Don't Miss These Top 10 Announcements From Data + AI Summit
by Ryan Boyd
The 2021 Data + AI Summit was filled with so many exciting announcements for open source and Databricks, talks from top-tier creators across the industry (such as Rajat Monga, co-creator of TensorFlow) and guest luminaries like Bill Nye, Malala Yousafzai and the NASA Mars Rover team. You can watch the keynotes, meetups and hundreds of talks on-demand on the Summit platform, which is available through June 28th and requires free registration.
In this post, I'd like to cover my personal top 10 announcements in open source and Databricks from Summit. They are in no particular order and links to the talks go to the Summit platform.
Delta Lake 1.0
The Delta Lake open source project is a key enabler of the lakehouse, as it fixes many of the limitations of data lakes: data quality, performance and governance. The project has come a long way since its initial release, and the Delta Lake 1.0 release was just certified by the community. The release represents a variety of new features, including generated columns and cloud independence with multi-cluster writes and my favorite -- Delta Lake standalone, which reads from Delta tables but doesn't require Apache SparkTM.

We also announced a bunch of new committers to the Delta Lake project, including QP Hou, R.Tyler Croy, Christian Williams, Mykhailo Osypov and Florian Valeye.
Learn more about Delta Lake 1.0 in the keynotes from co-creator and Distinguished Engineer Michael Armbrust.
Delta Sharing
Open isn't just about open source - it's about access and sharing. Data is the lifeblood of every successful organization, but it also needs to be able to smoothly flow between organizations. Data sharing solutions have historically been tied to a single commercial product, introducing vendor lock-in risk and data silos. Databricks Co-founder & CEO Ali Ghodsi announced Delta Sharing, the industry's first open protocol for secure data sharing. It supports SQL and Python data science, plus has easy management, privacy, security and compliance. It will be part of the Delta Lake project under the Linux foundation.
We've already seen tremendous support for the project, with over 1,000 datasets to be made available by AWS data exchange, FactSet, S&P Global, Nasdaq and more. Additionally, Microsoft, Google, Tableau and many others have committed to adding support for Delta Sharing into their products.

Learn more about Delta Sharing from Apache Spark and MLflow co-creator Matei Zaharia in the keynotes. You can also watch a session from Tableau on How to Gain 3 Benefits with Delta Sharing.
Delta Live Tables
ETL or ELT is one of the most critical data workloads, because data quality affects all downstream workloads. This often gets expressed as a tidy data flow from messy incoming data to clean, fresh, reliable data that fits the required use cases. The reality is not so simple - data pipelines are fragile and take a lot of time to get right.
Delta Live Tables was announced at Summit to provide automatic, reliable ETL made easy on top of Delta Lake. It handles automatic testing, management, monitoring and recovery as well as live updates of your data pipelines. And, best of all, you can do this with only SQL (though Python is also supported to do advanced analytics and AI).
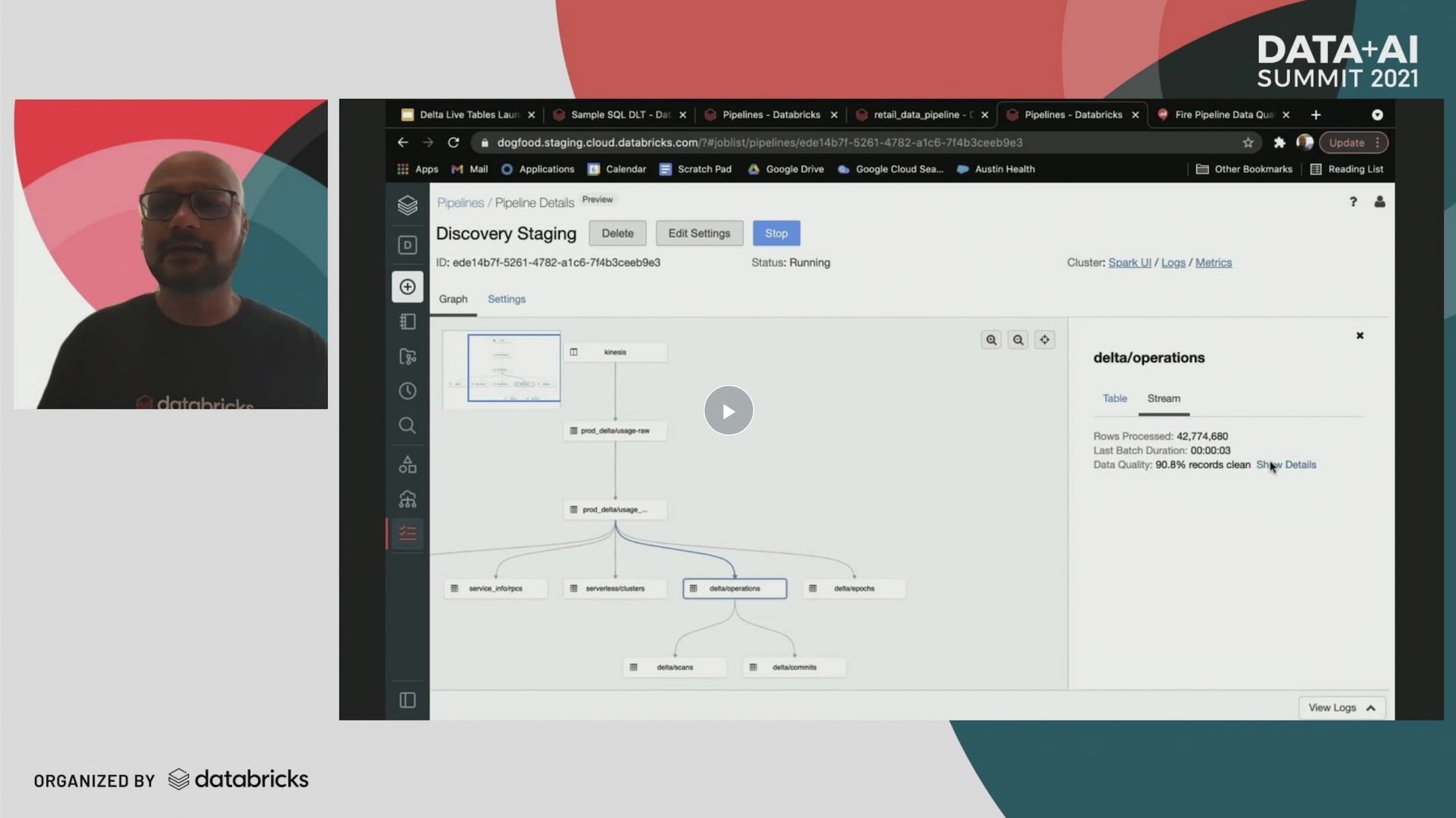
Learn more about Delta Live Tables with Distinguished Engineer Michael Armbrust in the keynotes. You can also watch an in-depth session on Making Reliable ETL Easy on Delta Lake from VP of Product Management Awez Syed.
Early Release: Delta Lake Definitive Guide by O'Reilly
My esteemed colleagues Denny Lee, Vini Jaiswal and Tathagata Das are hard at work writing a new book exploring how to build modern data lakehouse architectures with Delta Lake. As Michael Armbrust announced during the keynotes, we've joined with O'Reilly to make the early release available for free. Download it today, and we'll be sure to let you know when the final release is published!

Unity Catalog
Companies are collecting massive amounts of data in data lakes in the cloud, and these lakes keep growing. It's been hard to maintain governance in a single cloud, let alone the multi-cloud environment that many enterprises use. The Unity Catalog is the industry's first unified catalog for the lakehouse, enabling users to standardize on one fine-grained solution across all clouds. You can use ANSI SQL to control access to tables, fields, views, models -- not files. It also provides an audit log to make it easy to understand who and what is accessing all your data.
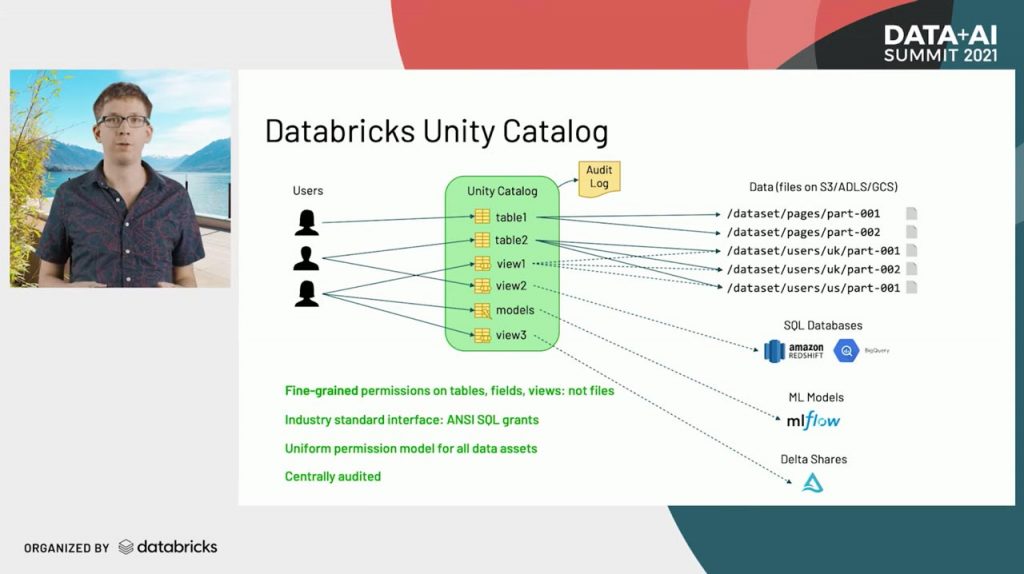
Learn more from Chief Technologist Matei Zahari in the opening keynote, and sign up for the waitlist to get access to Unity Catalog.
Databricks SQL: improved performance, administration and analyst experience
We want to provide the most performant, simplest and most powerful SQL platform in an open way. SQL is an important part of the data lakehouse vision, and we've been focused on improving the performance and usability of SQL in real-world applications.
Last year, we talked about how Databricks, powered by Delta Lake and the Photon engine, performed better than data warehouses in the TPC-DS price/performance comparison on a 30TB workload. At Summit, Reynold Xin, Chief Architect at Databricks, announced an update to this performance optimization work, focused on concurrent queries on a 10GB TPC-DS workload. After making over 100 different micro-optimizations, Databricks SQL now outperforms popular cloud data warehouses for small queries with lots of concurrent users.
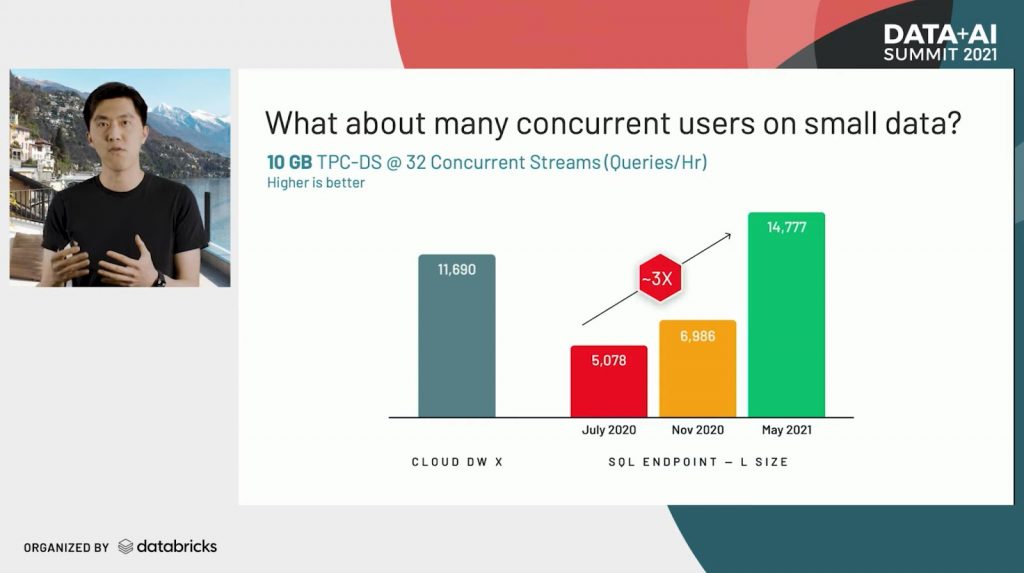
Learn more about the improvements in Databricks SQL and the Photon Engine from Reynold Xin, Chief Architect at Databricks and top all-time contributor to Apache Spark. Be sure to stay tuned for Databricks CEO Ali Ghodsi's discussion with Bill Inmon, the "father" of the data warehouse.
You can also watch an in-depth session from the tech lead and product manager of the Photon team.
Lakehouse momentum
The momentum in lakehouse adoption that Databricks CEO Ali Ghodsi discussed in the opening keynote is representative of significant engineering advancements that are simplifying the work of data teams globally.
No longer do these companies need to have two-tier data architectures with both data lakes and (sometimes multiple) data warehouses. By adopting the data lakehouse, they can now have both the performance, reliability and compliance capabilities typical in a data warehouse along with the scalability and support for unstructured data found in data lakes.
Rohan Dhupelia joined the opening keynote to talk about how the lakehouse transformed and simplified the work of data teams at Atlassian.
Ali then invited Bill Inmon, the "father" of the data warehouse, to the virtual stage to talk about the transformation he's seen over the last few decades. Bill says "if you don't turn your data lake into a lakehouse, then you're turning it into a swamp" and emphasizes that the lakehouse will unlock the data and present opportunities we've never seen before.
Hear first-hand from Ali, Rohan and Bill in the opening keynote on the lakehouse data architecture, data engineering and analytics. Stay tuned for Bill Inmon's upcoming book on the data lakehouse and read his blog post to understand the evolution to the lakehouse.
Koalas is being merged into Apache Spark
The most important library for data science is pandas. In order to better support data scientists moving from single-node "laptop data science" to highly scalable clusters, we launched the Koalas project two years ago. Koalas is an implementation of the pandas APIs, optimized for clustered environments enabling work on large datasets.
We're now seeing over 3 million PyPI downloads of Koalas every month - changing the way data scientists work at scale. Reynold Xin, the all-time top contributor to Apache Spark, announced that we've decided to donate Koalas upstream into the Apache Spark project. Now, anytime you write code for Apache Spark, you can take comfort in knowing the pandas APIs will be available to you.
The merging of these projects has a great side benefit for Spark users as well - the efficient plotting techniques in the pandas APIs on Spark automatically determine the best way to plot data without the need for manual downsampling.
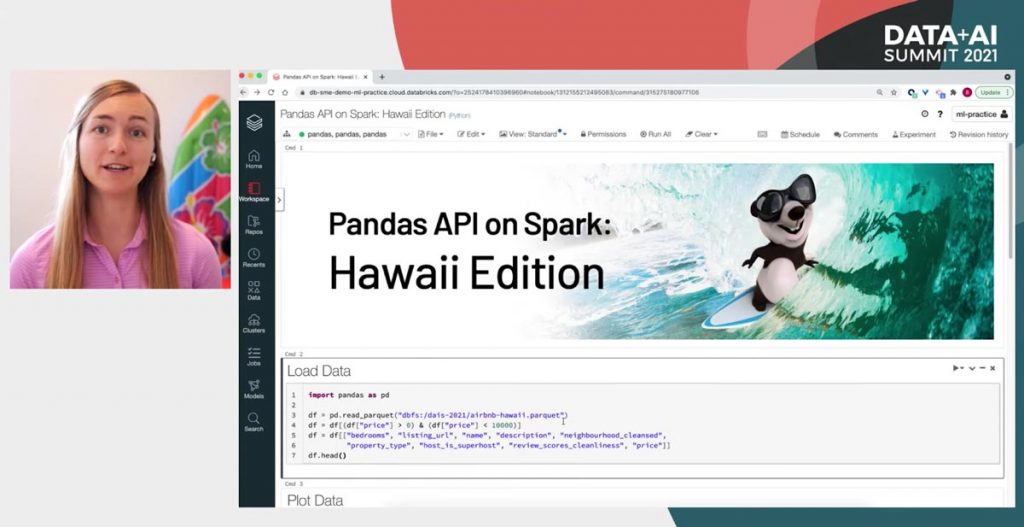
Learn more about the Koalas merger in the keynote and demo from Reynold Xin and Brooke Wenig. You can also watch a deep-dive into the Koalas project from the engineering team, including benchmarks and comparisons to other pandas scaling efforts.
Machine Learning Dashboard
Director of Product Management Clemens Mewald announced several new improvements in the machine learning capabilities of Databricks.
These improvements seek to simplify the full machine learning lifecycle - from data to model deployment (and back). One way we're doing this is by providing new persona-based navigation in the Databricks Workspace - providing a ML Dashboard that brings together data, models, feature stores and experiment tracking under a single interface.
Learn more from Clemens in the Spark, Data Science, and Machine Learning keynote and see a demo from Sr. Product Manager Kasey Uhlenhuth. They also have an in-depth session where they dive into the details of these announcements.
Machine Learning Feature Store
The Databricks Feature Store is the first that's co-designed with a data and MLOps platform.
What's a feature? Features are the inputs to a machine learning model, including transformations, context, feature augmentation and pre-computed attributes.
A feature store exists to make it easier to implement a feature once and use it both during training and low-latency production serving, preventing online/offline skew. The Databricks Feature Store includes a feature registry to facilitate discoverability and reusability of features, including tracking of the data sources. It also integrates into MLflow, enabling the feature versions used in training a particular version of a model to be automatically used in production serving, without manual configuration.
The data in the Databricks Feature Store is stored in an open format - Delta Lake tables, so they can be accessed from clients in Python, SQL and more.
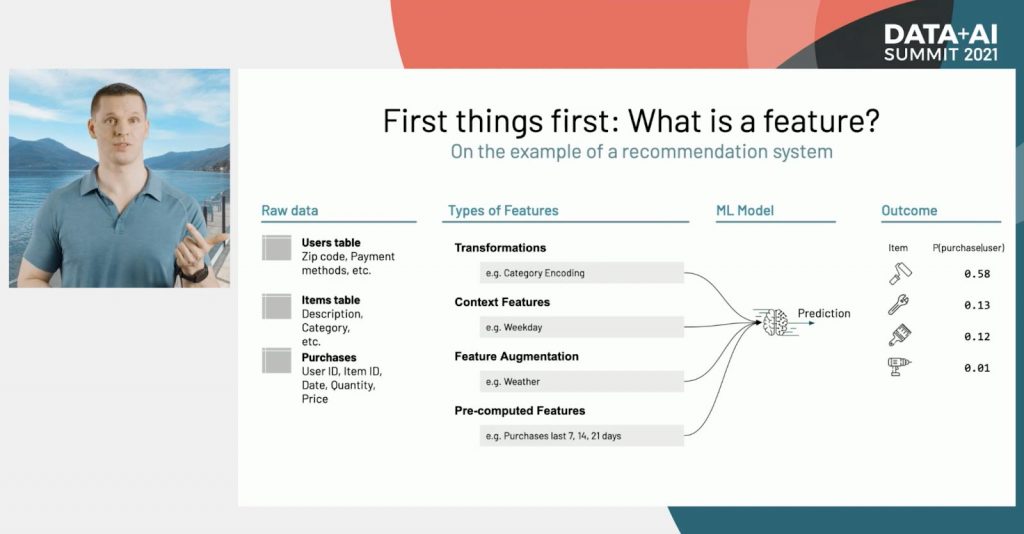
Learn more from Clemens in the Spark, Data Science and Machine Learning keynote and see a demo from Sr. Product Manager Kasey Uhlenhuth. They also have an in-depth session where they dive into the details of these announcements.
AutoML with reproducible trial notebooks
Databricks AutoML is a unique glass-box approach to AutoML that empowers data teams without taking away control. It generates a baseline model to quickly validate the feasibility of a machine learning project and guide the project direction.
Many other AutoML solutions designed for the citizen data scientist hit a wall if the auto-generated model doesn't work - it doesn't provide the control needed to tune it.

Databricks AutoML augments data scientists and enables them to see exactly what's happening under the hood by providing the source code for each trial run in separate, modifiable Python notebooks. The transparency of this glass box approach means there is no need to spend time reverse engineering an opaque auto-generated model to tune based on your subject matter expertise. It also supports regulatory compliance via the ability to show exactly how a model is trained.
AutoML integrates tightly with MLflow, tracking all the parameters, metrics, artifacts and models associated with every trial run. Get more details in the in-depth session.
Learn more
You may have noticed I actually covered 11 announcements in this post. It was actually only 10, but with a zero-based index. Sorry, there was so much to share!
Register or login to the event site to rewatch any or all of the 2021 sessions
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.