Large Scale ETL and Lakehouse Implementation at Asurion
This is a guest post from Tomasz Magdanski, Sr Director of Engineering, Asurion.
With its insurance and installation, repair, replacement and 24/7 support services, Asurion helps people protect, connect and enjoy the latest tech – to make life a little easier. Every day our team of 10,000 experts helps nearly 300 million people around the world solve the most common and uncommon tech issues. We're just a call, tap, click or visit away for everything from getting a same-day replacement of your smartphone to helping you stream or connect with no buffering, bumps or bewilderment.
We think you should stay connected and get the most from the tech you love… no matter the type of tech or where you purchased it.
Read Rise of the Data Lakehouse to explore why lakehouses are the data architecture of the future with the father of the data warehouse, Bill Inmon.
Background and challenges
Asurion's Enterprise Data Service team is tasked with gathering over 3,500 data assets from the entire organization, providing one place where all the data can be cleaned, joined, analyzed, enriched and leveraged to create data products.
Previous iterations of data platforms, built mostly on top of traditional databases and data warehouse solutions, encountered challenges with scaling and cost due to the lack of compute and storage separation. With ever-increasing data volumes, a wide variety of data types (from structured database tables and APIs to data streams), demand for lower latency and increased velocity, the platform engineering team began to consider moving the whole ecosystem to Apache Spark™ and Delta Lake using a lakehouse architecture as the new foundation.
The previous platform was based on Lambda architecture, which introduced hard-to-solve problems, such as:
- data duplication and synchronization
- logic duplication, often using different technologies for batch and speed layer
- different ways to deal with late data
- data reprocessing difficulty due to the lack of transactional layer, which forced very close orchestration between rewrite updates or deletions
- readers trying to access that data, forcing platform maintenance downtimes.
Using traditional extract, transform, and load (ETL) tools on large data sets was restricted to Day-Minus-1 processing frequency, and the technology stack was vast and complicated.
Asurion's legacy data platform was operating at a massive scale, processing over 8,000 tables, 10,000 views, 2,000 reports and 2,500 dashboards. Ingestion data sources varied from database CDC feeds, APIs and flat files to streams from Kinesis, Kafka, SNS and SQS. The platform included a data warehouse combining hundreds of tables with many complicated dependencies and close to 600 data marts. Our next lakehouse had to solve for all of these use cases to truly unify on a single platform.
The Databricks Data Intelligence Platform Solution
A lakehouse architecture simplifies the platform by eliminating batch and speed layers, providing near real-time latency, supporting a variety of data formats and languages, and simplifying the technology stack into one integrated ecosystem.
To ensure platform scalability and future efficiency of our development lifecycle, we focused our initial design phases on ensuring decreased platform fragility and rigidity.
Platform fragility could be observed when a change in one place breaks functionality in another portion of the ecosystem. This is often seen in closely coupled systems. Platform rigidity is the resistance of the platform to accept changes. For example, to add a new column to a report, many jobs and tables have to be changed, making the change lifecycle long, large and more prone to errors. The Databricks Data Intelligence Platform simplified our approach to architecture and design of the underlying codebase, allowing for a unified approach to data movement from traditional ETL to streaming data pipelines between Delta tables.
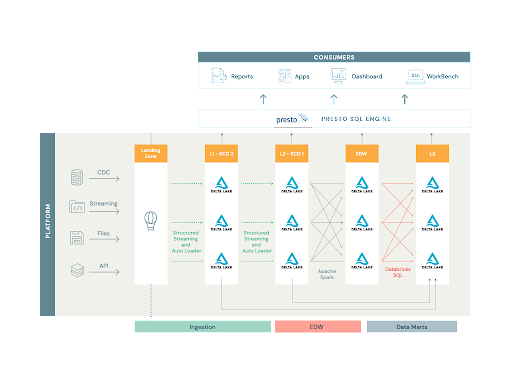
ETL job design
In the previous platform version, every one of the thousands of ingested tables had its own ETL mapping, making management of them and the change cycle very rigid. The goal of the new architecture was to create a single job that’s flexible enough to run thousands of times with different configurations. To achieve this goal, we chose Spark Structured Streaming, as it provided 'exactly-once' and 'at-least once' semantics, along with Auto Loader, which greatly simplified state management of each job. Having said that, having over 3,500 individuals Spark jobs would inevitably lead to a similar state as 3,500 ETL mappings. To avoid this problem, we built a framework around Spark using Scala and the fundamentals of object-oriented programming. (Editor’s note: Since this solution was implemented, Delta Live Tables has been introduced on the Databricks platform to substantially streamline the ETL process.)
We have created a rich set of readers, transformations and writers, as well as Job classes accepting details through run-time dependency injection. Thanks to this solution, we can configure the ingestion job to read from Kafka, Parquet, JSON, Kinesis and SQS into a data frame, then apply a set of common transformations and finally inject the steps to be applied inside of Spark Structured Streaming’s 'foreachBatch’ API to persist data into Delta tables.
ETL job scheduling
Databricks recommends running structured streaming jobs using ephemeral clusters, but there is a limit of 1,000 concurrently running jobs per workspace. Additionally, even if that limit wasn’t there, let's consider the smallest cluster to consist of one master and two worker nodes. Three nodes for each job would add up to over 10,000 nodes in total and since these are streaming jobs, these clusters would have to stay up all the time. We needed to devise a solution that would balance cost and management overhead within these constraints.
To achieve this, we divided the tables based on how frequently they are updated at the source and bundled them into job groups, one assigned to each ephemeral notebook.
The notebook reads the configuration database, collects all the jobs belonging to the assigned group, and executes them in parallel on the ephemeral cluster. To speed the processing up, we use Scala parallel collections, allowing us to run jobs in parallel up to the number of the cores on the driver node. Since different jobs are processing different amounts of data, running 16 or 32 jobs at a time provides equal and full CPU utilization of the cluster. This setup allowed us to run up to 1,000 slow-changing tables on one 25 node cluster, including appending and merging into bronze and silver layers inside of the foreachBatch API.
Data marts with Databricks SQL
We have an application where business users define SQL-based data transformations that they want to store as data marts. We take the base SQL and handle the execution and maintenance of the tables. This application must be available 24x7 even if we aren’t actively running anything. We love Databricks, but weren’t thrilled about paying interactive cluster rates for idle compute. Enter Databricks SQL. With this solution, SQL Endpoints gave us a more attractive price point and exposed an easy JDBC connection for our user-facing SQL application. We now have 600 data marts and are growing more in production in our lakehouse.
Summary
Our engineering teams at Asurion implemented a lakehouse architecture at large scale, including Spark Structured Streaming, Delta Lake and Auto Loader. In an upcoming blog post, we will discuss how we encountered and resolved issues related to scaling our solution to meet our needs.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.