Why Cloud Centric Data Lake is the future of EDW
by Parth Vakil and Franco Patano
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
In this first of two blogs, we want to talk about WHY an organization might want to look at a lakehouse architecture (based on Delta Lake) for their data analytics pipelines instead of the standard patterns of lifting and shifting their Enterprise Data Warehouse (EDW) from on-prem or in the cloud. We will follow this case with a second detailed blog on HOW to make just such a transition shortly.
Enterprise Data Warehouse
Enterprise Data Warehouses have stood the test of time in organizations. They deliver massive business value. Businesses need to be data driven and want to glean insights from their data and EDWs are proven work horses to do just that.
However, as time has gone along, there have been several issues identified in the EDW architecture. Broadly speaking these issues can be attributed to the four characteristics of big data, commonly known as the “4 Vs” or volume, velocity, variety, and veracity that are problematic for legacy architectures. The following reasons further illustrate limitations of an EDW based architecture:
- Legacy, non-scalable architecture: Over time, architects and engineers have gotten crafty with performant database technologies, and have turned to data warehousing as a complete data strategy. Pressured to get creative with existing tooling, the database has been used to solve more complex solutions that it was not originally intended for. This has caused anti-patterns to proliferate from on-prem to the cloud. Oftentimes, when these workloads are migrated, cloud costs skyrocket - from infrastructure, to resources required for the management and implementation to time it takes to derive value. This leaves everyone questioning this “cloud” strategy.
- Variety of Data: The good old days of managing just structured data are over. Today, data management strategies have to account for semi structured text, JSON, and XML documents, as well as unstructured data like, audio, video and binary files. When deciding on technology for the cloud, you have to consider a platform that is able to handle data of all types, not just the structured data that feeds monthly reports.
- Velocity of Data: Data Warehousing provided a paradigm shift where we would have the ETL processing happen overnight, where our business aggregates would compute, and business partners would have their fresh data first thing in the morning. The requirements and needs of businesses are rapid and increasing. In such a scenario to conform to daily loads becomes an execution risk. It is imperative to have an always updated data store for analytics, AI and decision making.
- Data Science: At first a 2nd class citizen in the siloed data ecosystem of yesterday, organizations are now finding that they need to pave the way for data scientists to do what they do best. Data Scientists need access to as much data as possible. A big part of training a model is selecting the most predictive fields from the raw data, which aren't always present in the Data Warehouse. A data scientist would not be able to identify which data to include in the warehouse without first analyzing it.
- Proliferation of Data: Given the rate of change of business operations today, we require more changes to our data models, and changing the data warehouse can become costly. Alternatively, the use of data marts, extract tables, and desktop databases have fractured the data ecosystem in modern enterprises, causing fractured views of the business. Further still, this model requires capacity planning that looks out 6 months or longer. In the cloud, this design principle translates to significant cost.
- Cost Per Column: In the traditional EDW world, the coordination and the planning required to yield a new column in the schema is substantial. This impacts two things - the cost and the lost time to value (i.e. decisions being made when the column is unavailable). An organization ought to look at the flexibility of a cloud data lake that reduces this cost (and time) significantly leading to desired outcomes faster.
- ETL vs ELT: In an on-prem world you either pay to have ETL servers idle for most of the day; or you have to be careful in scheduling your ELT jobs against BI workloads in a Data Warehouse. In the cloud you have a choice - follow the same trend (i.e. perform ELT and BI in a Data warehouse) or switch to ETL. With ETL in the cloud you only pay for the infrastructure when your transformations run. And, you should pay a much lower price to execute those transformations. This segmentation of workloads also allows for efficient computation to support high throughput and streaming data. Overall, ETL in cloud can offer an organization tremendous cost and performance benefits.

Figure 1: Typical flow in the EDW world and its limitations
So, really, as a result of these challenges, the requirements became clearer for the EDW community:
- Must ingest ALL data, i.e. structured, semi structured and unstructured
- Must ingest ALL data at all velocities, i.e. monthly, weekly, daily, hourly, even every second (i.e. streaming) while evolving schema and preventing expensive, time consuming modifications
- Must ingest ALL data and by this we mean the entire volume of data
- Must ingest ALL of this data reliably - failed jobs up stream should not corrupt data downstream
- It is NOT enough to simply have this data available for BI. The organization wants to leverage all of this data to have the edge against competition and be predictive and ask not just “what happened” but also “what will happen”
- Must segment computation intelligently to achieve results with optimal costs instead of over provisioning for the “just in case” situations.
- Do all of this while eliminating copies of data, replication issues, versioning problems and, possibly, governance issues
Simply put - the architecture must support all velocity, variety and volume of data, enable business intelligence and production grade data science at optimal cost.
Now, if we start talking about a Cloud Data Lake architecture the one major thing that this brings to the table for the organization is extremely cheap storage. When you think about Azure Blob or Azure Data Lake Gen2 as well as AWS S3, you can store TB scale data for a few dollars. This frees the organization from being beholden to analytics apparatus where the disk storage costs are many multiples of that. BUT, this only happens, if the organization takes advantage of separating compute from storage. By this we mean that the data must persist separately from your compute infrastructure. In nominal terms, on AWS, your data would reside on S3 (or ADLS Gen2/Blob on Azure) while your compute would spin up as and when required.
With that in mind, let us take a look at the architecture for a modern cloud data lake architecture
- All of your data sources can land in one of these cheap object stores on your preferred cloud whether it is structured, unstructured or semi structured
- Now, you build a curated data lake on top of this raw data just landing on the storage tier
- And, on top of this curated data lake, you build out exploratory data science, production ML as well as SQL/BI
For this curated data lake, we want to focus on things that an organization has to think about in building this layer to avoid the pitfalls of the data lakes of yesteryear. In those there was a strong notion of “garbage in garbage out”. One of the key reasons for that property in the data lakes of the past was because of the reliability of data. Data could land with the wrong schema, could be corrupted etc. and it would just get ingested into the data lake. Only later, when that data is queried do the problems really arise. So reliability is a major requirement to think about.
Another one that matters, of course, is performance. We could play a lot of tricks to make the data reliable, but it is no good if a simple query takes forever to return.
Yet another one that matters is that, as an organization, you might start to think about data in levels of curation. You might have a raw tier, a refined tier and a BI tier. Generally, raw tier is your incoming data, the refined tier is imposing requirements of schema enforcement and reliability checks and the BI tier has clean data with aggregations ready to build out dashboards for executives. We also need to think about a process to move between these tiers in a simplistic way.
Also we want to keep compute and storage separate - and the reason we want to do this is because in the cloud compute costs can weigh heavily on the organization. You want to store it on the object store giving you a cheap persistent layer. Bring your compute to the data for only as long as you need it and then turn it off. As an example, bring up a very large cluster to perform ETL against your data for a few minutes and shut it off after the process is done. On the query side, you can keep ALL of your data going back decades on S3 and bring up a small cluster in the case you only need to query the last few years. This flexibility is of paramount importance. What this really implies is that the reliability and performance we are talking about have to be inherent properties of how the data is stored.
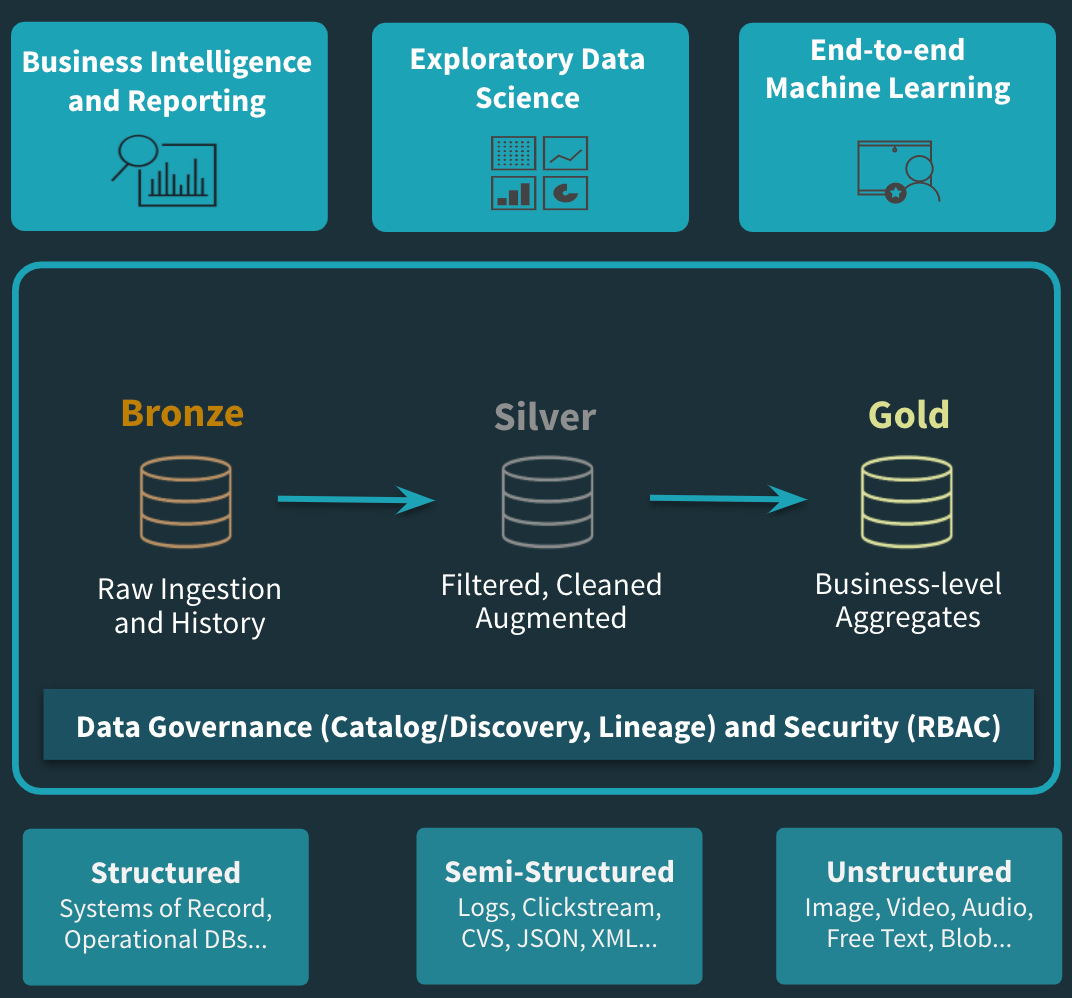
Figure 3: A Cloud Curated Data Lake architecture
So, say we have a data format for this curated Data Lake layer that gives us inherent reliability and performance properties coupled with the fact that the data stays completely under the organization’s control, you now need a query engine that allows you to access this format. We think the choice here, at least for now, is Apache Spark. Apache Spark is battle tested, supports ETL, streaming, SQL and ML workloads.
So, this data format, from a Databricks perspective, is Delta Lake. Delta Lake in an open source format that is maintained by the Linux Foundation. There are others you will hear about as well - Apache Hudi and Iceberg. They are trying to solve for the reliability property required on the data lake. The big difference, however, is that at this point, Delta Lake processes 2.5 exabytes per month. It is a battle tested data format for the cloud data lake amongst Fortune 500 companies and being leveraged across all verticals from financial services, to ad tech to automotive and public sector.
Delta Lake coupled with Spark gives you the capability to move easily between the data lake curation stages. In fact, you could incrementally ingest incoming data in raw tier and be assured to see it move through the transformation stages all the way through to the BI tier with ACID guarantees.
We at Databricks realize that this is the vision a lot of the organizations are looking to implement. So, when you look at Databricks as a Unified Data Analytics Platform, what you see is:
- An open, unified data service - we are the original creators of several open source projects, including Apache Spark, MLflow, and Delta Lake. Their capabilities are deeply integrated into our product.
- We cater to the data scientist via a collaborative workspace environment.
- We enable and, in fact, accelerate the process of productionizing ML via an end-to-end ML workflow to train, deploy, and manage models.
- And on the SQL/BI side, we provide a native SQL interface enabling the data analyst to directly query the data lake using a familiar interface. We have also optimized data lake connectivity with popular no-code BI tools like Tableau.
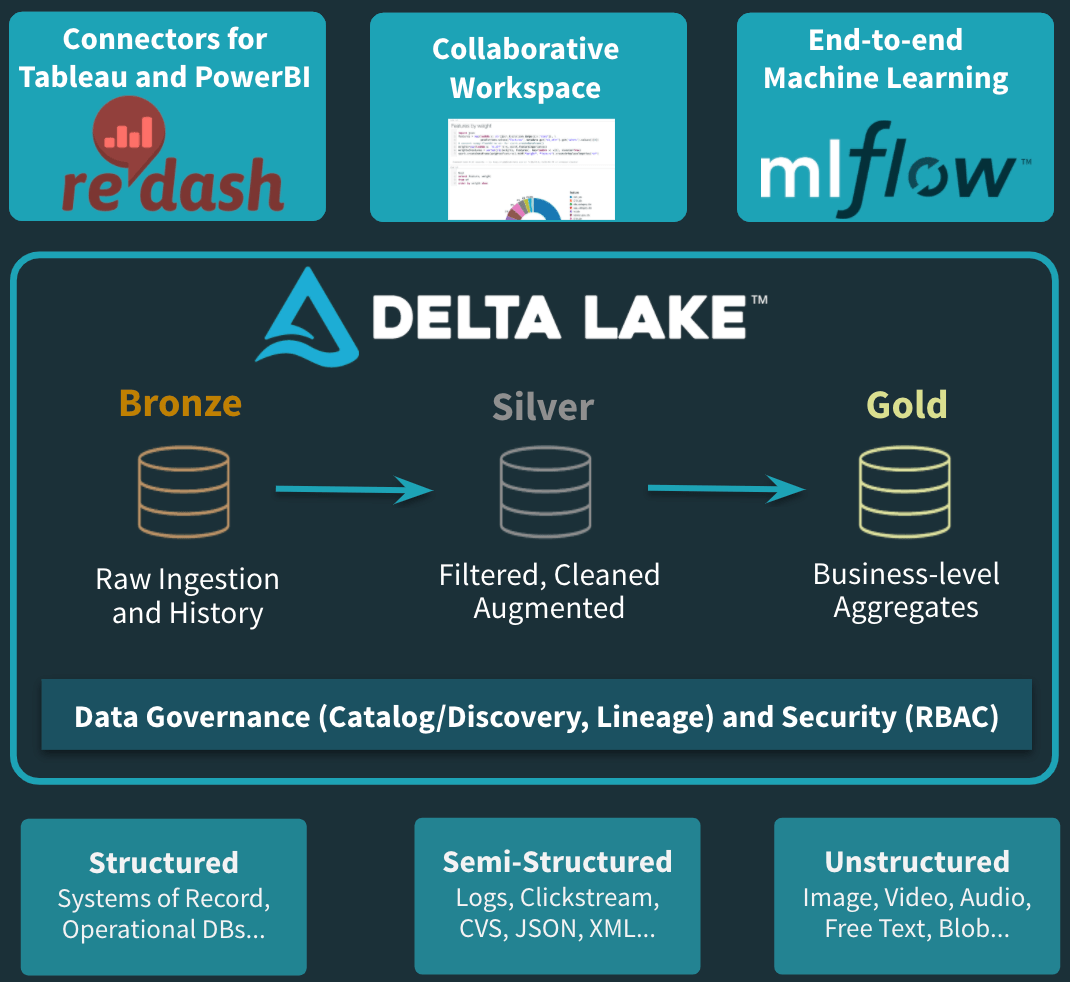
Figure 5: A Databricks centric Curated cloud Data Lake solution
What’s Next
We will follow this blog on WHY you should consider a Data Lake as you look to modernize in the cloud with a HOW blog. We will focus on specific aspects to think of and know about as you orient yourself from a traditional Data warehouse to a Data Lake.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.