What’s New in Apache Spark™ 3.1 Release for Structured Streaming
by Yuanjian Li, Shixiong Zhu and Bo Zhang
Along with providing the ability for streaming processing based on Spark Core and SQL API, Structured Streaming is one of the most important components for Apache Spark™. In this blog post, we summarize the notable improvements for Spark Streaming in the latest 3.1 release, including a new streaming table API, support for stream-stream join and multiple UI enhancements. Also, schema validation and improvements to the Apache Kafka data source deliver better usability. Finally, various enhancements were made for improved read/write performance with FileStream source/sink.
New streaming table API
When starting a structured stream, a continuous data stream is considered an unbounded table. Therefore, Table APIs provide a more natural and convenient way to handle streaming queries. In Spark 3.1, we added the support for DataStreamReader and DataStreamWriter. End users can now directly use the API to read and write streaming DataFrames as tables. See the example below:
Also, with these new options, users can transform the source dataset and write to a new table:
Databricks recommends using the Delta Lake format with the streaming table APIs, which allows you to
- Compact small files produced by low latency ingest concurrently.
- Maintain “exactly-once” processing with more than one stream (or concurrent batch jobs).
- Efficiently discover which files are new when using files as the source for a stream.
New support for stream-stream join
Prior to Spark 3.1, only inner, left outer and right outer joins were supported in the stream-stream join. In the latest release, we have implemented full outer and left semi stream-stream join, making Structured Streaming useful in more scenarios.
- Left semi stream-stream join (SPARK-32862)
- Full outer stream-stream join (SPARK-32863)
Kafka data source improvements
In Spark 3.1 we have upgraded the Kafka dependency to 2.6.0 (SPARK-32568), which enables users to migrate to the new API for Kafka offsets retrieval (AdminClient.listOffsets). It resolves the issue (SPARK-28367) of the Kafka connector waiting infinitely when using the older version.
Schema validation
Schemas are essential information for Structured Streaming queries. In Spark 3.1, we added schema validation logic for both user-input schema and the internal state store:
Introduce state schema validation among query restart (SPARK-27237)
With this update, key and value schemas are stored in the schema files at the stream start. The new key and value schema are then verified against the existing ones for compatibility at the query restart. State schema is considered to be "compatible" when the number of fields is the same and the data type for each field is the same. Note, we don't check the field name here since Spark allows renaming.
This will prevent queries with incompatible state schemas from running, which reduces the chance of in-deterministic behavior and provides more informative error messages.
Introduce schema validation for streaming state store (SPARK-31894)
Previously, Structured Streaming directly put the checkpoint (represented in UnsafeRow) into StateStore without any schema validation. When upgrading to a new Spark version, the checkpoint files will be reused. Without schema validations, any change or bug fix related to the aggregate function may cause random exceptions, even the wrong answer (e.g SPARK-28067). Now Spark validates the checkpoint against the schema and throws InvalidUnsafeRowException when the checkpoint is reused during migration. It is worth mentioning that this work also helped us find the blocker, SPARK-31990: Streaming's state store compatibility is broken, for Spark 3.0.1 release.
Structured Streaming UI enhancements
We introduced the new Structured Streaming UI in Spark 3.0. In Spark 3.1, we added History Server support for the Structured Streaming UI(SPARK-31953) as well as more information about streaming runtime status:
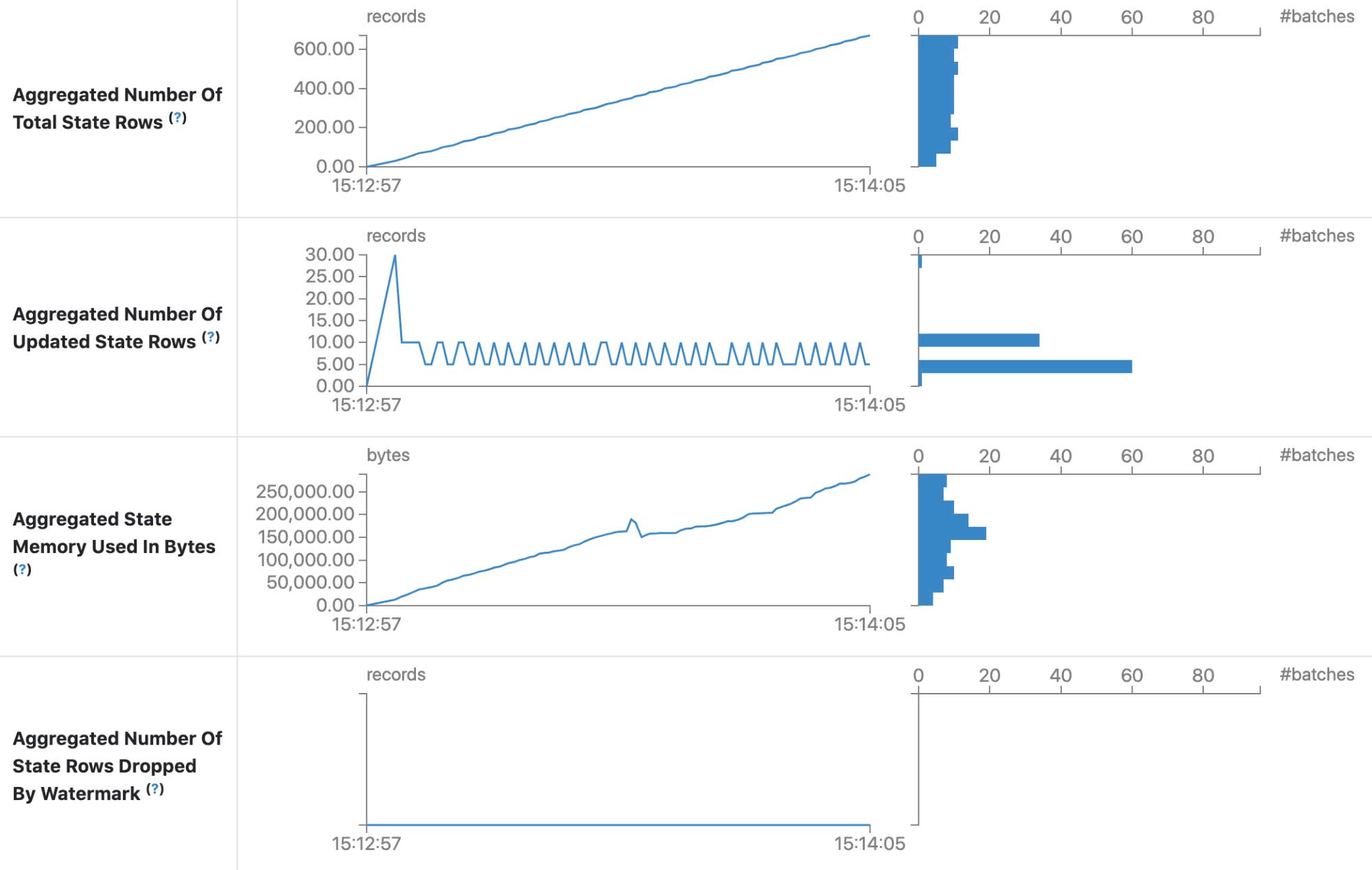
State information in Structured Streaming UI (SPARK-33223)
Four more metrics are added for state information:
- Aggregated Number Of Total State Rows
- Aggregated Number Of Updated State Rows
- Aggregated State Memory Used In Bytes
- Aggregated Number Of State Rows Dropped By Watermark
With these metrics, we have a whole picture for the state store. It also makes it possible to add some new features such as capacity planning.
- Watermark gap information in Structured Streaming UI (SPARK-33224)
Watermark is one of the major metrics that the end-users need to track for stateful queries. It defines "when" the output will be emitted for append mode, hence knowing how much gap between wall clock and watermark (input data) is very helpful to set an expectation of the output.

This shows custom metrics information, which is set in the config `spark.sql.streaming.ui.enabledCustomMetricList`.

Enhancement for FileStreamSource/Sink
There are improvements for FileStreamSource/Sink:
Cache fetched list of files beyond maxFilesPerTrigger as unread files (SPARK-30866)
Previously when config maxFilesPerTrigger is set, FileStreamSource will fetch all available files, process a limited number of files according to the config and ignore the others for every micro-batch. With this improvement, it will cache the files fetched in previous batches and reuse them in the following ones.
Streamline the logic on file stream source and sink metadata log (SPARK-30462)
Before this change, whenever the metadata was needed in FileStreamSource/Sink, all entries in the metadata log were deserialized into the Spark driver’s memory. With this change, Spark will read and process the metadata log in a streamlined fashion whenever possible.
Provide a new option to have retention on output files (SPARK-27188)
There is a new option to configure the retention of metadata log files in FileStreamSink, which helps limit the growth of metadata log file size for long-running Structured Streaming queries.
What’s Next
For the next major release, we'll keep focusing on new functionality, performance and usability improvements for Spark Structured Streaming. We would love to hear your feedback as an end-user or a Spark developer! If you have any feedback, please feel free to share it with us through the Spark user or developer mailing lists. Thanks to all the contributors and users in the community who help with these significant enhancements happening
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.