Simplify Access to Delta Lake Tables on Databricks From Serverless Amazon Redshift Spectrum
by Naseer Ahmed and Igor Alekseev
This post is a collaboration between Databricks and Amazon Web Services (AWS), with contributions by Naseer Ahmed, senior partner architect, Databricks, and guest author Igor Alekseev, partner solutions architect, AWS. For more information on Databricks integrations with AWS services, visit https://www.databricks.com/product/aws
Amazon Redshift recently announced support for Delta Lake tables. In this blog post, we'll explore the options to access Delta Lake tables from Spectrum, implementation details, pros and cons of each of these options, along with the preferred recommendation.
A popular data ingestion/publishing architecture includes landing data in an S3 bucket, performing ETL in Apache Spark, and publishing the "gold" dataset to another S3 bucket for further consumption (this could be frequently or infrequently accessed data sets). In this architecture, Redshift is a popular way for customers to consume data. Often, users have to create a copy of the Delta Lake table to make it consumable from Amazon Redshift. This approach doesn't scale and unnecessarily increases costs. This blog's primary motivation is to explain how to reduce these frictions when publishing data by leveraging the newly announced Amazon Redshift Spectrum support for Delta Lake tables.
Get an early preview of O'Reilly's new ebook for the step-by-step guidance you need to start using Delta Lake.
Amazon Redshift Spectrum integration with Delta
Amazon Redshift Spectrum relies on Delta Lake manifests to read data from Delta Lake tables. A manifest file contains a list of all files comprising data in your table. In the case of a partitioned table, there’s a manifest per partition. The manifest file(s) need to be generated before executing a query in Amazon Redshift Spectrum. Creating external tables for data managed in Delta Lake documentation explains how the manifest is used by Amazon Redshift Spectrum. Note, this is similar to how Delta Lake tables can be read with AWS Athena and Presto.
Here’s an example of a manifest file content:
Steps to Access Delta on Amazon Redshift Spectrum
Next we will describe the steps to access Delta Lake tables from Amazon Redshift Spectrum. This will include options for adding partitions, making changes to your Delta Lake tables and seamlessly accessing them via Amazon Redshift Spectrum.
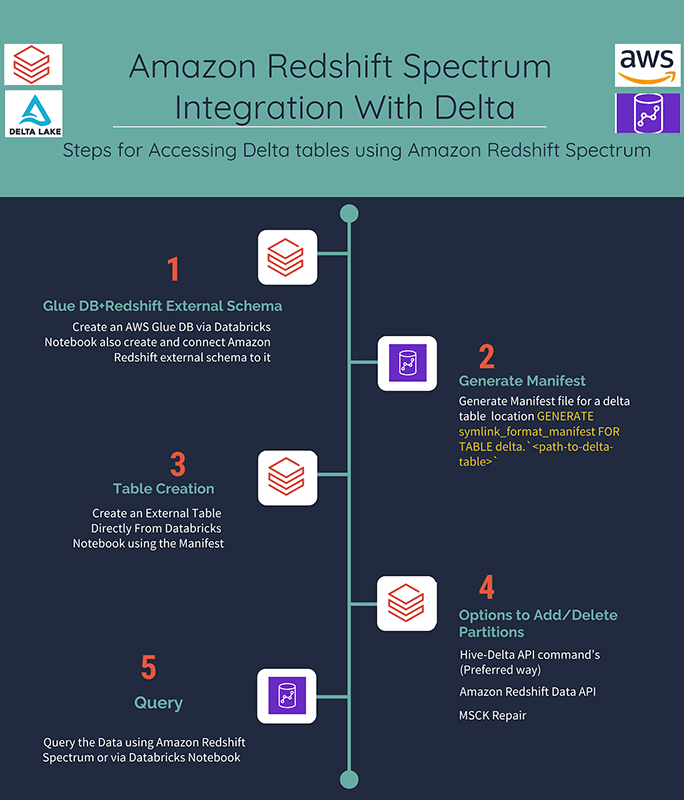
Step 1: Create an AWS Glue DB and connect Amazon Redshift external schema to it
Enable the following settings on the cluster to make the AWS Glue Catalog as the default metastore.
Create glue database :
This will set up a schema for external tables in Amazon Redshift Spectrum.
Step 2: Generate Manifest
You can add the statement below to your data pipeline pointing to a Delta Lake table location.
Note, the generated manifest file(s) represent a snapshot of the data in the table at a point in time. The manifest files need to be kept up-to-date. There are two approaches here. One run the statement above, whenever your pipeline runs. This will update the manifest, thus keeping the table up-to-date. The main disadvantage of this approach is that the data can become stale when the table gets updated outside of the data pipeline.
The preferred approach is to turn on delta.compatibility.symlinkFormatManifest.enabled setting for your Delta Lake table. This will enable the automatic mode, i.e. any updates to the Delta Lake table will result in updates to the manifest files. Use this command to turn on the setting.
This will keep your manifest file(s) up-to-date ensuring data consistency.
Step 3: Create an external table directly from Databricks Notebook using the Manifest
When creating your external table make sure your data contains data types compatible with Amazon Redshift. Note, we didn’t need to use the keyword external when creating the table in the code example below. It’ll be visible to Amazon Redshift via AWS Glue Catalog.
Step 4: Options to Add/Delete partitions
If you have an unpartitioned table, skip this step. Otherwise, let’s discuss how to handle a partitioned table, especially what happens when a new partition is created.
Delta Engine will automatically create new partition(s) in Delta Lake tables when data for that partition arrives. Before the data can be queried in Amazon Redshift Spectrum, the new partition(s) will need to be added to the AWS Glue Catalog pointing to the manifest files for the newly created partitions.
There are three options to achieve this:
- Add partition(s) using Databricks AWS Glue Data Catalog Client (Hive-Delta API),
- Add partition(s) via Amazon Redshift Data APIs using boto3/CLI,
- MSCK repair.
Below, we are going to discuss each option in more detail.
Option 1: Using the Hive-Delta API command’s (preferred way)
Using this option in our notebook we will execute a SQL ALTER TABLE command to add a partition.
Note: here we added the partition manually, but it can be done programmatically. The code sample below contains the function for that. Also, see the full notebook at the end of the post.
Option 2: Using Amazon Redshift Data API
Amazon Redshift recently announced availability of Data APIs. These APIs can be used for executing queries. Note that these APIs are asynchronous. If your data pipeline needs to block until the partition is created you will need to code a loop periodically checking the status of the SQL DDL statement.
Option 2.1 CLI
We can use the Redshift Data API right within the Databricks notebook. As a prerequisite we will need to add awscli from PyPI. Then we can use execute-statement to create a partition. Once executed, we can use the describe-statement command to verify DDLs success. Note get-statement-result command will return no results since we are executing a DDL statement here.
Option 2.2 Redshift Data API (boto3 interface)
Amazon Redshift also offers boto3 interface. Similarly, in order to add/delete partitions you will be using an asynchronous API to add partitions and need to code loop/wait/check if you need to block until the partitions are added.
Option 3. Using MSCK Repair
An alternative approach to add partitions is using Databricks Spark SQL
It’s a single command to execute, and you don’t need to explicitly specify the partitions. There will be a data scan of the entire file system. This might be a problem for tables with large numbers of partitions or files. However, it will work for small tables and can still be a viable solution.
Step 5: Querying the data
Conclusion
In this blog we have shown how easy it is to access Delta Lake tables from Amazon Redshift Spectrum using the recently announced Amazon Redshift support for Delta Lake. By making simple changes to your pipeline you can now seamlessly publish Delta Lake tables to Amazon Redshift Spectrum. You can also programmatically discover partitions and add them to the AWS Glue catalog right within the Databricks notebook.
Try this notebook with a sample data pipeline, ingesting data, merging it and then query the Delta Lake table directly from Amazon Redshift Spectrum.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.