7 Reasons to Learn PyTorch on Databricks
by Jules Damji
Free Edition has replaced Community Edition, offering enhanced features at no cost. Start using Free Edition today.
What expedites the process of learning new concepts, languages or systems? When learning a new task, do you look for analogs from skills you already possess?
Across all learning endeavors, three favorable characteristics stand out: familiarity, clarity and simplicity. Familiarity eases the transition because of a recognizable link between the old and new ways of doing. Clarity minimizes the cognitive burden. And simplicity reduces the friction in the adoption of the unknown and, as a result, increases the fruition of learning a new concept, language or system.
Aside from being popular among researchers, gaining adoption by machine learning practitioners in production, and having a vibrant community, PyTorch has a familiar feel to it, easy to learn, and you can employ it for your machine learning use cases.
Keeping these characteristics in mind, we examine in this blog several reasons why it's easy to learn PyTorch, and how the Databricks Lakehouse Platform facilitates the learning process.

1a. PyTorch is Pythonic
Luciano Ramalho in Fluent Python defines Pythonic as an idiomatic way to use Python code that makes use of language features to be concise and readable. Python object constructs follow a certain protocol, and their behaviors adhere to a consistent pattern across classes, iterators, generators, sequences, context managers, modules, coroutines, decorators, etc. Even with little familiarity with the Python data model, modules and language constructs, you recognize similar constructs in PyTorch APIs, such as a torch.tensor, torch.nn.Module, torch.utils.data.Datasets, torch.utils.data.DataLoaders etc. Another aspect is the concise code you can write in PyTorch as with PyData packages such as Pandas, scikit-learn or SciPy.
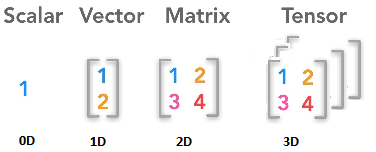
PyTorch integrates with the PyData ecosystem, so your familiarity with NumPy makes learning Torch Tensors incredibly simple. NumPy arrays and tensors have similar data structures and operations. Just as DataFrames are central data structures to Apache Spark™ operations, so are tensors as inputs to PyTorch models, training operations, computations and scoring. A PyTorch tensor's mental image (shown in the diagram below) maps to an n-dimensional NumPy array.
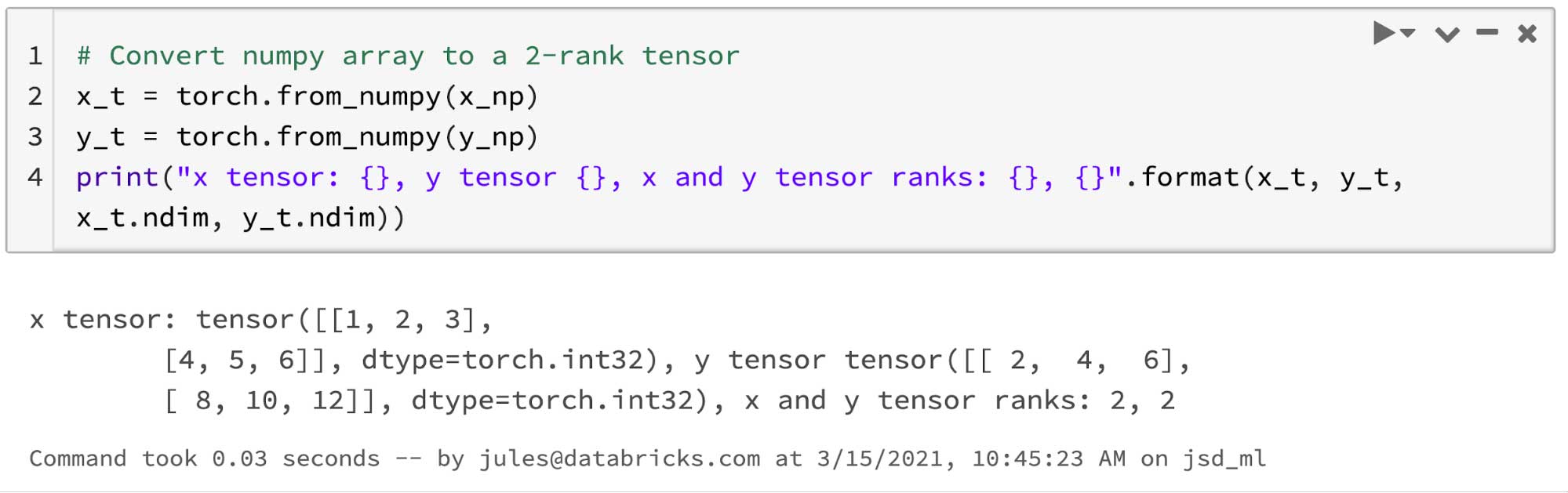
For instance, you can seamlessly create NumPy arrays and convert them into Torch tensors. Familiarity with NumPy operations transfers to tensor operations, as shown in the code below.
Both have familiar, imperative and intuitive operations that one would expect from Python object APIs, such as lists, tuples, dictionaries, sets, etc. All this familiarity with NumPy's equivalent array operations on Torch tensors helps. Consider these examples:


The latest release of PyTorch 1.8.0 further builds on this analog operation between PyTorch tensors and NumPy for fast Fourier transformation series.

1b. Easy-to-extend PyTorch nn Modules
PyTorch library includes neural network modules to build a layered network architecture. In PyTorch parlance, these modules comprise each layer of your network. Derived from its base class module torch.nn.Module, you can easily create a simple or complex layered neural network. To define a PyTorch customized network module class and its methods, you follow a similar pattern to build a customized Python object class derived from its base class object. Let's define a simple two-layered linear network example.
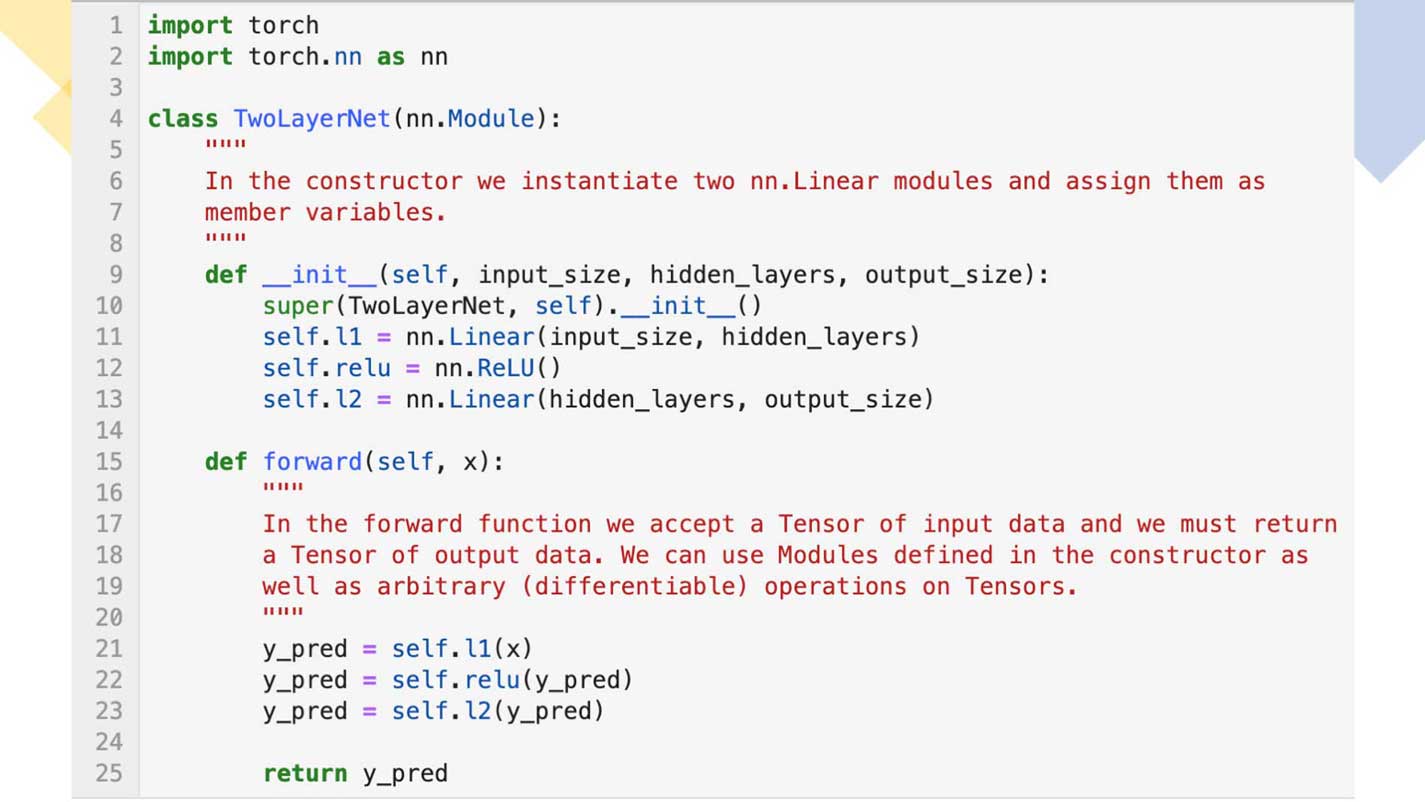
Notice that the custom TwoLayeredNet below is Pythonic in its flow and structure. Derived classes from the torch.nn.Module have class initializers with parameters, define interface methods, and are callable. That is, the base class torch.nn.Module implements the Python magic __call__() object method. Although the two-layered model is simple, it demonstrates this familiarity with extending a class from Python's base object.
Furthermore, you get an intuitive feeling that you are writing or reading Python application code while using PyTorch APIs –the syntax, structure, form and behavior are all too familiar. The unfamiliar bits are the PyTorch modules and the APIs, which are no different when learning a new PyData package APIs and incorporating them into your Python application code.
For more Pythonic code, read the accompanying notebook on the imperative nature of PyTorch code for writing training loops and loss functions, familiar Python iterative constructs, and using the cuda library for GPUs.
Now we define a simple training loop with some iterations, using Python familiar language constructs.
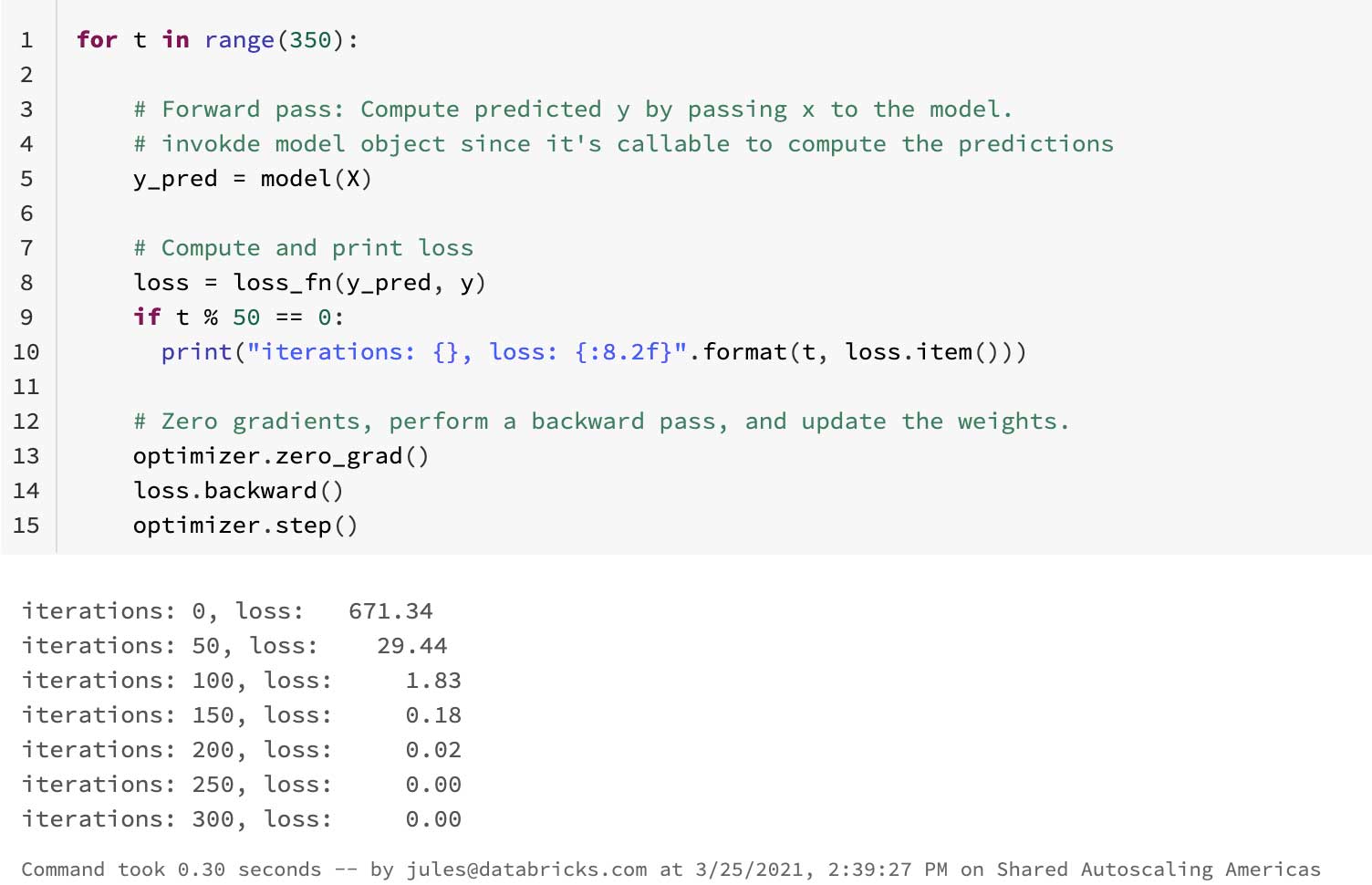
What follows is a recognizable pattern and flow between a Python's customized class and a simple PyTorch neural network. Also, the code reads like Python code. Another recognizable Pythonic pattern in PyTorch is how Dataset and DataLoaders use Python protocols to build iterators.
1c. Easy-to-customize PyTorch Dataset for Dataloaders
At the core of PyTorch data loading utility is the torch.utils.data.DataLoader class. It is an integral part of the PyTorch iterative training process, which iterates over batches of input during an epoch of training. DataLoaders implements a Python sequence and iterable protocol, which includes implementing __len__ and __getitem__ magic methods on an object. Again, very Pythonic in behavior; as part of the implementation, we employ list comprehensions, use NumPy arrays to convert to tensors and use random access to fetch nth data item — all conforming to familiar access patterns and behaviors of doing things in Python.
Let's look at a simple custom Dataset of temperatures for use in training a model. Other complex datasets could be images, extensive features datasets of tensors, etc.
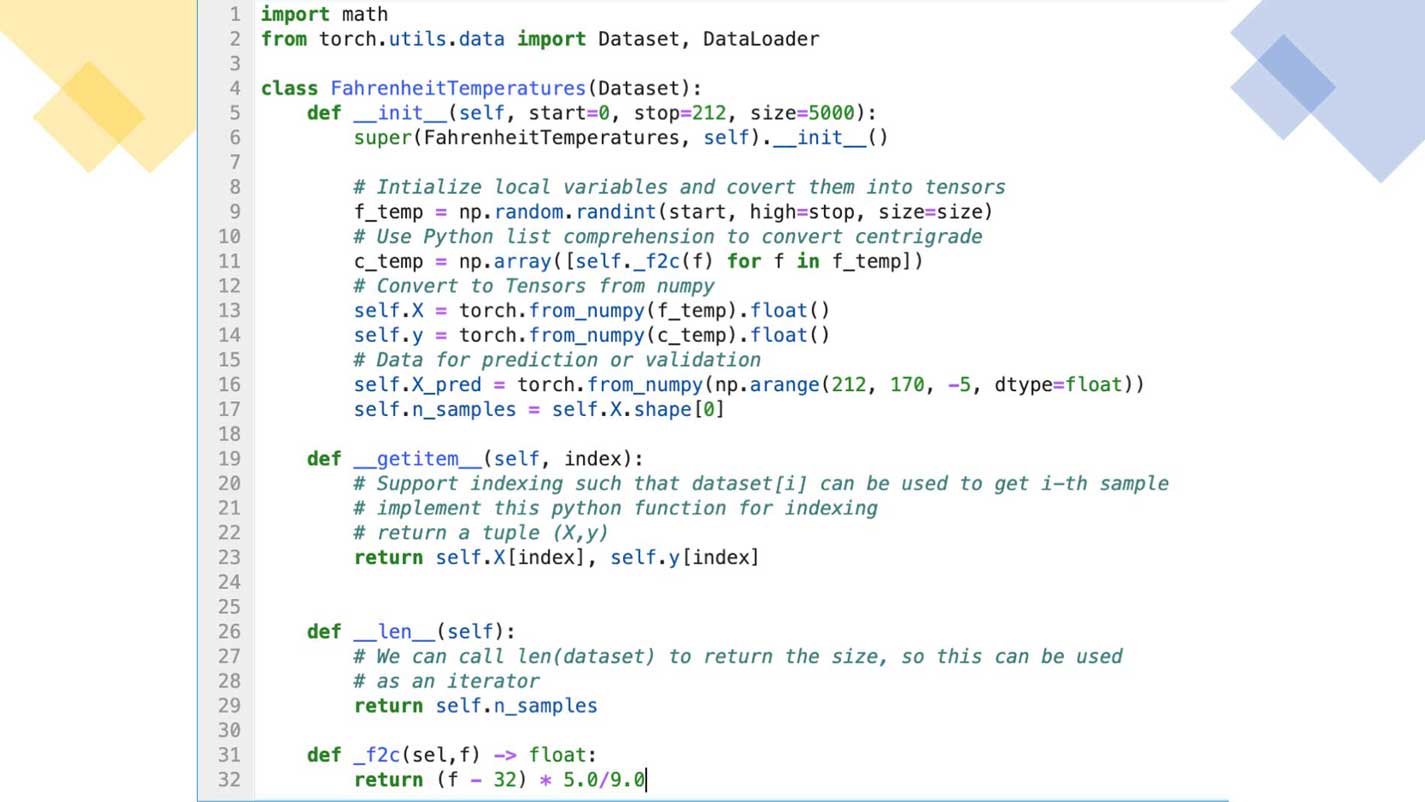
A PyTorch Dataloader class takes an instance of a customized FahrenheitTemperatures class object as a parameter. This utility class is standard in PyTorch training loops. It offers an ability to iterate over batches of data like an iterator: again, a very Pythonic and straightforward way of doing things!

Since we implemented our custom Dataset, let's use it in the PyTorch training loop.
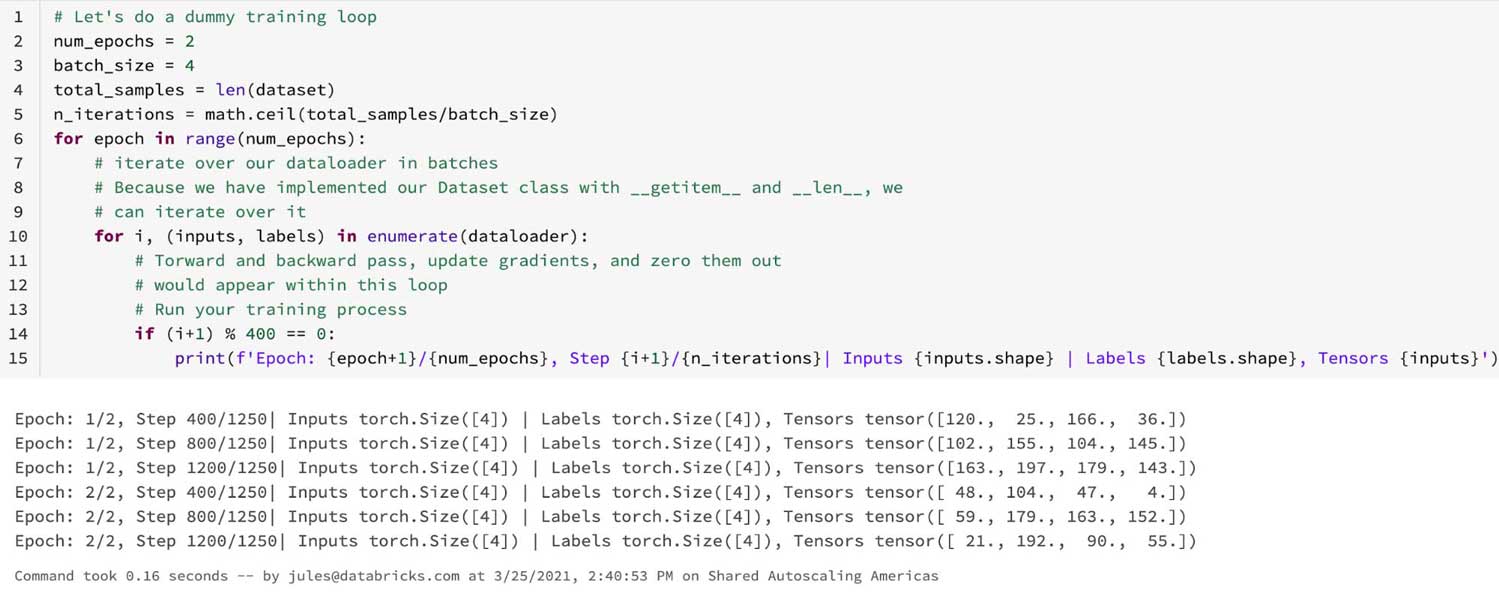
Although the aforementioned Pythonic reasons are not directly related to Databricks Lakehouse Platform, they account for ideas of familiarity, clarity, simplicity, and the Pythonic way of writing PyTorch code. Next, we examine what aspects within the Databricks Lakehouse Platform's runtime for machine learning facilitate learning PyTorch.
2. No need to install Python packages
As part of the Databricks Lakehouse Platform, the runtime for machine learning (ML) comes preinstalled with the latest versions of Python, PyTorch, PyData ecosystem packages and additional standard ML libraries, saving you from installing or managing any packages. Out-of-the-box and ready-to-use-runtime environments also unburden you from needing to control or install packages. If you want to install additional Python packages, simply use %pip install. This ability to support package management on your cluster is popular among Databricks customers and widely used as part of their development model lifecycle.
To inspect the list of all preinstalled packages, use the pip list.

3. Easy-to-Use CPUs or GPUs
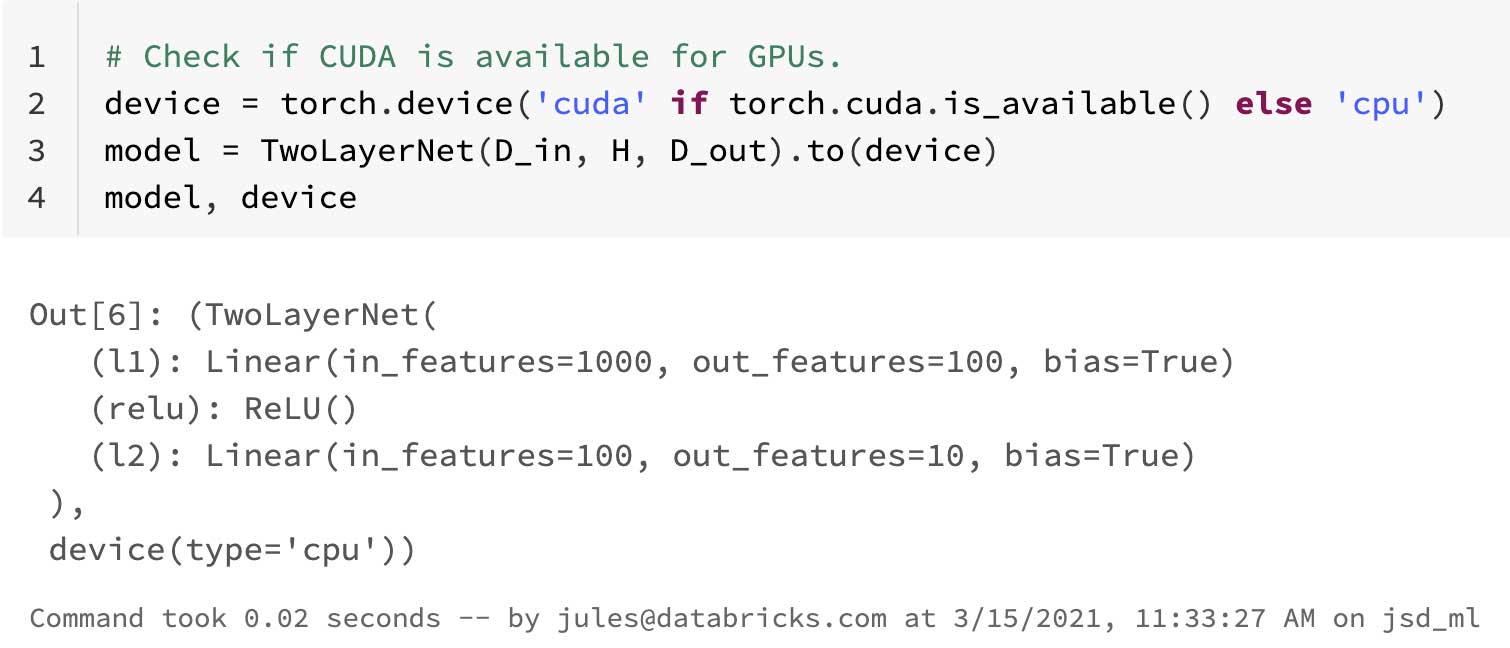
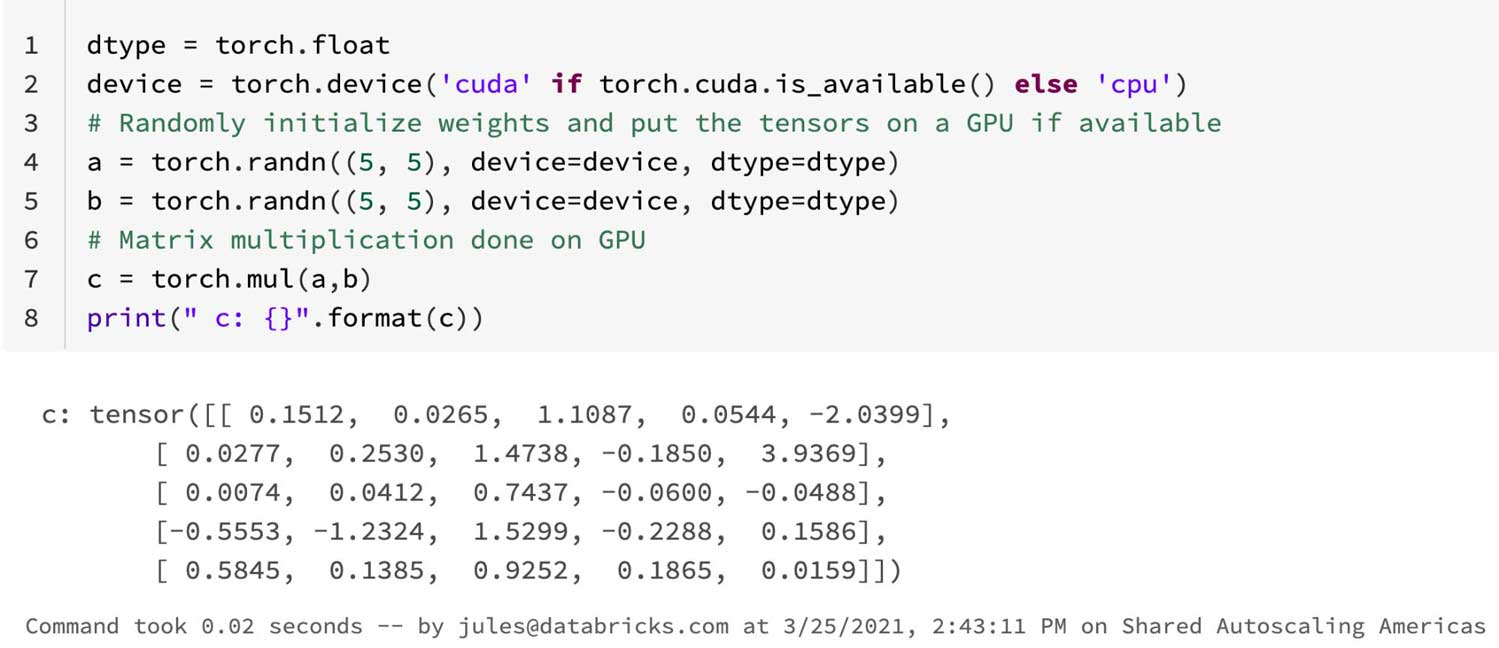
Neural networks for deep learning involve numeric-intensive computations, including dot products and matrix multiplications on large and higher-ranked tensors. For compute-bound PyTorch applications that require GPUs, create a cluster of MLR with GPUs and consign your data to use GPUs. As such, all training can be done on GPUs, as the above example of TwoLayeredNet demonstrates using cuda.
Note that this example shows simple code, and showing matrix multiplication of two randomly generated tensors, real PyTorch applications will have much more intense computation during their forward and backward passes and auto-grad computations.
4. Easy-to-Use TensorBoard
Already announced in a blog as part of the Databricks Runtime (DBR), this magic command displays your training metrics from TensorBoard within the same notebook. No longer do you need to leave your notebook and launch TensorBoard from another tab. This in-place TensorBoard visualization is a significant improvement toward simplicity and developer experience. And PyTorch developers can quickly see their metrics in TensorBoard.
Let's try to run a sample PyTorch FashionMNIST example with TensorBoard logging.
First, define a SummaryWriter, followed by the FashionMNIST Dataset in the DataLoader in our PyTorch torchvision.models.resnet50 model.

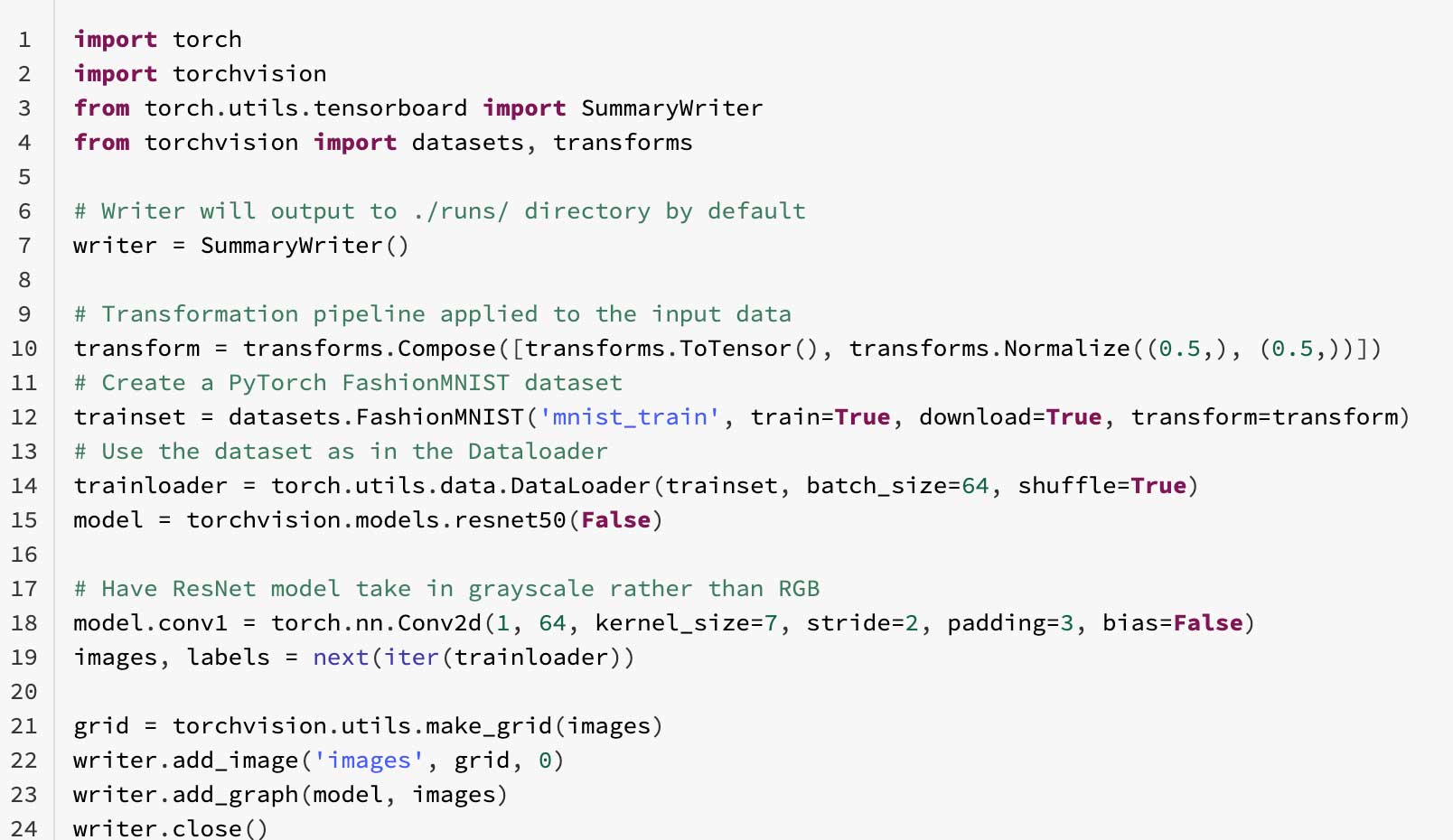
Using Databricks notebook's magic commands, you can launch the TensorBoard within your cell and examine the training metrics and model outputs.
%load_ext tensorboard
%tensorboard --logdir=./runs
5. PyTorch Integrated with MLflow
In our steadfast effort to make Databricks simpler, we enhanced MLflow fluent tracking APIs to autolog MLflow entities—metrics, tags, parameters and artifacts—for supported ML libraries, including PyTorch Lightning. Through the MLflow UI, an integral part of the workspace, you can access all MLflow experiments via the Experiment icon in the upper right corner. All experiment runs during training are automatically logged to the MLflow tracking server. No need for you to explicitly use the tracking APIs to log MLflow entities, albeit it does not prevent you from tracking and logging any additional entities such as images, dictionaries, or text artifacts.
Here is a minimal example of a PyTorch Lightning FashionMNIST instance with just a training loop step (no validation, no testing). It illustrates how you can use MLflow to autolog MLflow entities, peruse the MLflow UI to inspect its runs from within this notebook, register the model and serve or deploy it.
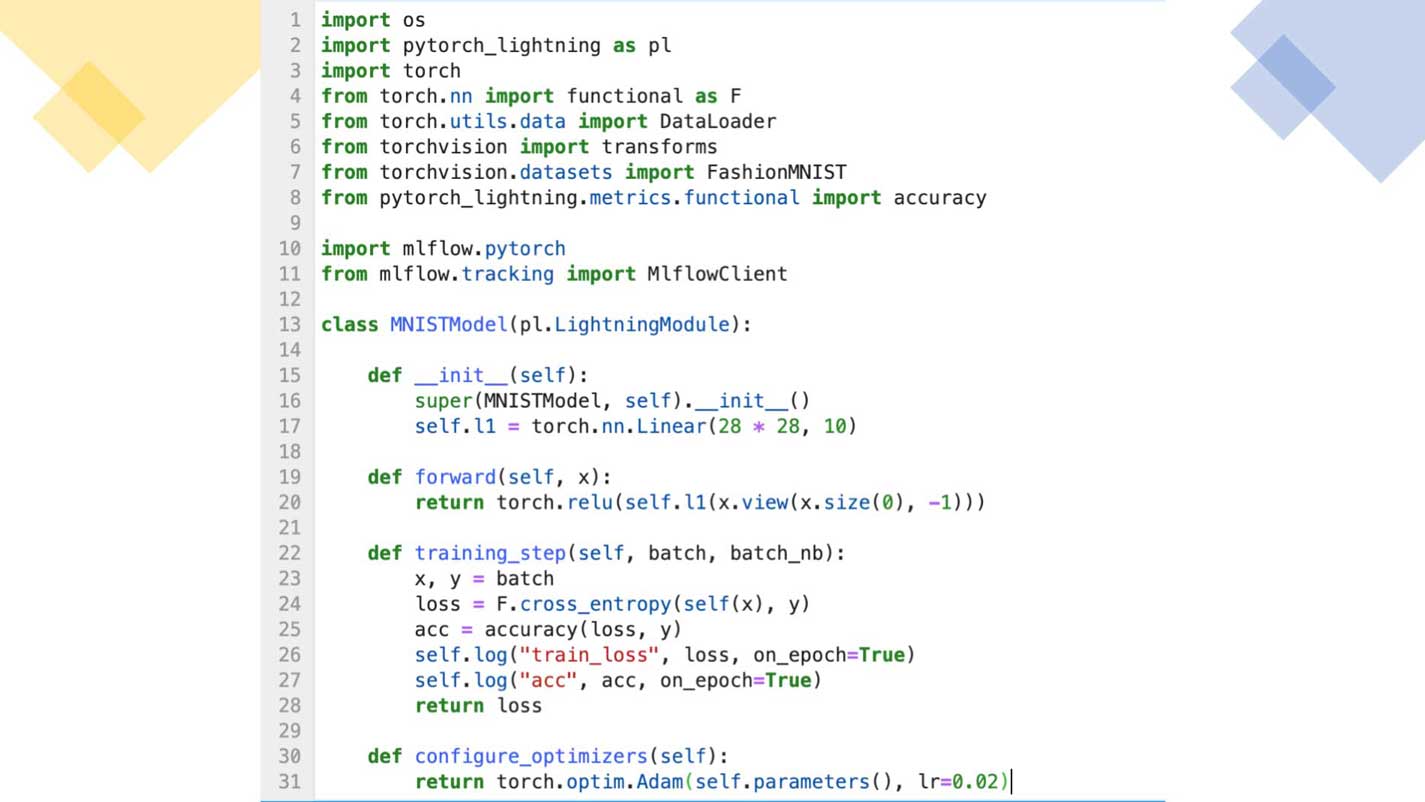
Create the PyTorch model as you would create a Python class, use the FashionMNIST DataLoader a PyTorch Lightning Trainer and autolog all MLflow entities during its trainer.fit() method.
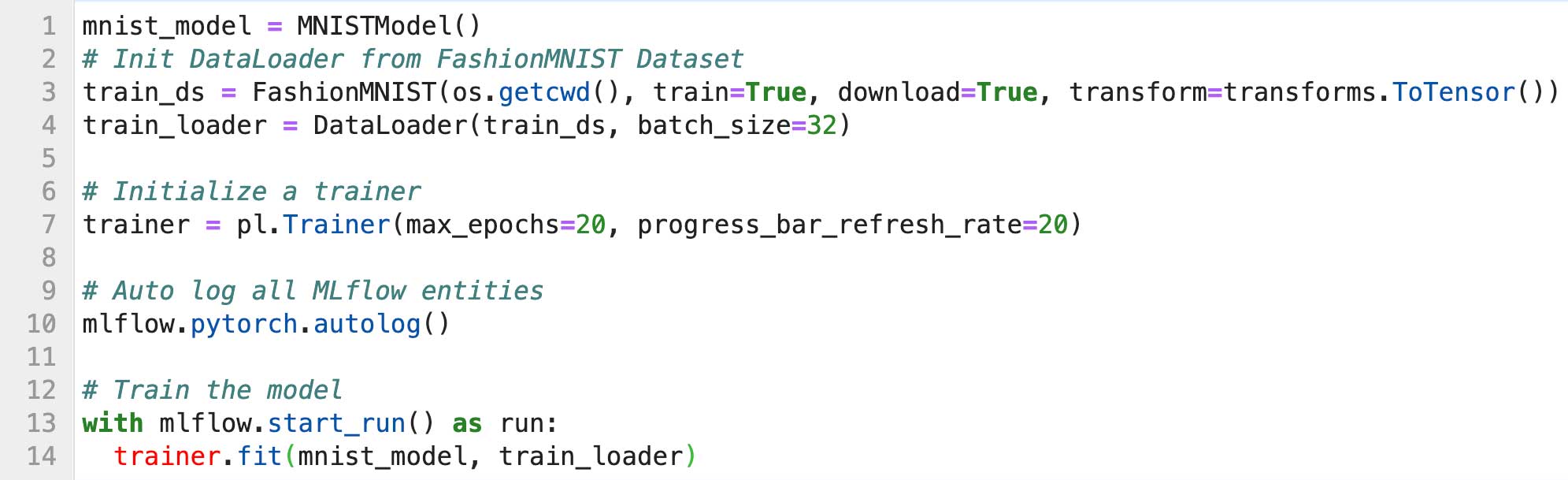
6. Convert MLflow PyTorch-logged Models to TorchScript
TorchScript is a way to create serializable and optimizable models from PyTorch code. We can convert a PyTorch MLflow-logged model into a TorchScript format, save, and load (or deploy to) a high-performance and independent process. Or deploy and serve on Databricks cluster as an endpoint.
The process entails the following steps:
- Create an MLflow PyTorch model
- Compile the model using JIT and convert it to the TorchScript model
- Log or save the TorchScript model
- Load or deploy the TorchScript model
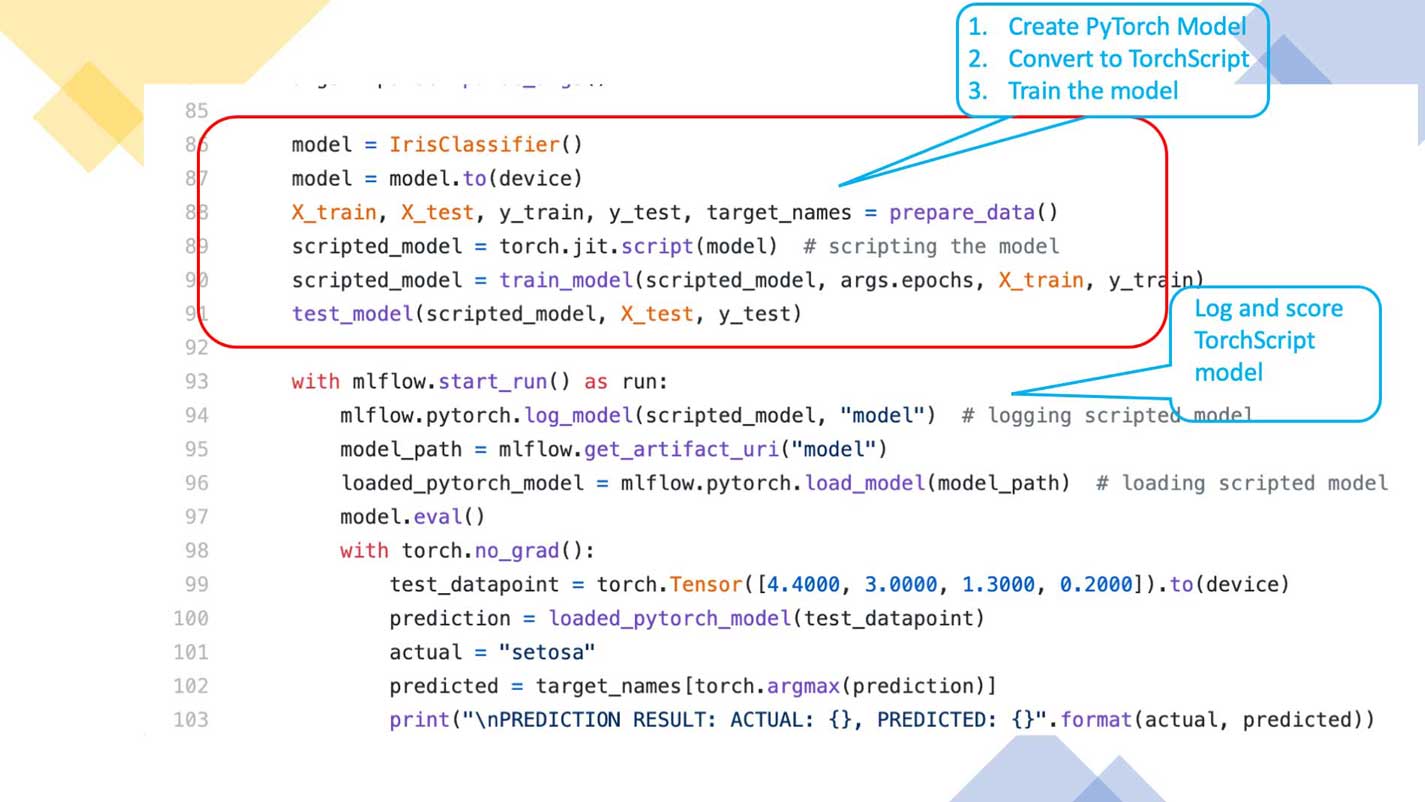
We have not included all the code here for brevity, but you can examine the sample code—IrisClassification and MNIST—in the GitHub MLflow examples directory.
7. Ready-to-run PyTorch Tutorials for Distributed Training
Lastly, you can use the Databricks Lakehouse MLR cluster to distribute your PyTorch model training. We provide a set of tutorials that demonstrate a) how to set up a single node training and b) how to migrate to the Horovod library to distribute your training. Working through these tutorials equips you with how to apply distributed training for your PyTorch models. Ready-to-run and easy-to-import-notebooks into your cluster, these notebooks are an excellent stepping-stone to learn distributed training. Just follow the recommended setups and sit back and watch the model train…

Each notebook provides a step-by-step guide to set up an MLR cluster, how to adapt your code to use either CPUs or GPUs and train your models in a distributed fashion with the Horovod library.
- Train a simple PyTorch Model
- Use PyTorch on a Single Node
- Single node PyTorch to distributed deep learning
- Simplify data conversion from Apache Spark™ to PyTorch
Moreover, the PyTorch community provides excellent Learning with PyTorch Examples starter tutorials. You can just as simply cut-and-paste the code into a Databricks notebook or import a Jupyter notebook and run it on your MLR cluster as in a Python IDE. As you work through them, you get a feel for the Pythonic nature of PyTorch: imperative and intuitive.
Finally, there will be a number of PyTorch production ML use case sessions at the upcoming Data + AI Summit. Registration is open now. Save your spot.
What's Next: How to get started
You can try the accompanying notebook in your MLR cluster and import the PyTorch tutorials mentioned in this notebook. If you don't have a Databricks account, get one today for a free trial and have a go at PyTorch on Databricks Lakehouse Platform. For single-node training, limited functionality and only CPUs usage, use the Databricks Community Edition.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.