Timeliness and Reliability in the Transmission of Regulatory Reports
by Antoine Amend and Fahmid Kabir
Managing risk and regulatory compliance is an increasingly complex and costly endeavour. Regulatory change has increased 500% since the 2008 global financial crisis and boosted the regulatory costs in the process. Given the fines associated with non-compliance and SLA breaches (banks hit an all-time high in fines of $10 billion in 2019 for AML), processing reports has to proceed even if data is incomplete. On the other hand, a track record of poor data quality is also "fined" because of "insufficient controls." As a consequence, many Financial Services Institutions (FSIs) are often left battling between poor data quality and strict SLAs, balancing between data reliability and data timeliness.
In this regulatory reporting solution accelerator, we demonstrate how Delta Live Tables can guarantee the acquisition and processing of regulatory data in real time to accommodate regulatory SLAs. With Delta Sharing and Delta Live Tables combined, analysts gain real-time confidence in the quality of regulatory data being transmitted. In this blog post, we demonstrate the benefits of the Lakehouse architecture to combine financial services industry data models with the flexibility of cloud computing to enable high governance standards with low development overhead. We will now explain what a FIRE data model is and how DLT can be integrated to build robust data pipelines.
FIRE data model
The Financial Regulatory data standard (FIRE) defines a common specification for the transmission of granular data between regulatory systems in finance. Regulatory data refers to data that underlies regulatory submissions, requirements and calculations and is used for policy, monitoring and supervision purposes. The FIRE data standard is supported by the European Commission, the Open Data Institute and the Open Data Incubator FIRE data standard for Europe via the Horizon 2020 funding programme. As part of this solution, we contributed a PySpark module that can interpret FIRE data models into Apache Spark™ operating pipelines.

Delta Live Tables
Databricks recently announced a new product for data pipelines orchestration, Delta Live Tables, which makes it easy to build and manage reliable data pipelines at enterprise scale. With the ability to evaluate multiple expectations, discard or monitor invalid records in real time, the benefits of integrating the FIRE data model on Delta Live Tables are obvious. As illustrated in the following architecture, Delta Live Table will ingest granular regulatory data landing onto cloud storage, schematize content and validate records for consistency in line with the FIRE data specification. Keep reading to see us demo the use of Delta Sharing to exchange granular information between regulatory systems in a safe, scalable, and transparent manner.
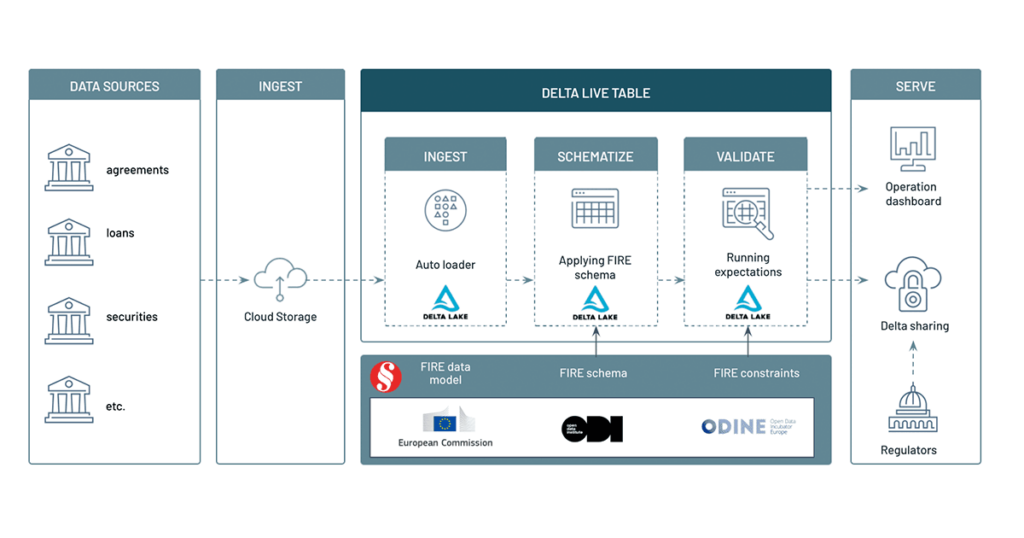
Enforcing schema
Even though some data formats may "look" structured (e.g. JSON files), enforcing a schema is not just a good engineering practice; in enterprise settings, and especially in the space of regulatory compliance, schema enforcement guarantees any missing field to be expected, unexpected fields to be discarded and data types to be fully evaluated (e.g. a date should be treated as a date object and not a string). It also proof-tests your systems for eventual data drift. Using the FIRE pyspark module, we programmatically retrieve the Spark schema required to process a given FIRE entity (collateral entity in that example) that we apply on a stream of raw records.
In the example below, we enforce schema to incoming CSV files. By decorating this process using @dlt annotation, we define our entry point to our Delta Live Table, reading raw CSV files from a mounted directory and writing schematized records to a bronze layer.
Evaluating expectations
Applying a schema is one thing, enforcing its constraints is another. Given the schema definition of a FIRE entity (see example of the collateral schema definition), we can detect if a field is required or not. Given an enumeration object, we ensure its values are consistent (e.g. currency code). In addition to the technical constraints from the schema, the FIRE model also reports business expectations, such as minimum, maximum, monetary and maxItems. All these technical and business constraints will be programmatically retrieved from the FIRE data model and interpreted as a series of Spark SQL expressions.
With Delta Live Tables, users have the ability to evaluate multiple expectations at once, enabling them to drop invalid records, simply monitoring data quality or abort an entire pipeline. In our specific scenario, we want to drop records failing any of our expectations, which we later store to a quarantine table, as reported in the notebooks provided in this blog.
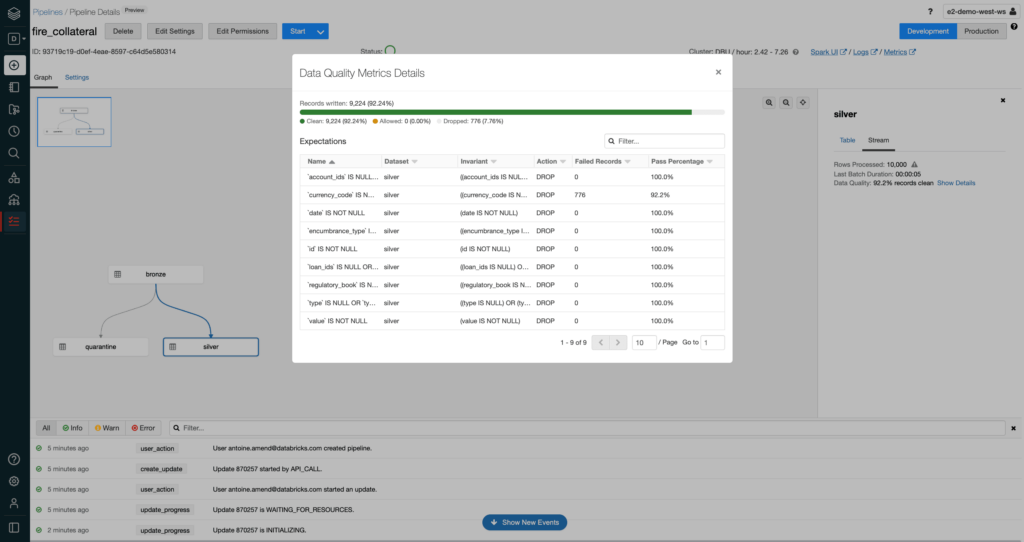
With only a few lines of code, we ensured that our silver table is both syntactically (valid schema) and semantically (valid expectations) correct. As shown below, compliance officers have full visibility around the number of records being processed in real time. In this specific example, we ensured our collateral entity to be exactly 92.2% complete (quarantine handles the remaining 7.8%).
Operations data store
In addition to the actual data stored as delta files, Delta Live Tables also stores operation metrics as "delta" format under system/events. We follow a standard pattern of the Lakehouse architecture by "subscribing" to new operational metrics using AutoLoader, processing system events as new metrics unfold -- in batch or in real time. Thanks to the transaction log of Delta Lake that keeps track of any data update, organizations can access new metrics without having to build and maintain their own checkpointing process.
With all metrics available centrally into an operation store, analysts can use Databricks SQL to create simple dashboarding capabilities or more complex alerting mechanisms to detect data quality issues in real time.

The immutability aspect of the Delta Lake format coupled with the transparency in data quality offered by Delta Live Tables allows financial institutions to "time travel" to specific versions of their data that matches both volume and quality required for regulatory compliance. In our specific example, replaying our 7.2% of invalid records stored in quarantine will result in a different Delta version attached to our silver table, a version that can be shared amongst regulatory bodies.
Transmission of regulatory data
With full confidence in both data quality and volume, financial institutions can safely exchange information between regulatory systems using Delta Sharing, an open protocol for enterprise data exchange. Not constraining end users to a same platform nor relying on complex ETL pipelines to consume data (accessing data files through a SFTP server for instance), the open source nature of Delta Lake makes it possible for data consumers to access schematized data natively from Python, Spark or directly through MI/BI dashboards (such as Tableau or PowerBI).
Although we could be sharing our silver table as-is, we may want to use business rules that only share regulatory data when a predefined data quality threshold is met. In this example, we clone our silver table at a different version and to a specific location segregated from our internal networks and accessible by end users (demilitarized zone, or DMZ).
Although the Delta Sharing open source solution relies on a sharing server to manage permission, Databricks leverages Unity Catalog to centralize and enforce access control policies, provide users with full audit logs capability and simplify access management through its SQL interface. In the example below, we create a SHARE that includes our regulatory tables and a RECIPIENT to share our data with.
Any regulator or user with granted permissions can access our underlying data using a personal access token exchanged through that process. For more information about Delta Sharing, please visit our product page and contact your Databricks representative.
Proof test your compliance
Through this series of notebooks and Delta Live Tables jobs, we demonstrated the benefits of the Lakehouse architecture in the ingestion, processing, validation and transmission of regulatory data. Specifically, we addressed the need for organizations to ensure consistency, integrity and timeliness of regulatory pipelines that could be easily achieved using a common data model (FIRE) coupled with a flexible orchestration engine (Delta Live Tables). With Delta Sharing capabilities, we finally demonstrated how FSIs could bring full transparency and confidence to the regulatory data exchanged between various regulatory systems while meeting reporting requirements,reducing operation costs and adapting to new standards.
Get familiar with the FIRE data pipeline using the attached notebooks and visit our Solution Accelerators Hub to get up to date with our latest solutions for financial services.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.