Evolution of the Sql Language at Databricks: Ansi Standard by Default and Easier Migrations from Data Warehouses
by Serge Rielau, Shant Hovsepian and Reynold Xin
Databricks SQL is now generally available on AWS and Azure.
Today, we are excited to announce that Databricks SQL will use the ANSI standard SQL dialect by default. This follows the announcement earlier this month about Databricks SQL’s record-setting performance and marks a major milestone in our quest to support open standards. This blog post discusses how this update makes it easier to migrate your data warehousing workloads to Databricks lakehouse platform. Moreover, we are happy to announce improvements in our SQL support that make it easier to query JSON and perform common tasks more easily.
Migrate easily to Databricks SQL
We believe Databricks SQL is the best place for data warehousing workloads, and it should be easy to migrate to it. Practically, this means changing as little of your SQL code as possible. We do this by switching out the default SQL dialect from Spark SQL to Standard SQL, augmenting it to add compatibility with existing data warehouses, and adding quality control for your SQL queries.
Standard SQL we can all agree on
With the SQL standard, there are no surprises in behavior or unfamiliar syntax to look up and learn.
String concatenation is such a common operation that the SQL standard designers gave it its own operator. The double-pipe operator is simpler than having to perform a concat() function call:
The FILTER clause, which has been in the SQL standard since 2003, limits rows that are evaluated during an aggregation. Most data warehouses require a complex CASE expression nested within the aggregation instead:
SQL user-defined functions (UDFs) make it easy to extend and modularize business logic without having to learn a new programming language:
Compatibility with other data warehouses
During migrations, it is common to port hundreds or even thousands of queries to Databricks SQL. Most of the SQL you have in your existing data warehouse can be dropped in and will just work on Databricks SQL. To make this process simpler for customers, we continue to add SQL features that remove the need to rewrite queries.
For example, a new QUALIFY clause to simplify filtering window functions makes it easier to migrate from Teradata. The following query finds the five highest-spending customers in each day:
We will continue to increase compatibility features in the coming months. If you want us to add a particular SQL feature, don’t hesitate to reach out.
Quality control for SQL
With the adoption of the ANSI SQL dialect, Databricks SQL now proactively alerts analysts to problematic queries. These queries are uncommon but they are best caught early so you can keep your lakehouse fresh and full of high-quality data. Below is a selection of such changes (see our documentation for a full list).
- Invalid input values when casting a STRING to an INTEGER
- Arithmetic operations that cause an overflow
- Division by zero
Easily and efficiently query and transform JSON
If you are an analyst or data engineer, chances are you have worked with unstructured data in the form of JSON. Databricks SQL natively supports ingesting, storing and efficiently querying JSON. With this release, we are happy to announce improvements that make it easier than ever for analysts to query JSON.
Let’s take a look at an example of how easy it is to query JSON in a modern manner. In the query below, the raw column contains a blob of JSON. As demonstrated, we can query and easily extract nested fields and items from an array while performing a type conversion:
With Databricks SQL you can easily run these queries without sacrificing performance or by having to extract the columns out of JSON into separate tables. This is just one way in which we are excited to make life easier for analysts.
Simple, elegant SQL for common tasks
We have also spent time doing spring cleaning on our SQL support to make other common tasks easier. There are too many new features to cover in a blog post, but here are some favorites.
Case-insensitive string comparisons are now easier:
Shared WINDOW frames save you from having to repeat a WINDOW clause. Consider the following example where we reuse the win WINDOW frame to calculate statistics over a table:
Multi-value INSERTs make it easy to insert multiple values into a table without having to use the UNION keyword, which is common most other data warehouses:
Lambda functions are parameterized expressions that can be passed to certain SQL functions to control their behavior. The example below passes a lambda to the transform function, concatenating together the index and values of an array (themselves an example of structured types in Databricks SQL).
Update data easily with standard SQL
Data is rarely static, and it is common to to update a table based on changes in another table. We are making it easy for users to deduplicate data in tables, create slowly-changing data and more with a modern, standard SQL syntax.
Let’s take a look at how easy it is to update a customers table, merging in new data as it arrives:
Needless to say, you do not sacrifice performance with this capability as table updates are blazing fast. You can find out more about the ability to update, merge and delete data in tables here.
Taking it for a spin
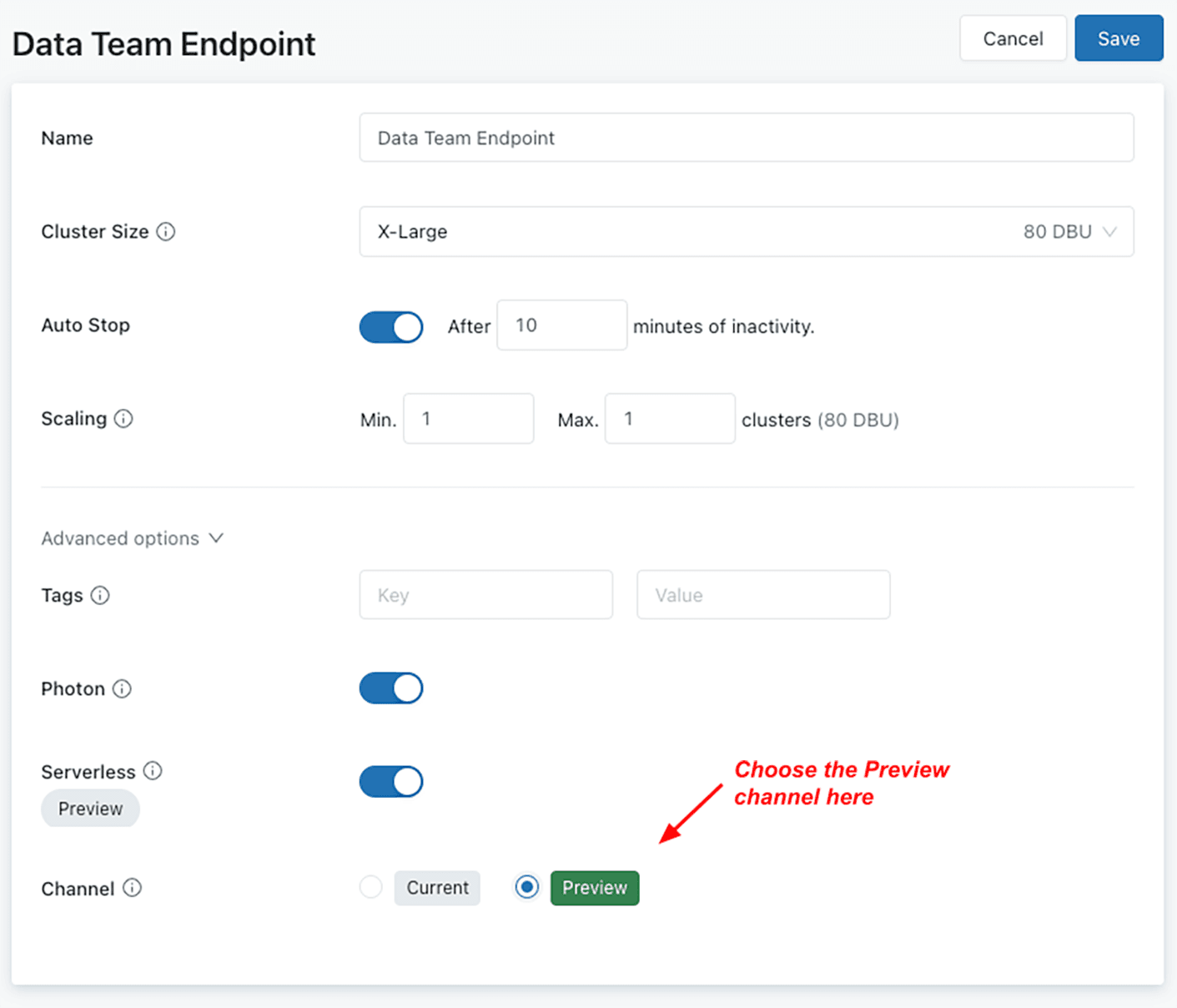
We understand language dialect changes can be disruptive. To facilitate the rollout, we are happy to announce a new feature, channels, to help customers safely preview upcoming changes.
When you create or edit a SQL endpoint, you can now choose a channel. The “current” channel contains generally available features while the preview channel contains upcoming features like the ANSI SQL dialect.
To test out the ANSI SQL dialect, click SQL Endpoints in the left navigation menu, click on an endpoint and change its channel. Changing the channel will restart the endpoint, and you can always revert this change later. You can now test your queries and dashboards on this endpoint.
You can also test the ANSI SQL dialect by using the SET command, which enables it just for the current session:
Please note that we do NOT recommend setting ANSI_MODE to false in production. This parameter will be removed in the future, hence you should only set it to FALSE temporarily for testing purposes.
The future of SQL at Databricks is open, inclusive and fast
Databricks SQL already set the world record in performance, and with these changes, it is standards compliant. We are excited about this milestone, as it is key in dramatically improving usability and simplifying workload migration from data warehouses over to the lakehouse platform.
Please learn more about changes included in the ANSI SQL dialect. Note that the ANSI dialect is not enabled as default yet for existing or new clusters in the Databricks data science and engineering workspace. We are working on that next.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.