Improving the Spark Exclusion Mechanism in Databricks
by Tianhan Hu, Xingbo Jiang and Xiao Li
Ed Note: This article contains references to the term blacklist, a term that the Spark community is actively working to remove from Spark. The feature name will be changed in the upcoming Spark 3.1 release to be more inclusive, and we look forward to this new release.
Why Exclusion?
The exclusion mechanism was introduced for task scheduling in Apache Spark 2.2.0 (as "blacklisting"). The motivation for having exclusion is to enhance fault tolerance in Spark, especially against the following problematic scenario:
- In a cluster with hundreds or thousands of nodes, there is a decent probability that executor failures (eg. I/O on a bad disk) happen on one of the nodes during a long-running Spark application — and this can lead to task failure.
- When a task failure happens, there is a high probability that the scheduler will reschedule the task to the same node and same executor because of locality considerations. Now, the task will fail again.
- After failing
spark.task.maxFailuresnumber of times on the same task, the Spark job would be aborted.
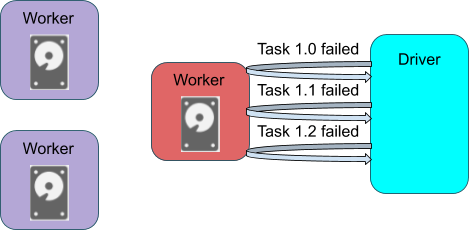
Figure 1. A task fails multiple times on a bad node
The exclusion mechanism solves the problem by doing the following. When an executor/node fails a task for a specified number of times (determined by the config spark.blacklist.task.maxTaskAttemptsPerExecutor and spark.blacklist.task.maxTaskAttemptsPerNode), the executor/node would be blocked for the task, and would not receive the same task again. We also count the number of failures of executors/nodes on a stage/application level, and block them for the entire stage/application when the number exceeds the threshold (determined by the config spark.blacklist.application.maxFailedTasksPerExecutor and spark.blacklist.application.maxFailedExecutorsPerNode). Executors and nodes in an application-level exclusion will be released out of the exclusion after a timeout period (determined by spark.blacklist.timeout).
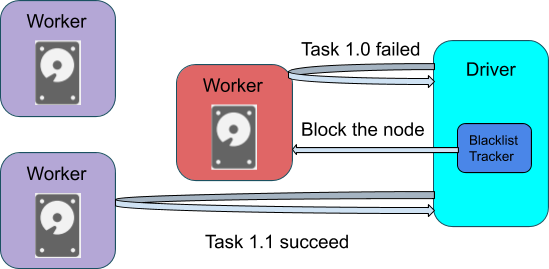
Figure 2. A task succeed after excluding the bad node
Deficiencies in the exclusion mechanism
The exclusion mechanism introduced in Spark 2.2.0 has the following shortcomings that forbid it from being enabled for the user by default.
- Exclusion mechanisms never actively decommission nodes. The excluded nodes would just sit idle, and contribute nothing to task completion.
- When there are transient and frequent task failures, many nodes will be added to the exclusion list, thus a cluster quickly gets into a scenario where no worker node can be used.
- Exclusion mechanism can not be enabled only for shuffle-fetch failures.
New features introduced in Databricks Runtime 7.3
In Databricks Runtime 7.3, we improved the Spark exclusion mechanism by implementing the following features.
Enable Node Decommission for Exclusion
In a scenario where some nodes are having permanent failures, all the old exclusion mechanism can do is to put them into application level exclusion list, take them out for another try after a timeout period, and then put them back in. The nodes would be sitting idle, contributing to nothing, and they stay bad.
We address this problem by adding a configuration called spark.databricks.blacklist.decommissionNode.enabled. If spark.databricks.blacklist.decommissionNode.enabled is set to true, when a node is excluded on the application level, it will be decommissioned, and a new node would be launched to keep the cluster to its desired size.
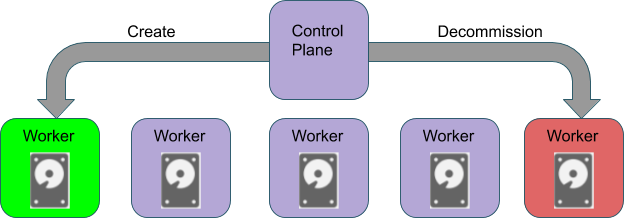
Figure 3. Decommission the bad node, add create new healthy node
Exclusion Threshold
In Databricks Runtime 7.3, we introduced the feature of thresholding to the exclusion mechanism. By tuning spark.blacklist.application.blacklistedNodeThreshold (default to INT_MAX), users can limit the maximum number of nodes excluded at the same time for a Spark application.
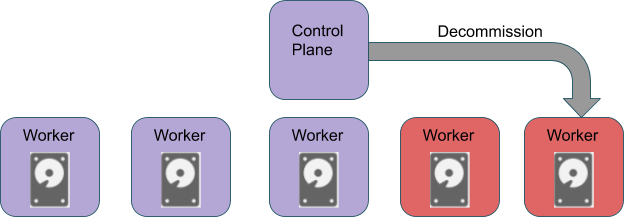
Figure 4. Decommission the bad node until the exclusion threshold is reached
Thresholding is very useful when the failures in a cluster are transient and frequent. In such a scenario, an exclusion mechanism without thresholding is at risk of sending all executors and nodes into application level exclusion, and leaving the user with no resources to use until new healthy nodes are launched.
As shown in Figure 4, we only decommission bad nodes until the exclusion threshold is reached. Thus, with the threshold properly configured, a cluster will not enter the situation that it can only utilize far less worker nodes than expected. Also, as the old bad nodes are replaced by the new healthy nodes, we can still replace the remaining bad nodes in the cluster gradually.
Independent enabling for FetchFailed errors
FetchFailed errors occur when a node fails to fetch a shuffle block from another node. In this case, it is possible that the node being fetched from is having a long-lasting failure, and many tasks would be affected, and fail due to fetch failures. Therefore, we see exclusion for FetchFailed errors as a special case in the exclusion mechanism due to its large impact.
In Spark 2.2.0, exclusion for FetchFailed errors could only be used when general exclusion is enabled (e.g. spark.blacklist.enabled is set to true). In Databricks Runtime 7.3, we made enablement for FetchFailed errors independent.
Now, the user can set spark.blacklist.application.fetchFailure.enabled alone to enable exclusion for FetchFailed errors.
Conclusion
The improved exclusion mechanism is better integrated with the control plane, it gradually decommissions the excluded nodes. As a result, the bad nodes are recycled and replaced by new healthy nodes, thus reduces the task failures caused by bad nodes, and also saves the cost spent on bad nodes. Get started today and try out the improved exclusion mechanism in Databricks Runtime 7.3.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.