Summer 2021 Databricks Internship - Their Work and Their Impact!
With COVID precautions still in place, the 2021 Databricks Software Engineering Summer internship was conducted virtually with members of the intern class joining us from their home offices located throughout the world. As always, this year’s interns collaborated on a number of impactful projects, covering a wide range of data and computer science disciplines, from software development and algorithm design to cloud infrastructure and pipeline architecture and management. This blog features nine of this year’s team members, who share their internship experience and details of their intern projects.
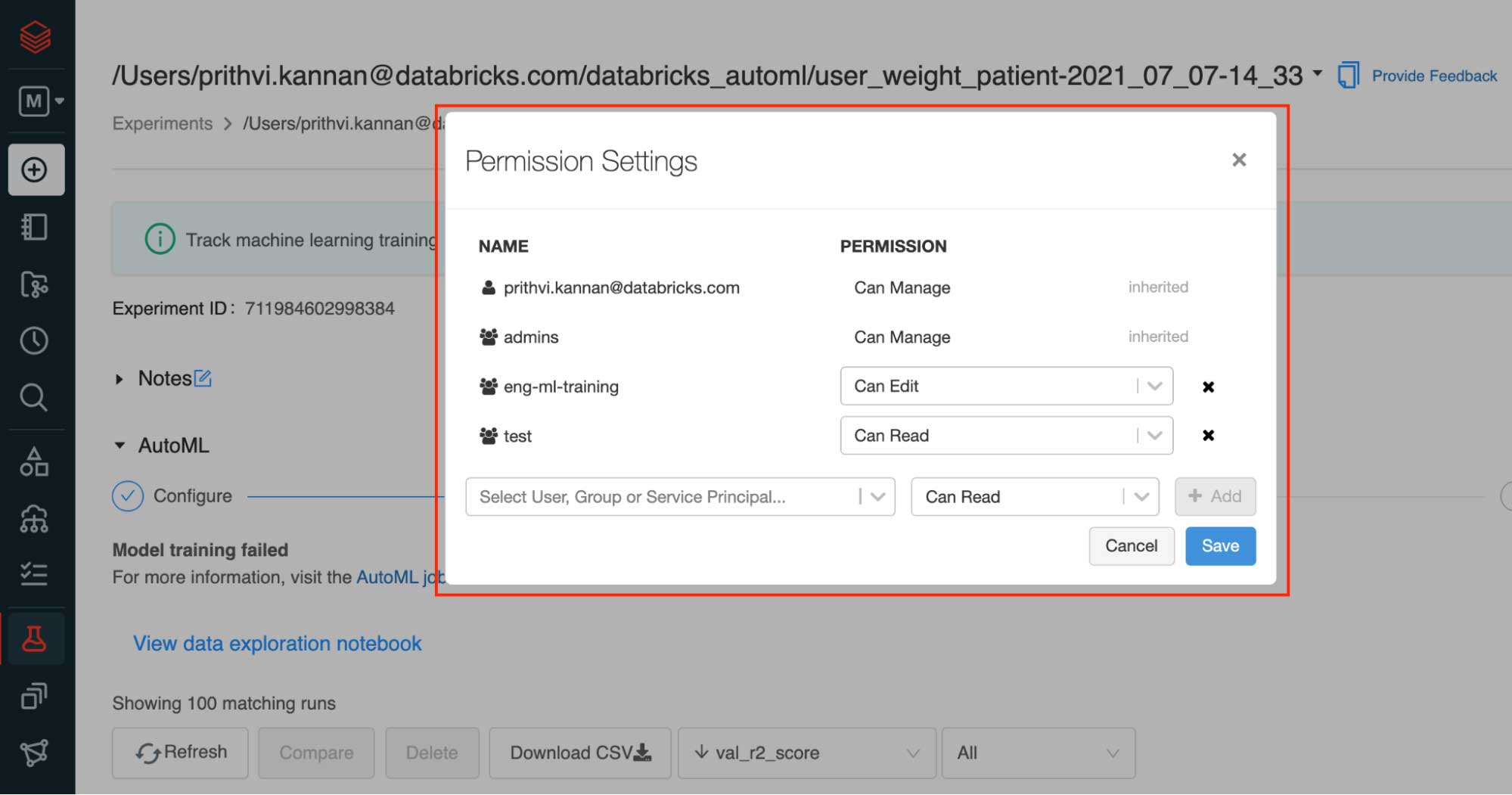
Prithvi Kannan - MLFlow Experiment Actions
MLflow Experiments are used extensively by data scientists to track and monitor ML training processes collaboratively. Prithvi’s internship focused on making MLflow Experiments, an open source platform for managing the end-to-end machine learning lifecycle, first-class objects on Databricks. To execute on this goal, he built an Experiments Permission API that enabled customers to programmatically view and update permissions on Experiments. Next, he worked on giving users the ability to perform Managed Actions on an experiment from within the experiment observatory and experiment page. To deliver these features, Prithvi delivered the features through an end-to-end product development process at Databricks, wearing many hats – he collaborated with PMs on product requirements, UX designers to nail the user interface designs, Tech Leads for engineering design decisions, and finally with tech writers to polish product release statements before rollout. Ultimately, we were excited to make permissions and sharing easier on Databricks ML!
Kritin Singhal - Migrating Auth Session Caches to use Highly Available Distributed Redis Clusters
Kritin worked on the Applications Infrastructure team to improve and scale Databricks authentication service to handle 1 million requests/second. The auth service used local cache in the Kubernetes pod, which made multiple duplicated calls to the database. Kritin onboarded Redis Clusters to the team and deployed a Redis Cluster Coordinator that automated cluster creation and failovers, leading to a highly available caching infrastructure with horizontal scaling and high throughput. He then migrated the local caches to an optimized caching flow using Redis and Guava Local Cache, enabling the team to expand and scale the authentication service pods horizontally and reducing traffic to the database. This improvement would help Databricks scale exponentially on the top-most layer!
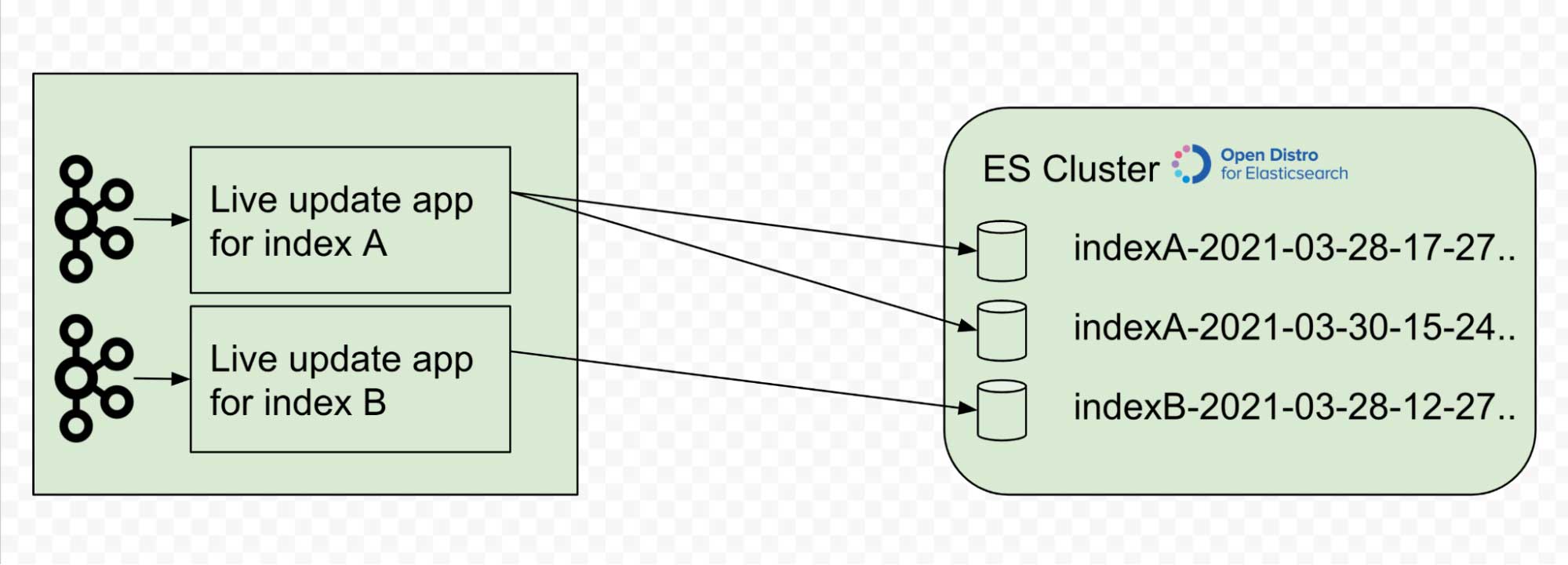
Tianyi Zhang - Search Index Live Updater
Tianyi worked with the Data Discovery team to design and implement the live updater, a new service for bringing Elasticsearch indices up-to-date by rewinding and replaying Change Data Capture (CDC) events from input streams with high throughput. It is a major component of the universal search platform, which allows users to search and discover across all the entities within their Databricks workspace – down to the metadata, including notebooks, models, experiments, repos and files they own or create. It is designed to operate in both Azure and AWS and is extensible for other newly introduced search entities in the future. The new search infrastructure will unify existing search experiences with varying capabilities and significantly improve users' experience finding the right data asset traits.
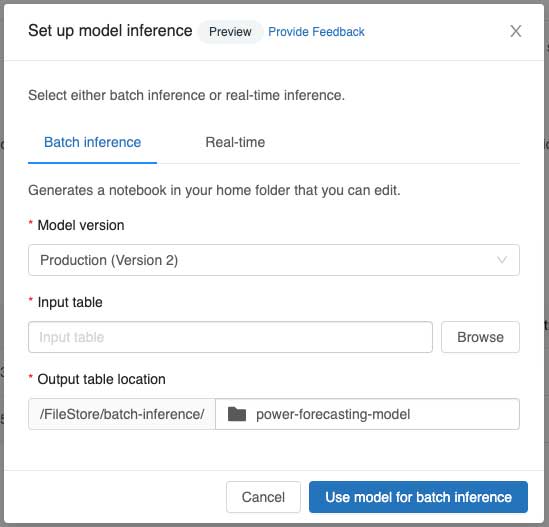
Steven Chen - Auto-generating Batch Inference Notebooks
This summer, Steven got to work on the ML Inference team to improve the customer user journey for using models in the MLflow model registry. Models are often used to generate predictions regularly on batches of data or predict real-time data by setting up a REST API. Steven’s project focused on building a new feature that auto-generates a batch inference notebook that recreates the training environment and generates and saves predictions on an input table. In this role, Steven had a chance to work on one of Databricks’ open source projects, MLflow, to log additional dependencies and metadata necessary for the model environment, which was released during his internship. Finally, he connected the feature to the MLflow UI to allow for one-click batch inference notebook generation and real-time serving.
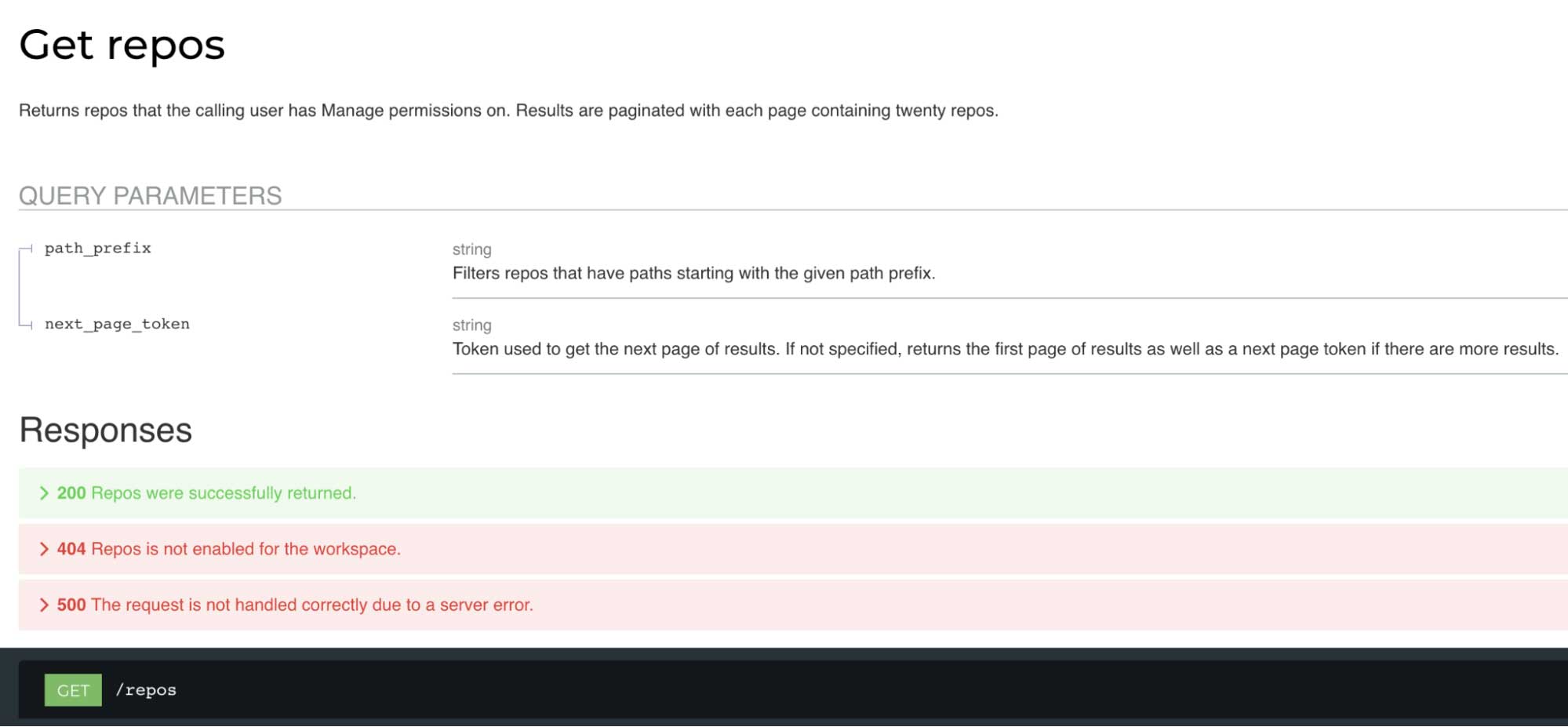
Leon Bi — Databricks Repos CRUD API / Ipynb File Support
Leon worked with the Repos team to help implement a CRUD API for the Databricks Repos feature. Databricks Repos provides repository-level integration with Git providers by syncing code in a Databricks workspace with a remote Git repository and lets users use Git functionality such as cloning a remote repo, managing branches, pushing and pulling changes, and visually comparing differences upon commit. With the new CRUD API, users can automate the lifecycle management of their repos by hitting REST endpoints. Other API features include endpoints to manage user access levels for each Repo and cursor pagination for the list. Finally, Leon implemented Ipynb file support in Repos. Ipynb (Jupyter) notebooks are the industry standard for interactive data science notebooks, but this file format was not previously supported in Repos. Now, customers have the ability to import, edit and run their existing Ipynb notebooks within Repos.
James Wei - SCIM API Token At Accounts Level
James worked with the Identity & Access Management team to design and build scoped API tokens that enable user provisioning in Databricks accounts. Accounts are a higher-level abstraction that customers can use to manage multiple workspaces. Previously, user provisioning had to be done on a per-workspace basis and account-level tokens were nonexistent, and access tokens in workspaces could be used to access almost any API. James rebuilt the Databricks token infrastructure to support accounts and introduced a new scoped token authenticator that validates the defined scopes for a token against the authorization policy of an endpoint. He then created a scoped token that can sync enterprise users and groups between an identity provider and Databricks. As a result, user provisioning moved from a multi-step process per workspace into a one-time process per account. This project played a critical role in simplifying the customer journey when adding users into Databricks, and will undoubtedly help drive usage across the Databricks platform!
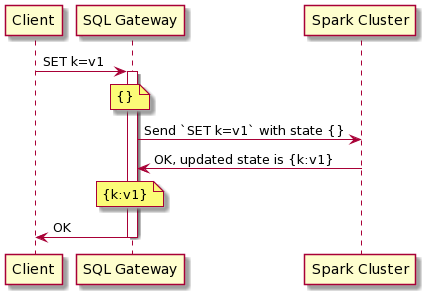
Brian Wu - Stateless Sessions Thrift Protocol
Brian worked with the SQL Gateway team to simplify and improve the consistency of session state updates in Databricks SQL, which allows customers to operate a multi-cloud lakehouse architecture at a better price/performance) session state updates. SQL commands run within the context of a SQL session, but multiple commands in the same session can run across different Apache Spark clusters. Brian’s contributions modified the protocol used to communicate with these clusters, allowing them to be stateless for sessions while ensuring all commands run with the latest session state. He also implemented command-scoped session state updates, so concurrent commands in the same session executing on the same cluster don’t interfere with each other. His project improves consistency, reduces code complexity and allows the engineering team to simplify the process of adding new features to Databricks SQL.
Regina Wang - SQL Autocomplete
Over the course of the summer, Regina worked on improving the SQL code editing experience for our main notebook product. To this end, she first added in context-aware results for SQL autocomplete -- that is, when making autocomplete recommendations, the entire query would be taken into account. This allows for users to have more relevant autocomplete results and more seamless integration of our notebooks with Redash’s SQL parser. In addition, Regina added the ability to display SQL autocomplete and syntax highlighting within Python notebooks, a high-demand feature that enables customers to easily sift through databases and tables while coding in Python. When fully rolled out, these features will improve developer productivity and are touched by ~65% of all customers using our main Python notebook.
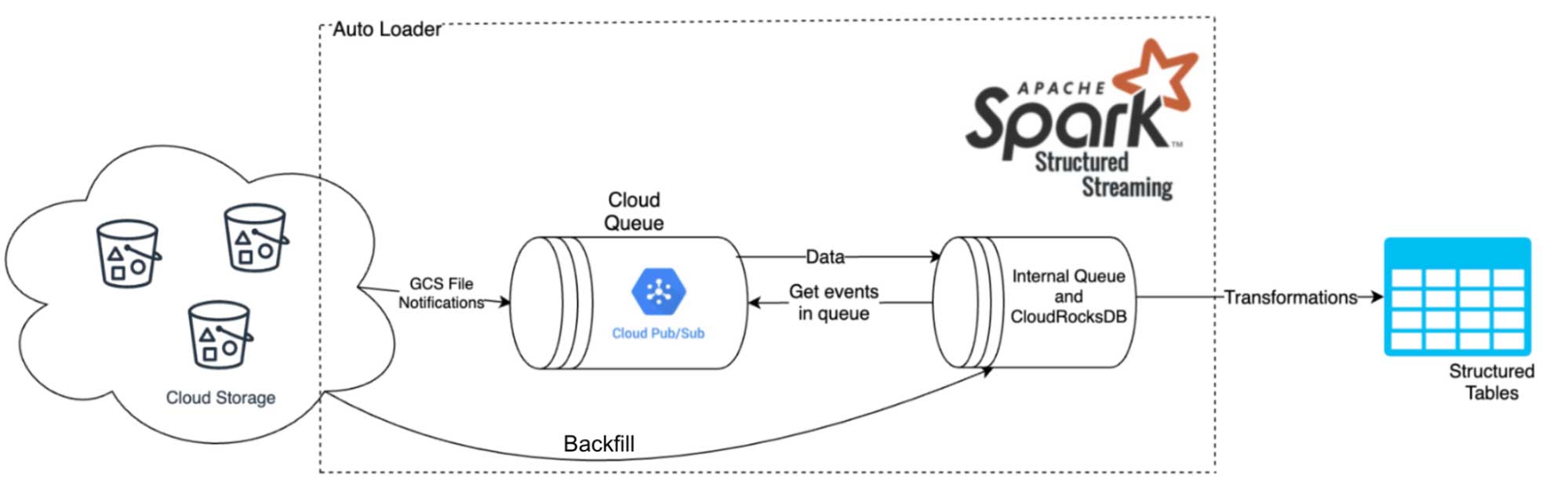
Steve Jiang - Migration from SQS/AQS to AutoLoader.
Steve worked with the Ingestion team to build scalable ingestion from Google Cloud Storage via the Auto Loader streaming source. This approach utilizes the GCP PubSub messaging service and event notifications to process and stream changes from a GCS bucket. This form of ingestion is significantly more scalable than the alternative, which is based on repeated directory listings to ingest new files, and will make Auto Loader a much more feasible option for customers with large amounts of data stored on GCP. He also worked on supporting schema evolution for Avro files by extendingDatabricks' schema inference functionality to merge multiple Avro schemas into one unified schema and building rescued data for Avro files. The new schema inference allows streams to run continuously while accommodating new fields that may pop up in the data schema over time. Rescued data will serve to capture any data that would otherwise be lost due to mismatched schemas in Avro files that have different schemas than expected.
We want to extend a big “thank you” to all of our Summer 2021 engineering interns, who helped develop some important features and updates that will be widely used by our customers.
Want to help make an impact? Our Software Engineering Internship and New Grad (2022 Start) roles are open! We’re always looking for eager engineers that are excited to grow, learn and contribute to building an innovative company together!
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.