Announcing Single-Node Clusters on Databricks
by Lu Wang, Edward Gan, Andy Zhang and Clemens Mewald
Databricks is used by data teams to solve the world's toughest problems. This can involve running large-scale data processing jobs to extract, transform, and analyze data. However, it often also involves data analysis, data science, and machine learning at the scale of a single machine, for instance using libraries like scikit-learn. To streamline these single machine workloads, we are happy to announce native support for creating single-node clusters on Databricks.
Background and motivation
Standard Databricks Spark clusters consist of a driver node and one or more worker nodes. These clusters require a minimum of two nodes -- a driver and a worker -- in order to run Spark SQL queries, read from a Delta table, or perform other Spark operations. However, for many machine learning model training or lightweight data workloads, multi-node clusters are unnecessary.
Single-node clusters are a cost-efficient option for single machine workloads. Single-node clusters support Spark and Spark data sources including Delta, as well as libraries including scikit-learn and tensorflow included in the Runtime for Machine Learning.
For instance, suppose one wanted to train a scikit-learn machine learning model on a Delta table containing the UCI adult census dataset. This relatively small dataset (Pandas dataframe, and used for training a scikit-learn model on a single machine. Spark SQL queries also scale down well to a single-node cluster, as seen in a previous blog post benchmarking Spark on a single machine.
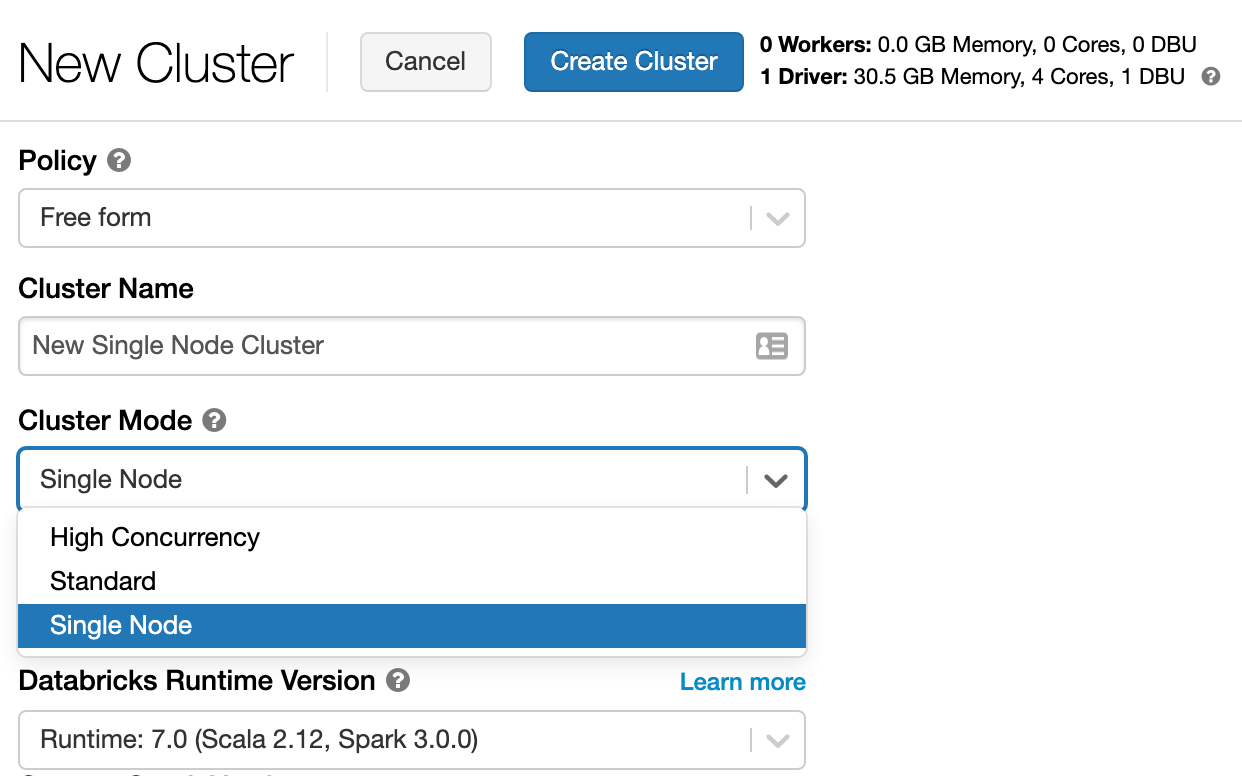
Creating Single-Node Clusters
Single node clusters are now available in Public Preview as a new cluster mode in the interactive cluster creation UI. Selecting this mode will configure the cluster to launch only a driver node, while still supporting spark jobs in local mode on the driver.
To further simplify the cluster creation process, administrators can also create cluster policies for single node cluster creation. Using these policies, users can then launch single node clusters with zero additional configuration and subject to budget controls. For more details including example single node cluster policies see the user guide. In the video below we illustrate how if a cluster administrator has set up single node policies, users can create pre-configured single node clusters by directly selecting the policy.
Learn more about single-node clusters and start using them today
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.