How Databricks’ Data Team Built a Lakehouse Across 3 Clouds and 50+ Regions
by Jason Pohl and Suraj Acharya
The internal logging infrastructure at Databricks has evolved over the years and we have learned a few lessons along the way about how to maintain a highly available log pipeline across multiple clouds and geographies. This blog will give you some insight as to how we collect and administer real-time metrics using our Lakehouse platform, and how we leverage multiple clouds to help recover from public cloud outages.
When Databricks was founded, it only supported a single public cloud. Now, the service has grown to support the 3 major public clouds (AWS, Azure, GCP) in over 50 regions around the world. Each day, Databricks spins up millions of virtual machines on behalf of our customers. Our data platform team of less than 10 engineers is responsible for building and maintaining the logging telemetry infrastructure, which processes half a petabyte of data each day. The orchestration, monitoring, and usage is captured via service logs that are processed by our infrastructure to provide timely and accurate metrics. Ultimately, this data is stored in our own petabyte-sized Delta Lake. Our Data Platform team uses Databricks to perform inter-cloud processing so that we can federate data where appropriate, mitigate recovery from a regional cloud outage, and minimize disruption to our live infrastructure.
Pipeline Architecture
Each cloud region contains its own infrastructure and data pipelines to capture, collect, and persist log data into a regional Delta Lake. Product telemetry data is captured across the product and within our pipelines by the same process replicated across every cloud region. A log daemon captures the telemetry data and it then writes these logs onto a regional cloud storage bucket (S3, WASBS, GCS). From there, a scheduled pipeline will ingest the log files using Auto Loader (AWS | Azure | GCP), and write the data into a regional Delta table. A different pipeline will read data from the regional delta table, filter it, and write it to a centralized delta table in a single cloud region.
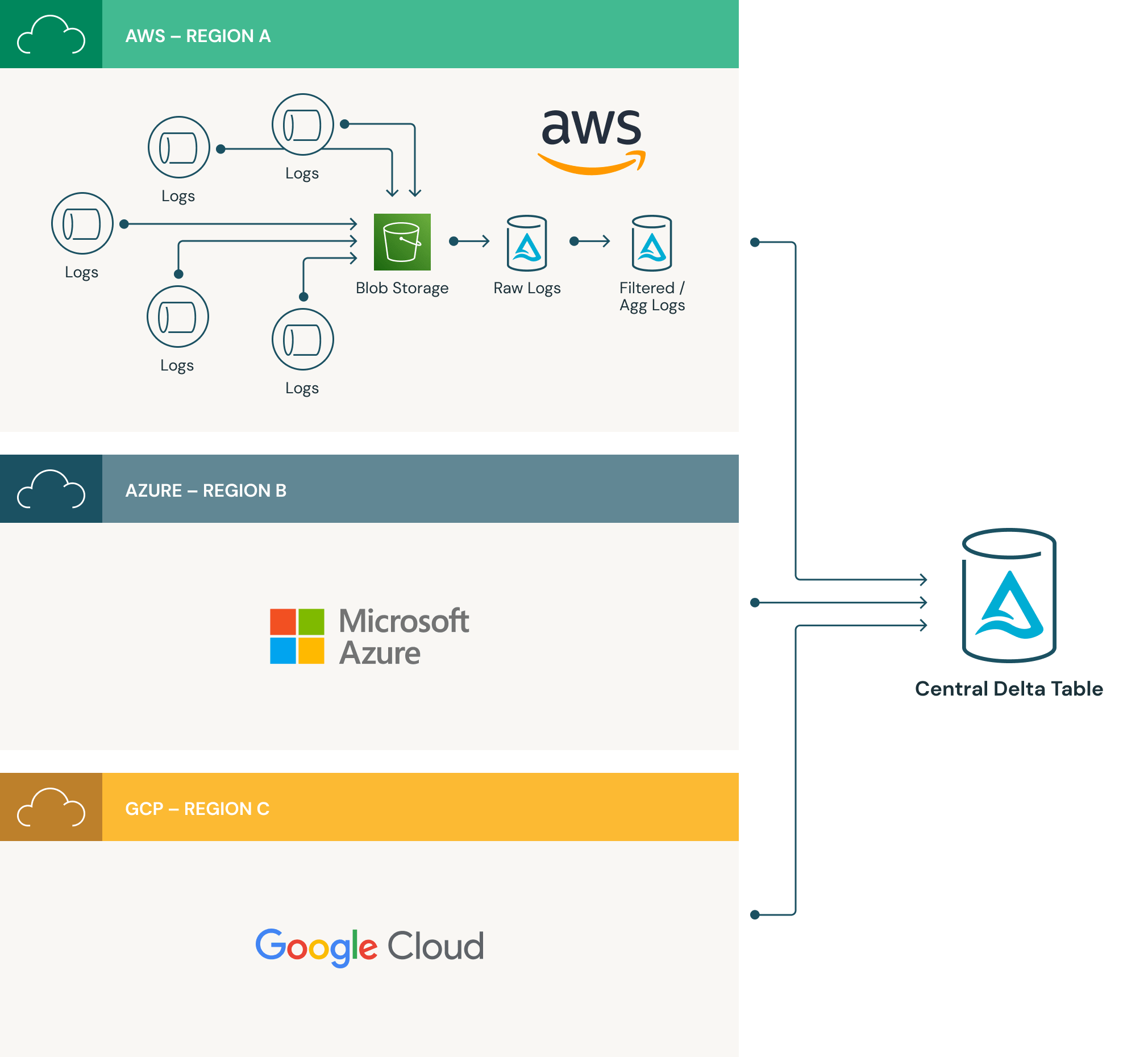
Before Delta Lake
Prior to Delta Lake, we would write the source data to its own table in the centralized lake, and then create a view which was a union across all of those tables. This view needed to be calculated at runtime and became more inefficient as we added more regions:
After Delta Lake
Today, we just have a single Delta Table that accepts concurrent write statements from over 50 different regions. While simultaneously handling queries against the data. It makes querying the central table as easy as:
The transactionality is handled by Delta Lake. We have deprecated the individual regional tables in our central Delta Lake and retired the UNION ALL view. The following code is a simplified representation of the syntax that is executed to load the data approved for egress from the regional Delta Lakes to the central Delta Lake
Disaster recovery
One of the benefits of operating an inter-cloud service is that we are well positioned for certain disaster recovery scenarios. Although rare, it is not unheard of for the compute service of a particular cloud region to experience an outage. When that happens, the cloud storage is accessible, but the ability to spin up new VMs is hindered. Because we have engineered our data pipeline code to accept configuration for the source and destination paths, this allows us to quickly deploy and run data pipelines in a different region to where the data is being stored. The cloud for which cloud the cluster is created in is irrelevant to which cloud the data is read or written to.
There are a few datasets which we safeguard against failure of the storage service by continuously replicating the data across cloud providers. This can easily be done by leveraging Delta deep clone functionality as described in this blog. Each time the clone command is run on a table, it updates the clone with only the incremental changes since the last time it was run. This is an efficient way to replicate data across regions and even clouds.
Minimizing disruption to live data pipelines
Our data pipelines are the lifeblood of our managed service and part of a global business that doesn’t sleep. We can’t afford to pause the pipelines for an extended period of time for maintenance, upgrades, or backfilling of data. Recently, we needed to fork our pipelines to filter a subset of the data normally written to our main table to be written to a different public cloud. We were able to do this without disrupting business as usual.
By following these steps we were able to deploy changes to our architecture into our live system without causing disruption.
First, we performed a deep clone of the main table to a new location on the other cloud. This copies both the data and the transaction log in a way to ensure consistency. Second, we released the new config to our pipelines so that the majority of data continues to be written to the central main table, and the subset of data writes to the new cloned table in the different cloud. This change can be made easily by just deploying a new config, and the tables receive updates for just the new changes they should receive. Next, we ran the same deep clone command again. Delta Lake will only capture and copy the incremental changes from the original main table to the new cloned table. This essentially backfills the new table with all the changes to the data between step 1 and 2. Finally, the subset of data can be deleted from the main table and the majority of data can be deleted from the cloned table. Now both tables represent the data they are meant to contain, with full transactional history, and it was done live without disrupting the freshness of the pipelines.
Summary
Databricks abstracts away the details of individual cloud services whether that be for spinning up infrastructure with our cluster manager, ingesting data with Auto Loader, or performing transactional writes on cloud storage with Delta Lake. This provides us with an advantage in that we can use a single code-base to bridge the compute and storage across public clouds for both data federation and disaster recovery. This inter-cloud functionality gives us the flexibility to move the compute and storage wherever it serves us and our customers best.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.