Key sessions for AWS customers at Spark + AI Summit
At Databricks, we are excited to have Amazon Web Services (AWS) as a sponsor of the first virtual Spark + AI Summit. Our work with AWS continues to make Databricks better integrated with other AWS services, making it easier for our customers to drive huge analytics outcomes.

As part of Spark + AI Summit, we wanted to highlight some of the top sessions that AWS customers might be interested in. A number of customers who are running Databricks on AWS are speaking at Spark + AI Summit - from organizations such as AirBNB, CapitalOne, Lyft, Zynga and Atlassian. The sessions below were chosen based upon their topical matter for customers using Databricks on the AWS cloud platform, demonstrating key service integrations. If you have questions about your AWS platform or service integrations, visit the AWS booth at Spark + AI Summit.
Building A Data Platform For Mission Critical Analytics
Hewlett Packard WEDNESDAY, 11:00 AM (PDT)
This session will feature a presentation by Sally Hoppe, Big Data System Architect at HP. Sally and her team have developed an amazing data platform to handle IOT information from HP printers, enabling them to derive insights into customer use and to deliver a better and more continuous service experience from HP printers. The HP platform includes integrations between Databricks and Delta Lake with AWS services such as Amazon S3 and Amazon Redshift as well as other technologies such as Apache Airflow and Apache Kafka. This session will also feature Igor Alekseev, Partner Solution Architect at AWS, and Denis Dubeau, Partner Solution Architect at Databricks.
Data Driven Decisions at Scale
Comcast WEDNESDAY, 11:35 AM (PDT)
Comcast is the largest cable and internet provider in the US, reaching more than 30 million customers, and continues to grow its presence in the EU with the acquisition of Sky. Comcast has rolled out their Flex device which allows for customers to stream content directly to their TVs without needing an additional cable subscription. Their customer data analytics program is generating data at a rate of more than 25TBs per day with over 3PBs of data being used for consumable insights. In order for the PABS team to be able to continue to drive consumable insights on massive data sets while still being able to control the amount of data being stored, the PABS team have been using Databricks and Databricks Delta Lake on S3 to do high current low latency read/writes in order to build reliable real-time data pipelines to deliver insights and also be able to do efficient deletes in a timely manner.
Deep Learning Enabled Price Action with Databricks and AWS
WEDNESDAY, 2:30 PM (PDT)
Predicting the movements of price action instruments such as stocks, ForEx, commodities, etc., has been a demanding problem for quantitative strategists for years. Simply applying machine learning to raw price movements has proven to yield disappointing results. New tools from deep learning can substantially enhance the quality of results when applied to traditional technical indicators rather than prices including their corresponding entry and exit signals. In this session Kris Skrinak and Igor Alekseev explore the use of Databricks analysis tools combined with deep learning training accessible through Amazon’s SageMaker to enhance the quality of predictive capabilities of two technical indicators: MACD and Slow stochastics.
Saving Energy in Homes with a Unified Approach to Data and AI
Quby THURSDAY, 11:35 AM (PDT)
Quby is an Amsterdam based technology company offering solutions to empower homeowners to stay in control of their electricity, gas and water usage. Using Europe’s largest energy dataset, consisting of petabytes of IoT data, the company has developed AI-powered products that are used by hundreds of thousands of users daily to maintain a comfortable climate in their homes and reduce their environmental footprint. This session will cover how Quby leverages the full Databricks stack to quickly prototype, validate, launch and scale data science products. They will also cover how Delta Lake allows batch and streaming on the same IoT data and the impact these tools have had on the team itself.
The 2020 Census and Innovation in Surveys
US Census Bureau THURSDAY, 12:10 PM (PDT)
The U.S. Census Bureau is the leading source of quality data about the people of the United States, and its economy. The Decennial Census is the largest mobilization and operation conducted in the United States – enlisting hundreds of thousands of temporary workers – and requires years of research, planning, and development of methods and infrastructure to ensure an accurate and complete count of the U.S. population, estimated currently at 330 million.
Census Deputy Division Chief, Zack Schwartz, will provide a behind the scenes overview on how the 2020 Census is conducted with insights into technical approaches and adopting industry best practices. He will discuss the application monitoring systems built in Amazon's GovCloud to monitor multiple clusters and thousands of application runs that were used to develop the Disclosure Avoidance System for the 2020 Census. This presentation will leave the audience with an appreciation for the magnitude of the Census and the role that technology plays, along with a vision for the future of surveys, and how attendees can do their part in ensuring that everyone is counted.
Building a Real-Time Feature Store at iFood
iFood THURSDAY, 2:30 PM (PDT)
iFood is the largest food tech company in Latin America. We serve more than 26 million orders each month from more than 150 thousand restaurants. In this talk, you will see how iFood built a real-time feature store, using Databricks and Spark Structured Streaming in order to process events streams, store them to a historical Delta Lake Table storage and a Redis low-latency access cluster, and structured their development processes in order to do it with production-grade, reliable and validated code.
Continuous Delivery of Deep Transformer-Based NLP Models Using MLflow and AWS Sagemaker for Enterprise AI Scenarios
Outreach Corporation FRIDAY, 10:00 AM (PDT)
In this presentation, Outreach will demonstrate how they use MLflow and AWS Sagemaker to productionize deep transformer-based NLP models for guided sales engagement scenarios at the leading sales engagement platform, Outreach.io.
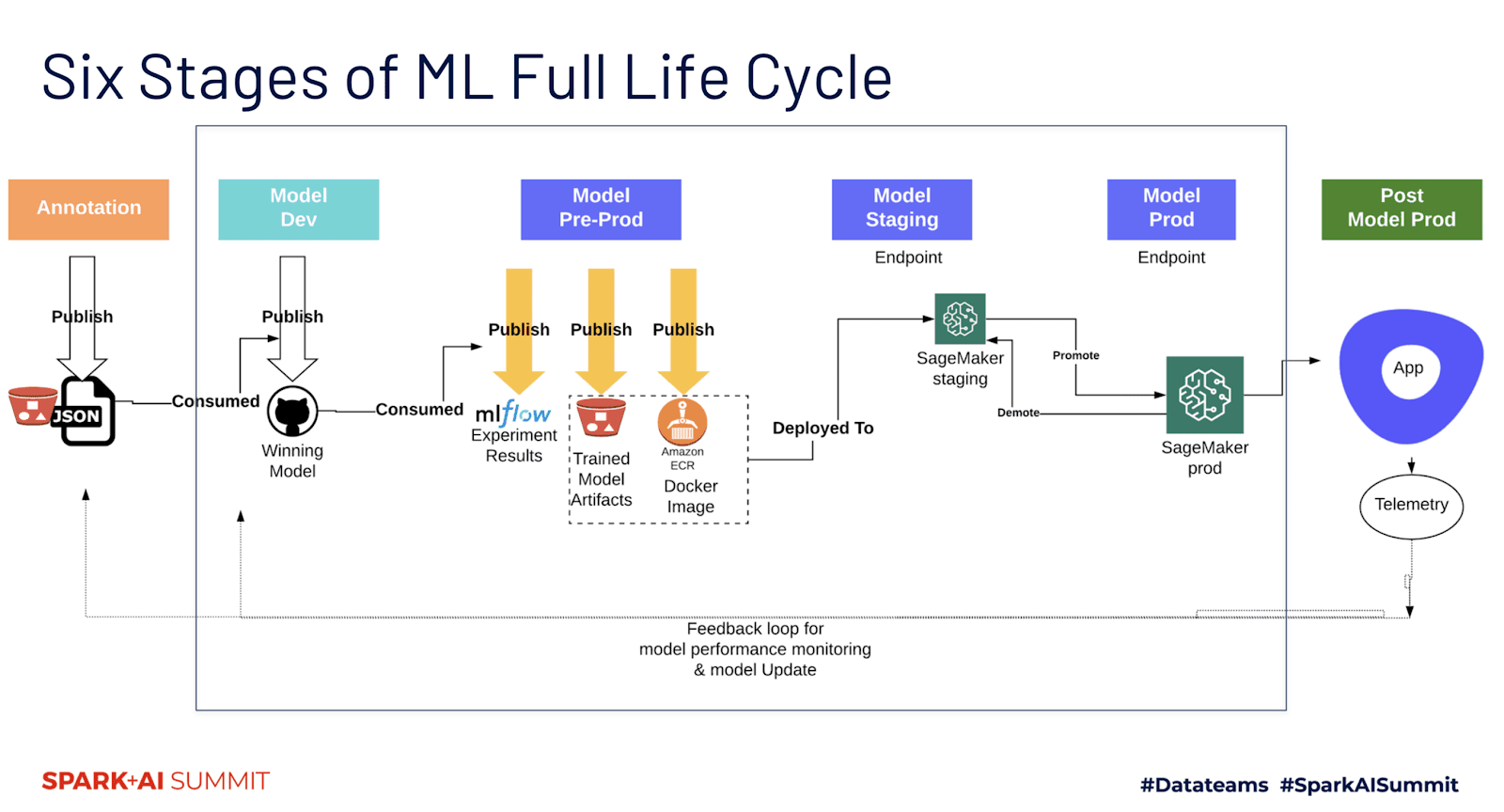
We are super excited about this session from a ML Ops perspective. The Outreach team will share their experiences and lessons learned in the following areas:
- A publishing/consuming framework to effectively manage and coordinate data, models and artifacts (e.g., vocabulary file) at different machine learning stages
- A new MLflow model flavor that supports deep transformer models for logging and loading the models at different stages
- A design pattern to decouple model logic from deployment configurations and model customizations for a production scenario using MLProject entry points: train, test, wrap, deploy.
- A CI/CD pipeline that provides continuous integration and delivery of models into a Sagemaker endpoint to serve the production usage
We think this session is not to be missed.
We hope you find these sessions super useful for learning more ways to integrate Databricks on your AWS platform. Please visit the AWS booth to discuss your use cases and to get an opportunity to get the perspective of AWS experts. More information around our AWS partnership and integrations is available at www.databricks.com/aws
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.