as an input. Train the model. Log the resulting model and any evaluation metrics using MLflow, an open source platform for the machine learning lifecycle
- Model Scoring: create a second function that pulls the trained model from MLflow for that device, apply it, and return the predictions
With these abstractions in place, we only have to convert our functions into Pandas UDF’s in order to distribute them with Spark. A Pandas UDF allows for the efficient distribution of arbitrary Python code within a Spark job, allowing for the distribution of otherwise serial operations. We will then have taken a single-node solution and make it embarrassingly parallel.
IoT Model Training
Now let’s take a closer look at model training. Start with some dummy data. We have a fleet of connected devices, a number of samples for each, a few features, and a label we’re looking to predict. As is often the case with IoT devices, the featurization steps can be done with Spark to leverage its scalability.
Next we need to define the schema that our training function will return. We want to return the device ID, the number of records used in the training, the path to the model, and an evaluation metric.
Define a Pandas UDF that takes a pandas DataFrame for one group of data as an input and returns model metadata as its output.
IoT Device Model Logging with Nested Runs in MLflow
The MLflow tracking package allows us to log different aspects of the machine learning development process. In our case, we will create a run (or one execution of machine learning code) for each of our devices. We will aggregate these runs together using one parent run.
This also allows us to see if any individual models are less performant than others. We simply need to add the logging logic in the Pandas UDF, as seen above. Even though this code will be executing on the worker nodes of the cluster, if we start the parent run before we start the nested run, we’ll still be able to log these models together.
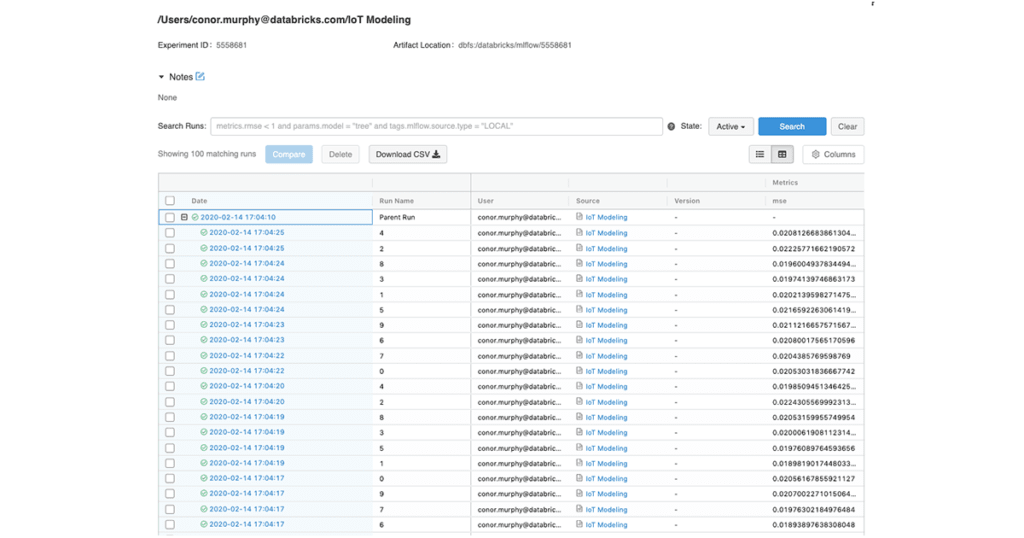
We could just query MLflow to get the URI’s for each model back. Returning the URI from the Pandas UDF instead just makes the whole pipeline a bit easier to stitch together.
Parallel Training
Now we just need to apply the Grouped Map Pandas UDF. As long as the data for any given device will fit on a node of the Spark cluster, we can distribute the training. First make the MLflow parent run and then apply the Pandas UDF using a groupby and then an apply.
And there you go! A model has now been trained and logged for each device.
IoT Model Scoring
Now for the scoring. The optimization trick here is to make sure that we only fetch the model once for each device, limiting the communication overhead. Then we apply the model as we would in a single machine context and return a pandas DataFrame of the record id’s and their prediction.
Note that in each case we’re using a Grouped Map Pandas UDF. In the first case, we take a group as an input and return one row for each device (a many-to-one mapping). In this case, we take a group as an input and return one prediction per row (a one-to-one mapping). A Grouped Map Pandas UDF allows for both approaches.
Conclusion
So there you have individualized models trained across an army of IoT devices. This supports the idea that many basic models generally outperform a single, more complex model. Even if this is generally the case, there might be some individual models that perform below average due in part to limited or missing data for that device. Here are some ideas for taking this further:
- Using the number of records available in the training and the evaluation metric, you can easily delineate the individual models that perform well versus the models that perform poorly. You can use this information to toggle between a per-device model and a model trained on the entire fleet.
- You could also train an ensemble model that takes the predictions from a per-device model, the predictions from a fleet-wide model, and metadata like the evaluation metrics and number of records per device. This would create a final prediction that would improve the under-performing individual models.
Get Started with MLflow for IoT Devices
Ready to try it out yourself? You can see the full example used in this blog post in a runnable notebook on AWS or Azure.
If you are new to MLflow, read the MLflow quickstart with the latest MLflow release. For production use cases, read about Managed MLflow on Databricks.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.