Detecting Criminals and Nation States through DNS Analytics
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
Quick link to the accelerator notebooks referenced through this post.
You are a security practitioner, a data scientist or a security data engineer; you've seen the Large Scale Threat Detection and Response talk with Databricks . But you're wondering, "how can I try Databricks in my own security operations?" In this blog post, you will learn how to detect a remote access trojan using passive DNS (pDNS) and threat intel. Along the way, you'll learn how to store, and analyze DNS data using Delta, Spark and MLFlow. As you well know, APT's and cyber criminals are known to utilize DNS. Threat actors use the DNS protocol for command and control or beaconing or resolution of attacker domains. This is why academic researchers and industry groups advise security teams to collect and analyze DNS events to hunt, detect, investigate and respond to threats. But you know, it's not as easy as it sounds.

Detecting AgentTeslaRAT with Databricks
Using the notebooks on this solution accelerator, you will be able to detect the Agent Tesla RAT. You will be using analytics for domain generation algorithms (DGA), typosquatting and threat intel enrichments from URLhaus. Along the way you will learn the Databricks concepts of:
- Data ingestion
- Ad hoc analytics
- How to enrich event data, such as DNS queries
- Model building and
- Batch and Streaming analytics
Why use Databricks for this? Because the hardest thing about security analytics aren't the analytics. You already know that analyzing large scale DNS traffic logs is complicated. Colleagues in the security community tell us that the challenges fall into three categories:
- Deployment complexity: DNS server data is everywhere. Cloud, hybrid, and multi-cloud deployments make it challenging to collect the data, have a single data store and run analytics consistently across the entire deployment.
- Tech limitations: Legacy SIEM and log aggregation solutions can't scale to cloud data volumes for storage, analytics or ML/AI workloads. Especially, when it comes to joining data like threat intel enrichments.
- Cost: SIEMs or log aggregation systems charge by volume of data ingest. With so much data SIEM/log licensing and hardware requirements make DNS analytics cost prohibitive. And moving data from one cloud service provider to another is also costly and time consuming. The hardware pre-commit in the cloud or the expense of physical hardware on-prem are all deterrents for security teams.
In order to address these issues, security teams need a real-time data analytics platform that can handle cloud-scale, analyze data wherever it is, natively support streaming and batch analytics and, have collaborative, content development capabilities. And… if someone could make this entire system elastic to prevent hardware commits… now wouldn't that be cool!
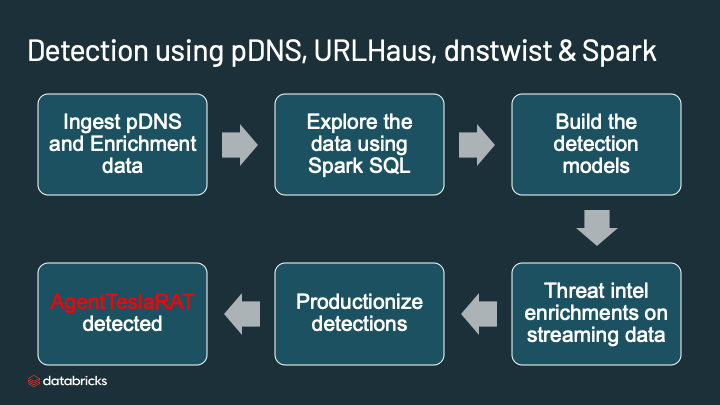
You can use this notebook in the Databricks community edition or in your own Databricks deployment. There are lot of lines here but the high level flow is this:
- Read passive DNS data from AWS S3 bucket
- Specify the schema for DNS and load the data into Delta
- Explore the data with string matches
- Build the DGA detection model. Build the typosquatting model.
- Enrich the output of the DGA and typosquatting with threat intel from URLhaus
- Run the analytics and detect the AgentTesla RAT
Each section of the notebook has comments. We invite you to email us: cybersecurity@databricks.com or submit issues on the Github repo. We look forward to your questions and suggestions for making this notebook easier to understand and deploy.
Now, we invite you, to log in to the community edition or your own Databricks account and run this notebook series. We look forward to your feedback and suggestions.
You can create a community edition account by going to this link. Then you can import the notebook:
- Go to databricks community edition
- In the left navigation, click on workspace
- Right click in the whitespace of workspace pane, and click import
- Select, Import from URL
- Paste this link in the URL field
Please refer to the docs for detailed instructions on importing the notebook to run.
Quick link to the accelerator notebooks referenced through this post
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.