A Step-by-step Guide for Debugging Memory Leaks in Spark Applications
This is a guest authored post by Shivansh Srivastava, software engineer, Disney Streaming Services. It was originally published on Medium.com
Just a bit of context
We at Disney Streaming Services use Apache Spark across the business and Spark Structured Streaming to develop our pipelines. These applications run on the Databricks Runtime(DBR) environment which is quite user-friendly.
One of our Structured Streaming Jobs uses flatMapGroupsWithState where it accumulates state and performs grouping operations as per our business logic. This job kept on crashing approximately every 3 days. Sometimes even less, and then after that, the whole application got restarted, because of the retry functionality provided by DBR environment. If this had been a normal batch job this would have been acceptable but in our case, we had a structured streaming job and a low-latency SLA to meet. This is the tale of our fight with OutOfMemory Exception(OOM) and how we tackled the whole thing.
Below is the 10-step approach we as a department took to solving the problem:
Step 1: Check Driver logs. What’s causing the problem?
If a problem occurs resulting in the failure of the job, then the driver logs (which can be directly found on the Spark UI) will describe why the last retry of the task failed.
If a task fails more than four (4) times (if spark.task.maxFailures = 4 ), then the reason for the last failure will be reported in the driver log, detailing why the whole job failed.
In our case, it showed that the executor died and got disassociated. Hence the next step was to find out why.
Step 2: Check Executor Logs. Why are they failing?
In our executor logs, generally accessible via ssh, we saw that it was failing with OOM.
We encountered two types of OOM errors:
- java.lang.OutOfMemoryError: GC Overhead limit exceeded
- java.lang.OutOfMemoryError: Java heap space.
Note: JavaHeapSpace OOM can occur if the system doesn’t have enough memory for the data it needs to process. In some cases, choosing a bigger instance like i3.4x large(16 vCPU, 122Gib ) can solve the problem.
Another possible solution could be to tune the parameters to ensure consumption of what can be processed. What this essentially means is that enough memory must be available to process the amount of data to be processed in one micro-batch.
Step 3: Check Garbage Collector Activity
We saw from our logs that the Garbage Collector (GC) was taking too much time and sometimes it failed with the error GC Overhead limit exceeded when it was trying to perform the full garbage collection.
According to Spark documentation, G1GC can solve problems in some cases where garbage collection is a bottleneck. We enabled G1GC using the following configuration:
Thankfully, this tweak improved a number of things:
- Periodic GC speed improved.
- Full GC was still too slow for our liking, but the cycle of full GC became less frequent.
- GC Overhead limit exceeded exceptions disappeared.
However, we still had the Java heap space OOM errors to solve. Our next step was to look at our cluster health to see if we could get any clues.
Step 4: Check your Cluster health
Databricks clusters provide support for Ganglia, a scalable distributed monitoring system for high-performance computing systems such as clusters and grids.
Our Ganglia graphs looked something like this:
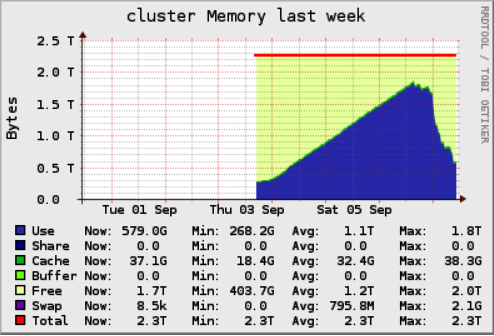
Cluster Memory Screenshot from Ganglia
Worker_Memory Screenshot from Ganglia
The graphs tell us that the cluster memory was stable for a while, started growing, kept on growing, and then fell off the edge. What does that mean?
- This was a stateful job so maybe we were not clearing out the state over time.
- A memory leak could have occurred.
Step 5: Check your Streaming Metrics
Looking at our streaming metrics took us down the path of eliminating the culprits creating the cluster memory issue. Streaming metrics, emitted by Spark, provide information for every batch processed.
It looks something like this:
Note: These are not our real metrics. It's just an example.
Plotting stateOperators.numRowsTotal against event time, we noticed stability over time. Hence it eliminates the possibility that OOM is occurring because of the state being retained.
The conclusion: a memory leak occurred, and we needed to find it. To do so, we enabled the heap dump to see what is occupying so much memory.
Step 6: Enable HeapDumpOnOutOfMemory
To get a heap dump on OOM, the following option can be enabled in the Spark Cluster configuration on the executor side:
Additionally, a path can be provided for heap dumps to be saved. We use this configuration because we can access it from the Databricks Platform. You can also access these files by ssh-ing into the workers and downloading them using tools like rsync.
Step 7: Take Periodic Heap dumps
Taking periodic heap dumps allow for analysis of multiple heap dumps to be compared with the OOM heap dumps. We took heap dumps every 12 hrs from the same executor. Once our executor goes into OOM, we would have at least two dumps available. In our case, executors were taking at least 24 hours to go into OOM.
Steps to take periodic heap dump:
- ssh into worker
- Get Pid using top of the java process
- Get Heapdump jmap -dump:format=b,file=pbs_worker.hprof
- Provide correct permissions to Heapdump file.
sudo chmod 444 pbs_worker.hprof - Download file on your local
./rsync -chavzP --stats
ubuntu@:/home/ubuntu/pbs_worker.hprof .
Step 8: Analyze Heap Dumps
Heap dump analysis can be performed with tools like YourKit or Eclipse MAT.
In our case, heap dumps were large — in the range of 40gb or more. The size of the heap dumps made it difficult to analyze. There is a workaround that can be used to index the large files and then analyze them.
Step 9: Find where it is leaking memory by looking at Object Explorer
YourKit provides inspection of hprof files. If the problem is obvious, it will be shown in the inspection section. In our case, the problem was not obvious.
Looking at our heap histogram, we saw many HashMapNode instances, but based on our business logic, didn’t deem the information too concerning.
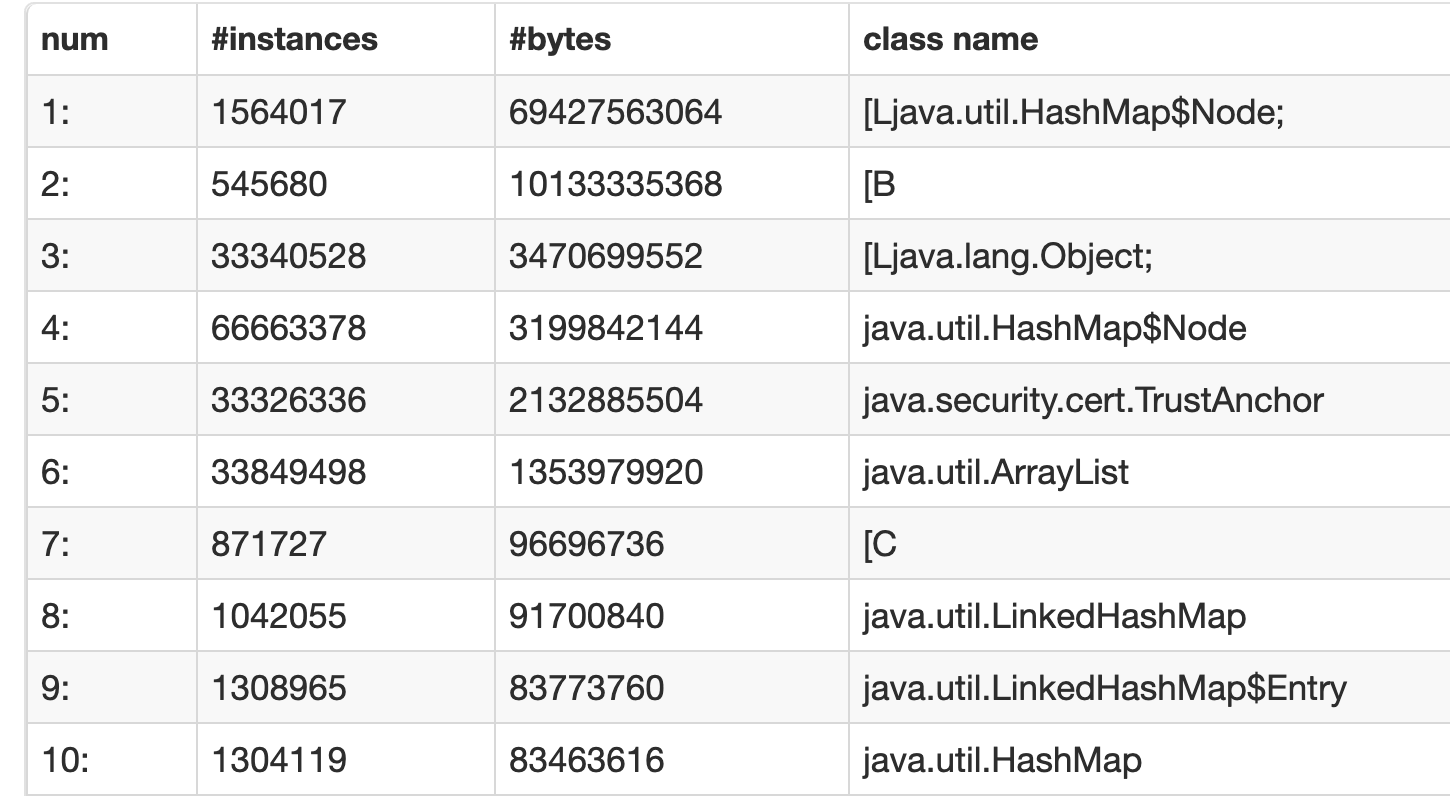
HeapHistogram Screenshot from Spark UI
When we looked at the class and packages section in YourKit, we found the same results; as we had expected.
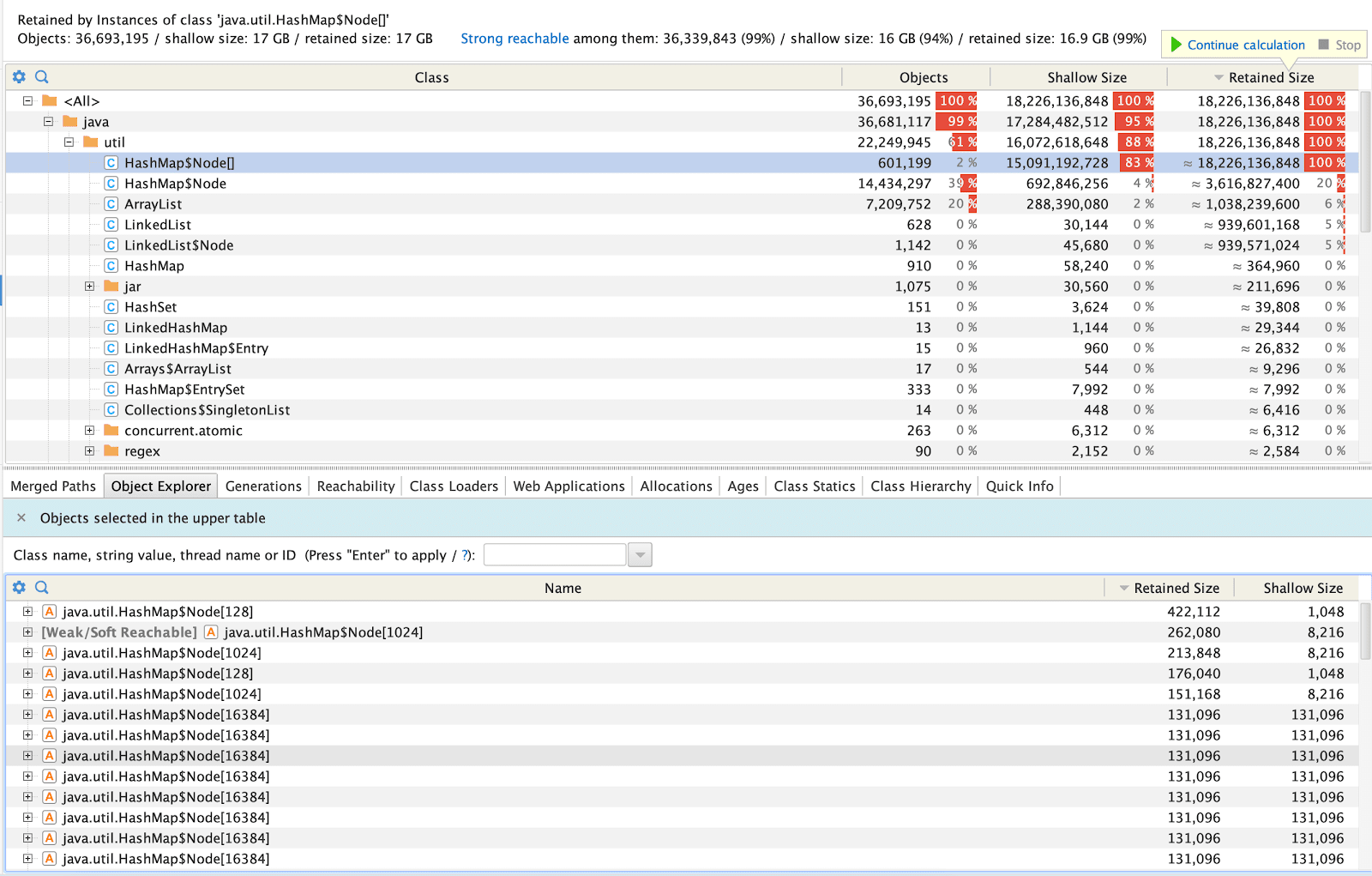
HeapDump Analysis Screenshot from YourKit
What took us by surprise was HashMap$Node[16384] growing over periodic heap dump files. Looking inside HashMap$Node[16384] revealed that these HashMaps were not related to business logic but the AWS SDK.
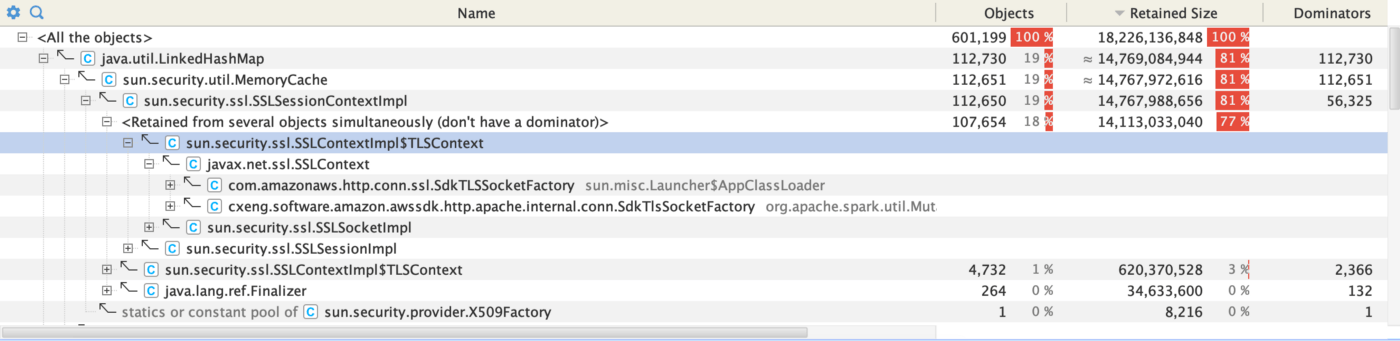
Screenshot from YourKit
A quick Google search and code analysis gave us our answer: we were not closing the connection correctly. The same issue has also been addressed on the aws-sdk Github issues.
Step 10: Fix the memory leak
By analyzing the heap dump, we were able to determine the location of the problem. While making a connection to Kinesis, we created a new Kinesis client for every partition when the connection was opened (general idea copied from Databricks’ Kinesis documentation):
But in the case of closing the connection, we were closing only the KinesisClient:
The Apache Http client was not being closed. This resulted in an increasing number of Http clients being created and TCP connections being opened on the system, causing the issue discussed here. The aws-sdk documentation states that:
We were able to prove it out using the following script:
Conclusion
What we’ve seen in this post is an example of how to diagnose a memory leak happening in a Spark application. If I faced this issue again, I would attach a JVM profiler to the executor and try to debug it from there.
From this investigation, we got a better understanding of how Spark structured streaming is working internally, and how we can tune it to our advantage. Some lessons learned that are worth remembering:
- Memory leaks can happen, but there are a number of things you can do to investigate them.
- We need better tooling to read large hprof files.
- If you open a connection, when you are done, always close it.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.