Databricks’ Open Source Genomics Toolkit Outperforms Leading Tools
Check out the solution accelerator to download the notebooks referred throughout this blog.
Genomic technologies are driving the creation of new therapeutics, from RNA vaccines to gene editing and diagnostics. Progress in these areas motivated us to build Glow, an open-source toolkit for genomics machine learning and data analytics. The toolkit is natively built on Apache Spark™, the leading engine for big data processing, enabling population-scale genomics.
The project started as an industry collaboration between Databricks and the Regeneron Genetics Center. The goal is to advance research by building the next generation of genomics data analysis tools for the community. We took inspiration from bioinformatics libraries such as Hail, Plink and bedtools, married with best-in-class techniques for large-scale data processing. Glow is now 10x more computationally efficient than industry leading tools for genetic association studies.
The vision for Glow and genomic analysis at scale
The primary bottleneck slowing the growth in genomics is the complexity of data management and analytics. Our goal is to make it simple for data engineers and data scientists who are not trained in bioinformatics to contribute to genomics data processing in distributed cloud computing environments. Easing this bottleneck will in turn drive up the demand for more sequencing data in a positive feedback loop.
When to use Glow
Glow's domain of applicability falls in aggregation and mining of genetic variant data. Particularly for data analyses that are run many times iteratively or that take more than a few hours to complete, such as:
- Annotation pipelines
- Genetic association studies
- GPU-based deep learning algorithms
- Transforming data into and out of bioinformatics tools.
As an example, Glow includes a distributed implementation of the Regenie method. You can run Regenie on a single node, which is recommended for academic scientists. But for industrial applications, Glow is the world's most cost effective and scalable method of running thousands of association tests. Let's walk through how this works.
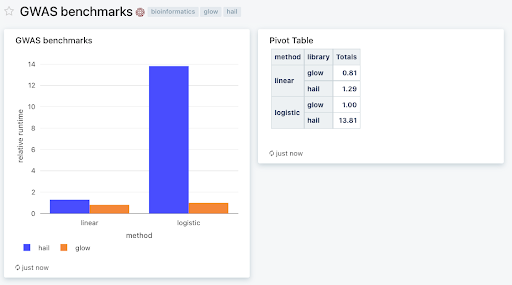
Benchmarking Glow against Hail
We focused on genetic association studies for benchmarks because they are the most computationally intensive steps in any analytics pipeline. Glow is >10x more performant for Firth regression relative to Hail without trading off accuracy (Figure 1). We were able to achieve this performance because we apply an approximate method first, restricting the full method to variants with a suggestive association with disease (P Glow documentation.
Glow on the Databricks Lakehouse Platform
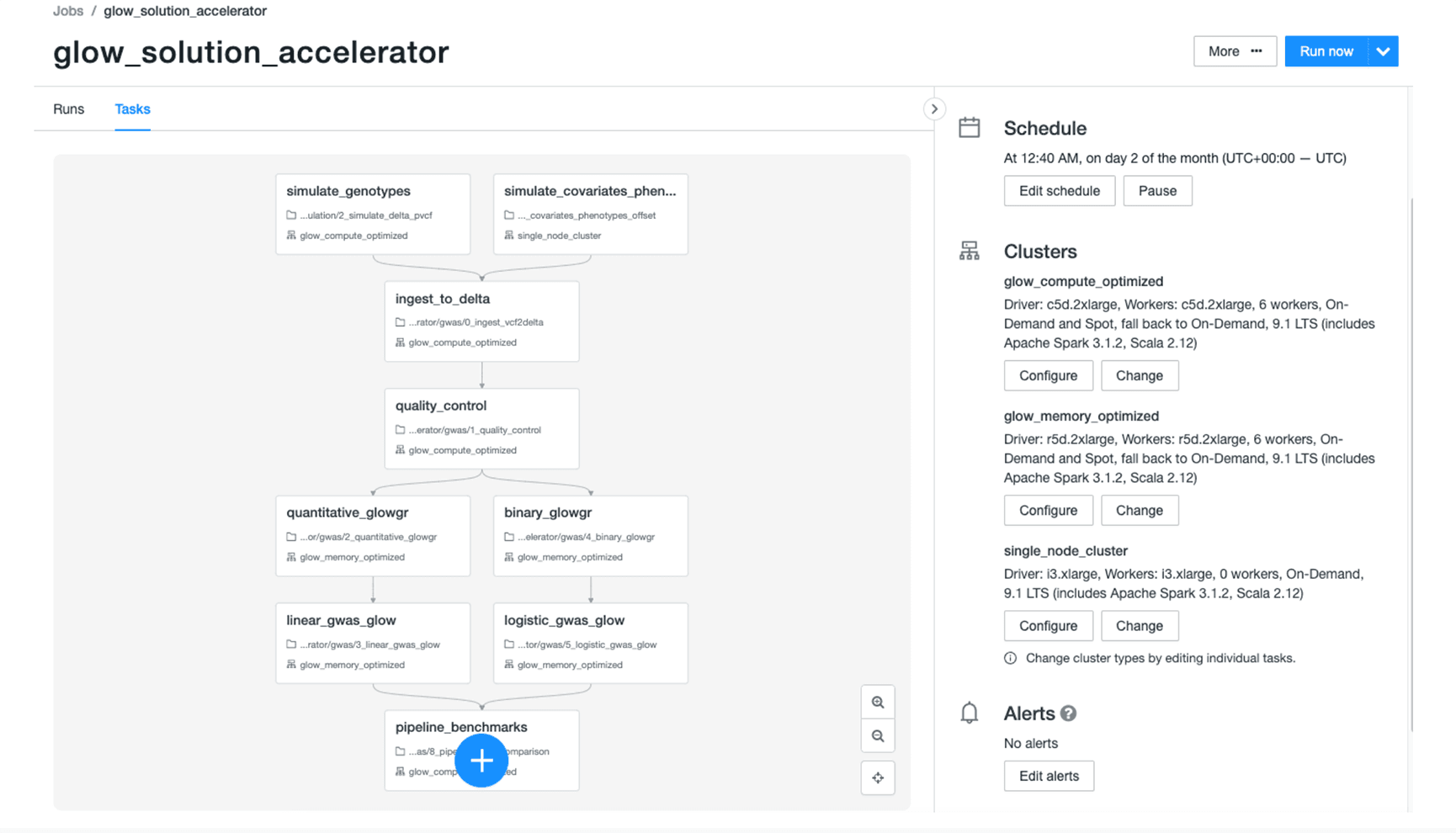
We had a small team of engineers working on a tight schedule to develop Glow. So how were we able to catch up with the world's leading biomedical research institute, the brain power behind Hail? We did it by developing Glow on the Databricks Lakehouse Platform in collaboration with industry partners. Databricks provides infrastructure that makes you productive with genomics data analytics. For example, you can use Databricks Jobs to build complex pipelines with multiple dependencies (Figure 2).
Furthermore, Databricks is a secure platform trusted by both Fortune 100 and healthcare organizations with their most sensitive data, adhering to principles of data governance (FAIR), security and compliance (HIPAA and GDPR).
What lies in store for the future?
Glow is now at a v1 level of maturity, and we are looking to the community to help contribute to build and extend it. There's lots of exciting things in store.
Genomics datasets are so large that batch processing with Apache Spark can hit capacity limits of certain cloud regions. This problem will be solved by the open Delta Lake format, which unifies batch and stream processing. By leveraging streaming, Delta Lake enables incremental processing of new samples or variants, with edge cases quarantined for further analysis. Combining Glow with Delta Lake will solve the "n+1 problem" in genomics.
A further problem in genomics research is data explosion. There are over 50 copies of the Cancer Genome Atlas on Amazon Web Services alone. The solution proposed today is a walled garden, managing datasets inside genomics domain platforms. This solves data duplication, but then locks data into platforms.
This friction will be eased through Delta Sharing, an open protocol for secure real-time exchange of large datasets, which will enable secure data sharing between organizations, clouds and domain platforms. Unity Catalog will then make it easy to discover, audit and govern these data assets.
We're just at the beginning of the industrialization of genomics data analytics. To learn more, please see the Glow documentation, tech talks on YouTube, and workshops.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.