Welcoming Redash to Databricks
Easily visualize, dashboard, and share your data
by Reynold Xin
This morning at Spark and AI Summit, we announced that Databricks has acquired Redash, the company behind the popular open source project of the same name. With this acquisition, Redash joins Apache Spark, Delta Lake, and MLflow to create a larger and more thriving open source system to give data teams best-in-class tools. I would like to take this opportunity to send a warm public welcome to the Redash team and the open source community, and share with you our thinking behind the acquisition.

As part of the announcement, we also shared our plan for a hosted version of Redash that will be fully integrated into the Databricks platform to create a rich visualization and dashboarding experience. The integrated experience is currently available in private preview, and you can sign up for the private preview waitlist to be the first to try it out.
What is Redash?
Redash is a collaborative visualization and dashboarding platform designed to enable anyone, regardless of their level of technical sophistication, to share insights within and across teams. SQL users leverage Redash to explore, query, visualize, and share data from any data sources. Their work in turn enables anybody in their organization to use the data. Every day, millions of users at thousands of organizations around the world use Redash to develop insights and make data-driven decisions.
Redash includes the following features:
- Query editor: Quickly compose SQL and NoSQL queries with a schema browser and auto-complete.
- Visualization and dashboards: Create beautiful visualizations with drag and drop, and combine them into a single dashboard.
- Sharing: Collaborate easily by sharing visualizations and their associated queries, enabling peer review of reports and queries.
- Schedule refreshes: Automatically update your charts and dashboards at regular intervals you define.
- Alerts: Define conditions and be alerted instantly when your data changes.
- REST API: Everything that can be done in the UI is also available through REST API.
- Broad support for data sources: Extensible data source API with native support for a long list of common SQL, NoSQL databases and platforms.
Easily run SQL queries against Delta Lake or any other data sources
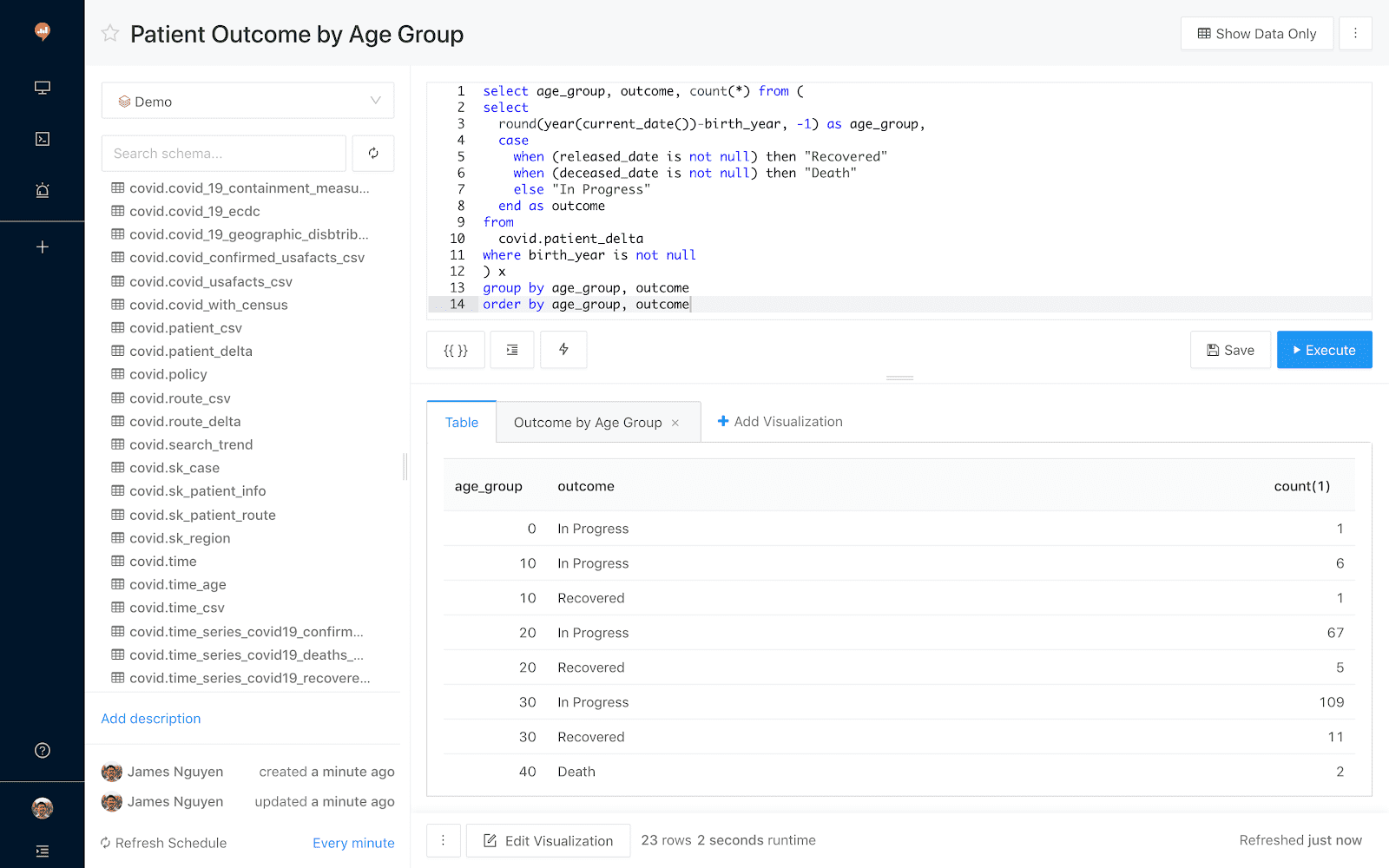
Quickly turn results into visualizations
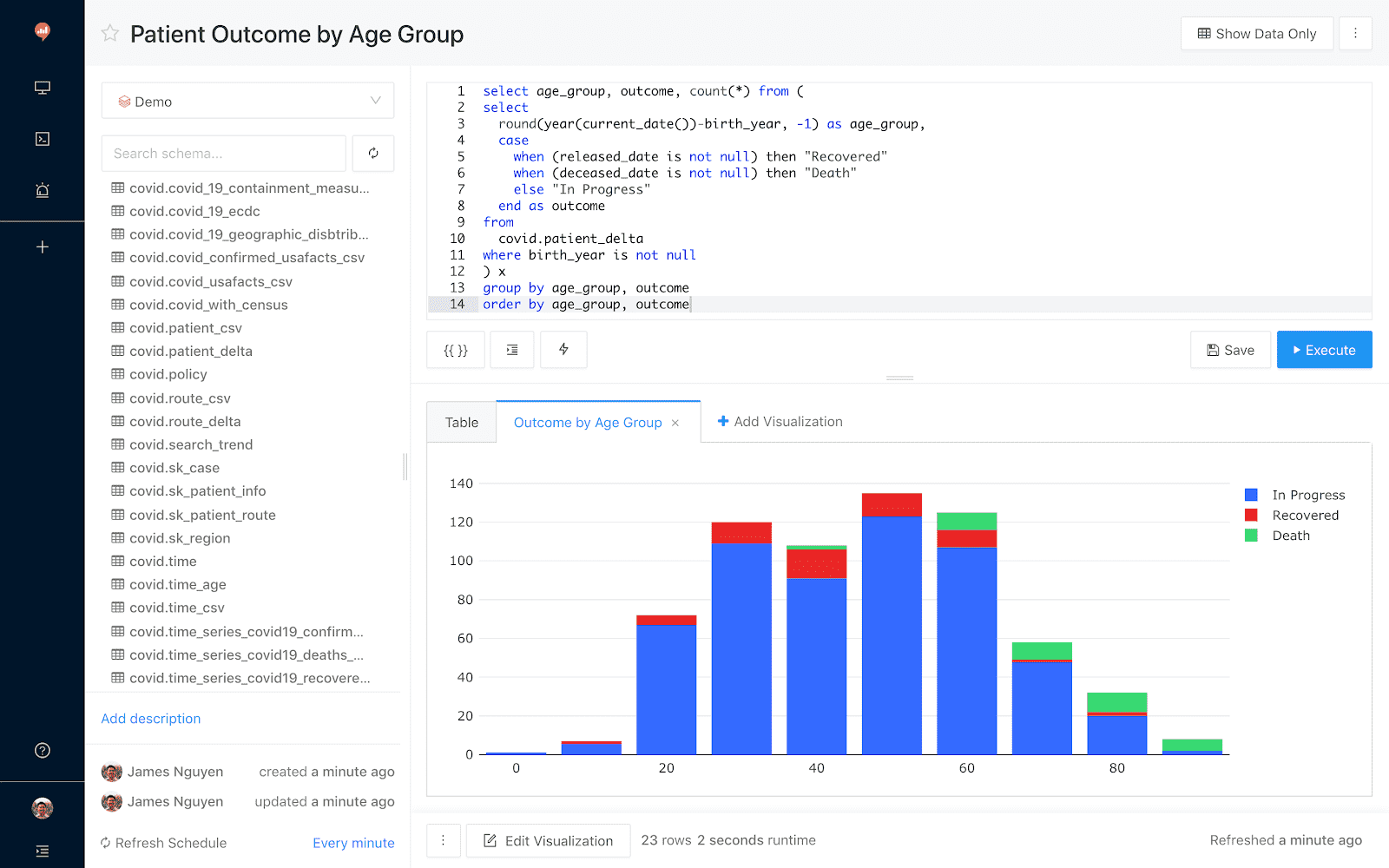
Share live dashboards with collaborators
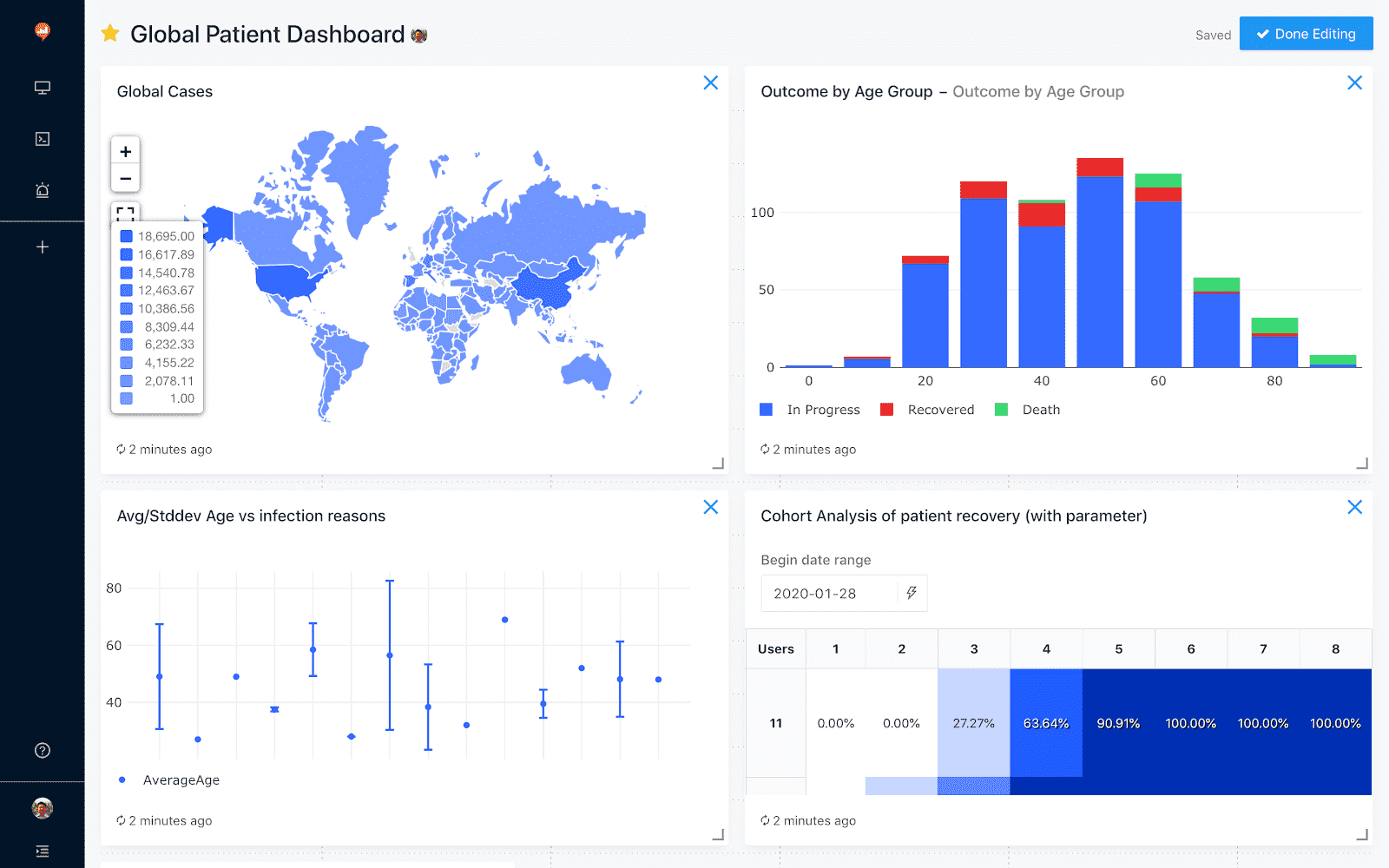
Redash and Databricks
We first heard about Redash a few years ago through some of our early customers. As time progressed, more and more of them asked us to improve the integration between Databricks and Redash. Earlier this year, we invited Arik Fraimovich, Redash’s founder and CEO, to visit Databricks to discuss how we can collaborate and make data easier to consume.
Within the first hour of meeting Arik, it became very obvious to us that the two companies have so much in common. Our acquisition of Redash was driven not only by the great community and product they’ve developed, but also the same core values we share. Both our organizations have sought to make it easy for data practitioners to collaborate around data, and democratize its access for all teams. Most importantly though, has been the alignment of our cultures to help data teams solve the world’s toughest problems with open technologies.
We’re excited to welcome Arik and the Redash team to Databricks, and to further develop Redash together and deliver a seamless and more powerful experience for our customers and the broader open source communities.
Manage, use, and now consume data with a single platform
The new integrated Redash service gives SQL analysts a familiar home in Databricks, and gives data scientists and data engineers a place to easily query and visualize data in Delta Lakes and other data sources.
It seamlessly integrates with the existing Databricks platform: this service will be available in all data centers Databricks operate in; identity management and data governance are unified without additional configuration; SQL endpoints are automatically populated in Redash; catalogs and metadata are shared by two products.
And most importantly, for customers who are already using the two products: shift+enter (the keyboard shortcut to execute a query in Databricks) will also now function the same way in Redash! :)
Creating an open, unified platform for all data teams
Our vision at Databricks has been to deliver a unified data analytics platform that can help every data team throughout a company solve the world’s toughest problems -- including data analysts, data engineers, data scientists, and machine learning engineers. By giving each team the tools they need for their own work, while also having a shared platform where they can collaborate, every data team can be successful together. This ultimately helps to deliver on the promise of the lakehouse data management paradigm, by combining the best capabilities of data lakes and data warehouses together, in a unified architecture where every team can work together on the same complete and authoritative source of data.
Again, we’re excited to be bringing this new data visualization and dashboarding experience to our customers. The integrated Redash experience is currently available in private preview, and you can sign up for the private preview waitlist to be the first to try it out.
Read the Redash team’s blog post on redash.io
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.