Announcing Databricks Labs Terraform integration on AWS and Azure
by Serge Smertin and Sri Tikkireddy
We are pleased to announce integration for deploying and managing Databricks environments on Microsoft Azure and Amazon Web Services (AWS) with HashiCorp Terraform. It is a popular open source tool for creating safe and predictable cloud infrastructure across several cloud providers. With this release, our customers can manage their entire Databricks workspaces along with the rest of their infrastructure using a flexible, powerful tool. Previously on the company blog you may have read how we use the tool internally or how to share common building blocks of it as modules.
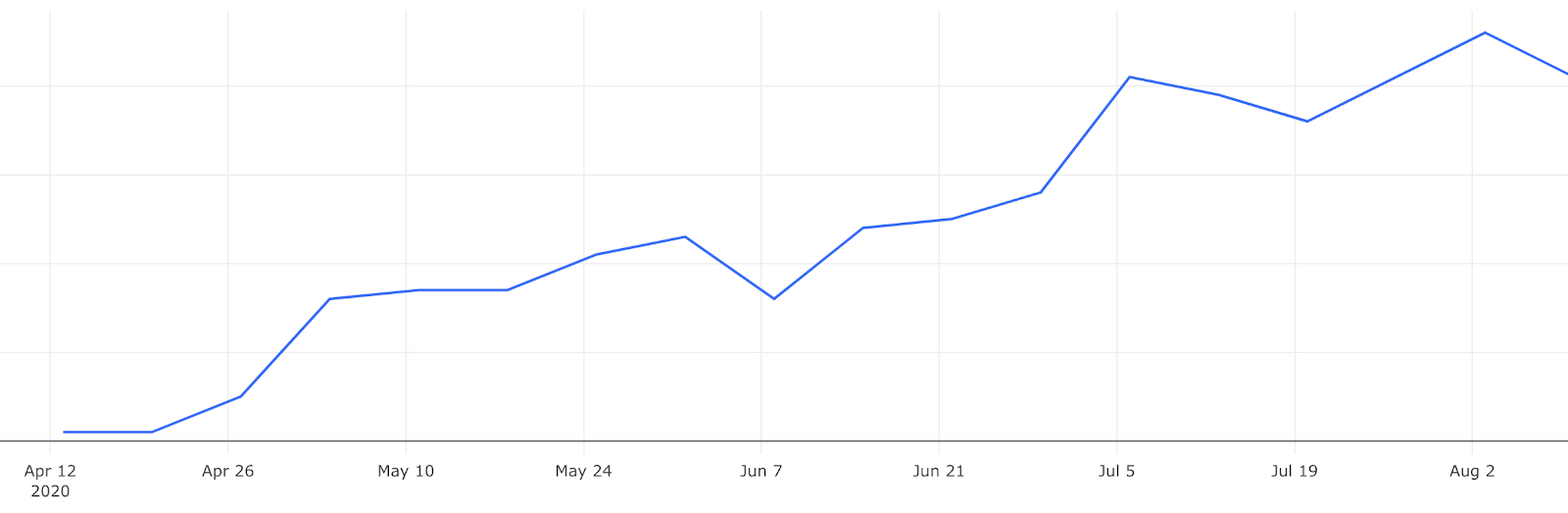
Growing adoption from initial customer base
Few months ago a customer obsessed crew from the Databricks Labs teamed up and started making a Databricks Terraform Provider. Since the very start we’ve been seeing a steady increase in usage of this integration by a number of different customers.
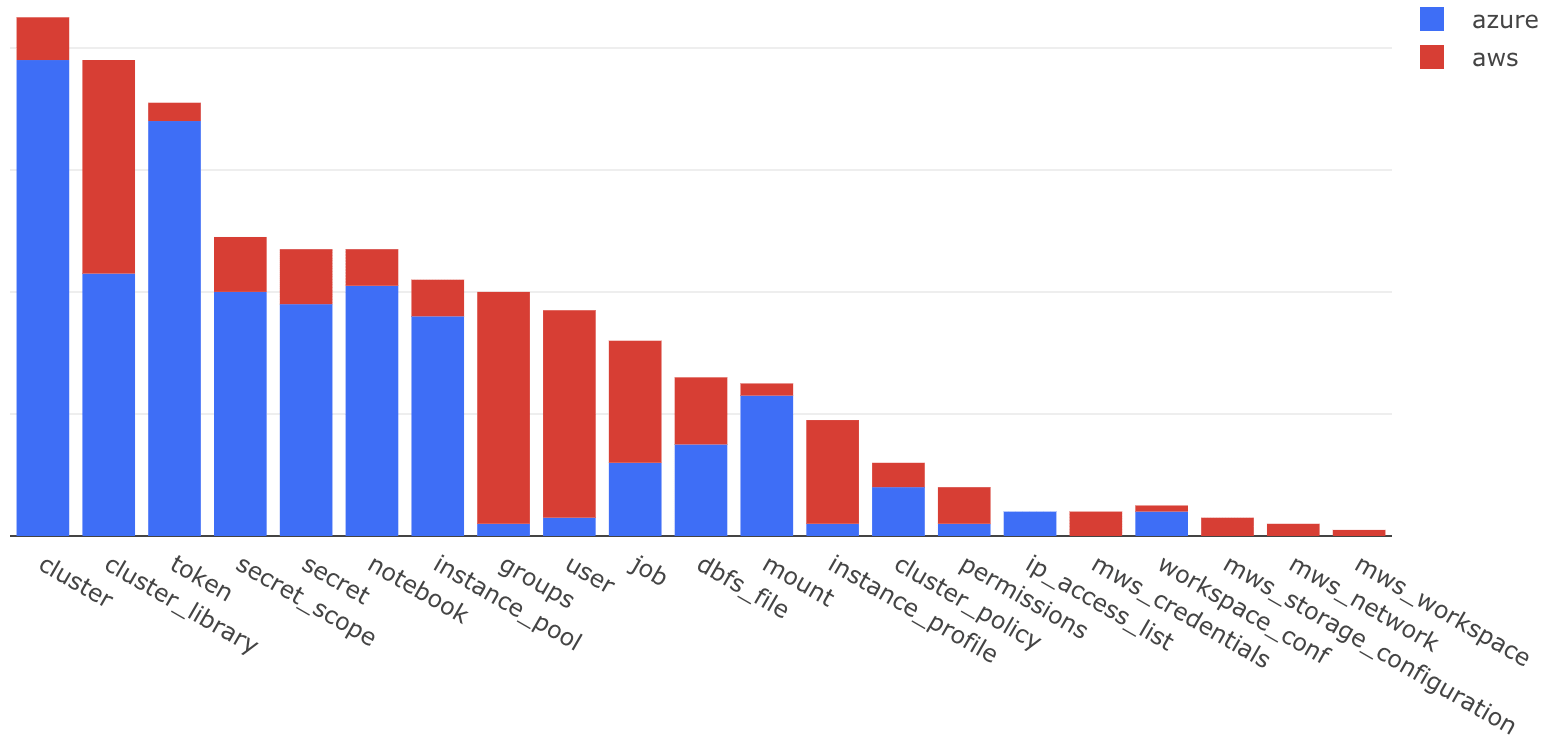
Overall resource usage from all clouds
The aim of this provider is to support all Databricks APIs on Azure and AWS. This allows the Cloud Infrastructure Engineers to automate the most complicated things about their Data & AI platforms. Vast majority of the initial user group is using this provider to set up their clusters and jobs. Customers are also using it to provision workspaces on AWS and configure data access. Workspace setup resources are usually used only in the beginning of deployment setup along with virtual network setup.
Controlling compute resources and monetary spend
From a compute perspective, the provider makes it simple to create a cluster for interactive analysis or a job to run production workload with guaranteed installation of libraries. It’s also quite simple to create and modify an instance pool with potentially reserved instances, so that your clusters can start up x-times quicker and cost you less $$$.
Managing the cost of compute resources in Databricks data science workspaces is a top concern for Platform admins. And for large organisations, managing all of these compute resources across multiple workspaces comes with a bit of overhead. To address those, the provider makes it easier to create scalable cluster management using cluster policies and the Hashicorp Configuration Language (HCL).
Controlling data access
From a workspace security perspective, administrators can configure different groups of users with different access rights and even add users. General recommendation is to let Terraform manage groups including their workspace and data access rights, leaving group membership management to Identity Provider with SSO or SCIM provisioning.
For the sensitive data sources, one should create secret scopes to store the external API credentials in a secure manner. The secrets are redacted by default in the notebooks, and one could also manage access to those using access control lists. If you already use Hashicorp Vault, AWS Secrets Manager or Azure Key Vault, you can populate Databricks secrets from there and have them be usable for your AI and Advanced Analytics use cases. If you have workspace security enabled, permissions can be the single source of truth for managing user or group access to clusters (and their policies), jobs, instance pools, notebooks and other Databricks objects.
From a data security perspective, one could manage AWS EC2 instance profiles in a workspace and assign those to only relevant groups of users. The key thing to note here is that you can define all of these cross platform components (AWS & Databricks) in the same language and code base where Terraform manages the intricate dependencies.
The integration also facilitates mounting of object storage within workspace into “normal” file system for the following storage types:
- AWS Simple Storage Service
- Azure Blob Storage
- Azure Data Lake Storage v2 (also previous generation of it)
Managing workspaces
It is possible to create Azure Databricks workspaces using azurerm_databricks_workspace (this resource is part of the Azure provider that’s officially supported by Hashicorp). Customers interested in provisioning a setup conforming to their enterprise governance policy could follow this working example with Azure Databricks VNet injection.
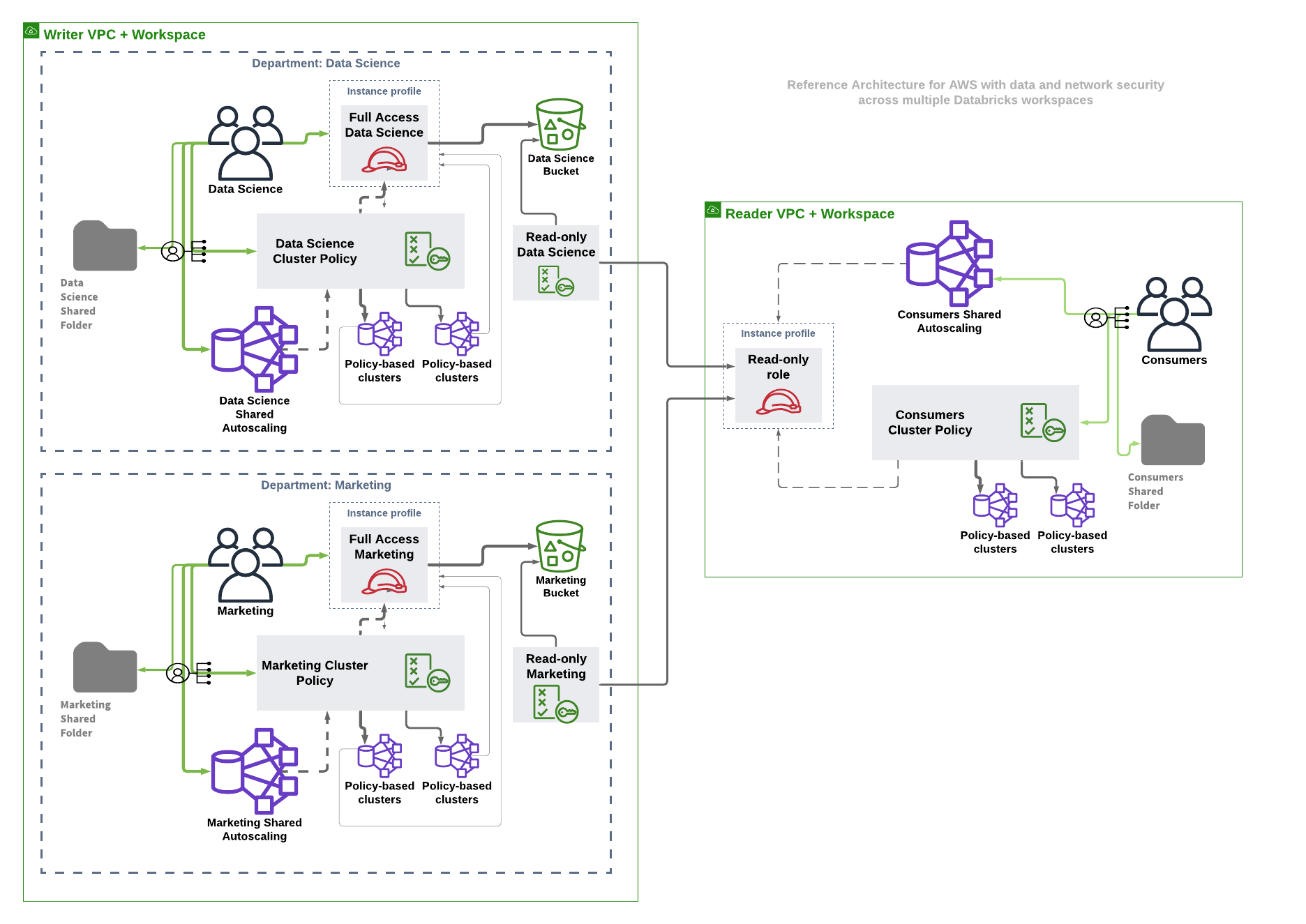
With general availability of the E2 capability, our AWS customers can now leverage enhanced security features and create workspaces within their own fully managed VPCs. Customers can configure a network resource which defines the subnets and security groups within the existing VPC. Then could then create a cross-account role and register it as a credentials resource to grant Databricks relevant permissions to provision compute resources within the provided VPC. A storage configuration resource could be used to configure the root bucket.
Please follow this complete example with a new VPC and new workspace setup. Please pay special attention to the fact that there are two different instances of the Databricks provider - one for deploying workspaces (with host=https://accounts.cloud.databricks.com/login) and another for managing Databricks objects within the provisioned workspace. If you would like to manage provisioning of workspaces as well as clusters within that workspace in the same terraform module (essentially same directory), you should use the provider aliasing feature of Terraform. We strongly recommend having separate terraform modules for provisioning of the workspace including generating the initial PAT token, and managing resources within the workspace. This is due to the fact that Databricks APIs are nearly the same across all cloud providers but workspace creation may be cloud specific. Once the PAT token has been created after the workspace provisioning, that could be used in other modules to provision relevant objects within the workspace.
Provider quality and support
Provider has been developed as part of the Databricks Labs initiative and has an established issue tracking through Github. Pull requests are always welcome. Code is undergoing heavy integration testing each release and has got significant unit test code coverage. The goal is also to make sure every possible Databricks resource and data source definition is documented.
We extensively test all of the resources for all of the supported cloud providers through a set of integration tests before every release. We mainly test with Terraform 0.12, though soon we’ll switch to testing with 0.13 as well.
What’s Next?
Stay tuned for related blog posts in future. You can also watch on demand our webinar discussing how to Simplify, Secure, and Scale your Enterprise Cloud Data Platform on AWS & Azure Databricks in an automated way.
Read more
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.