Using Apache Flink With Delta Lake
Incorporating Flink datastreams into your Lakehouse Architecture
by Max Fisher, Dylan Gessner and Vini Jaiswal
As with all parts of our platform, we are constantly raising the bar and adding new features to enhance developers’ abilities to build the applications that will make their Lakehouse a reality. Building real-time applications on Databricks is no exception. Features like asynchronous checkpointing, session windows, and Delta Live Tables allow organizations to build even more powerful, real-time pipelines on Databricks using Delta Lake as the foundation for all the data that flows through the lakehouse.
However, for organizations that leverage Flink for real-time transformations, it might appear that they are unable to take advantage of some of the great Delta Lake and Databricks features, but that is not the case. In this blog we will explore how Flink developers can build pipelines to integrate their Flink applications into the broader Lakehouse architecture.
A stateful Flink application
Let’s use a credit card company to explore how we can do this.
For credit card companies, preventing fraudulent transactions is table-stakes for a successful business. Credit card fraud poses both reputational and revenue risk to a financial institution and, therefore, credit card companies must have systems in place to remain constantly vigilant in preventing fraudulent transactions. These organizations may implement monitoring systems using Apache Flink, a distributed event-at-a-time processing engine with fine-grained control over streaming application state and time.
Below is a simple example of a fraud detection application in Flink. It monitors transaction amounts over time and sends an alert if a small transaction is immediately followed by a large transaction within one minute for any given credit card account. By leveraging Flink’s ValueState data type and KeyedProcessFunction together, developers can implement their business logic to trigger downstream alerts based on event and time states.
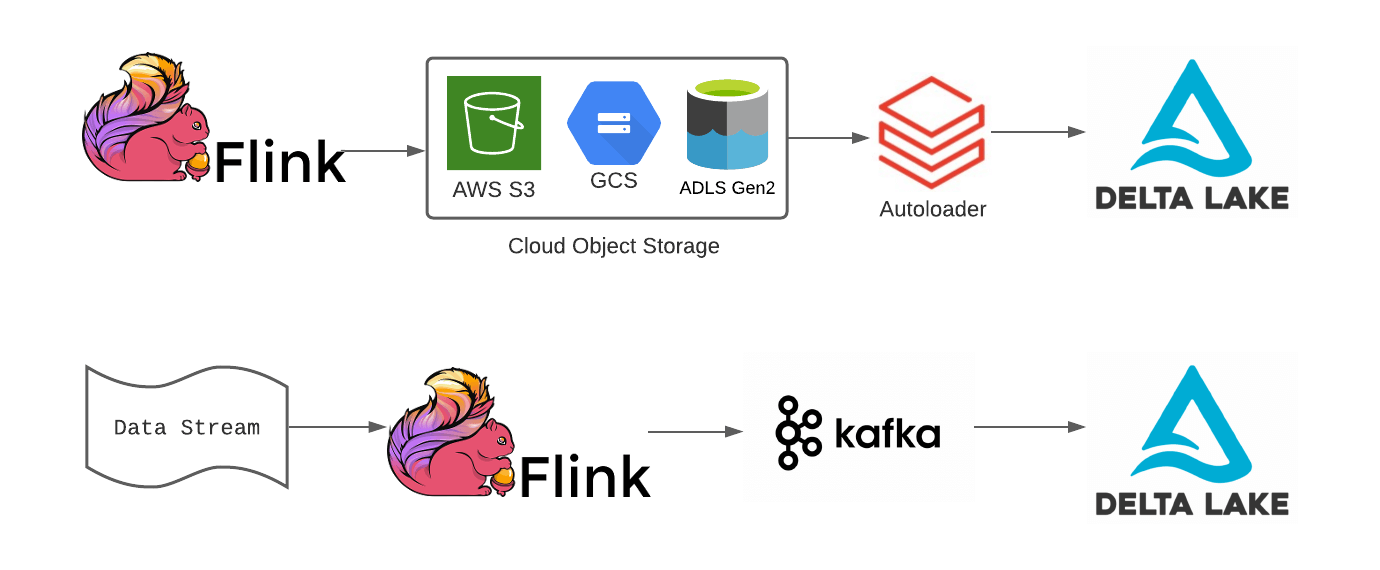
Integrating Flink applications using cloud object store sinks with Delta Lake
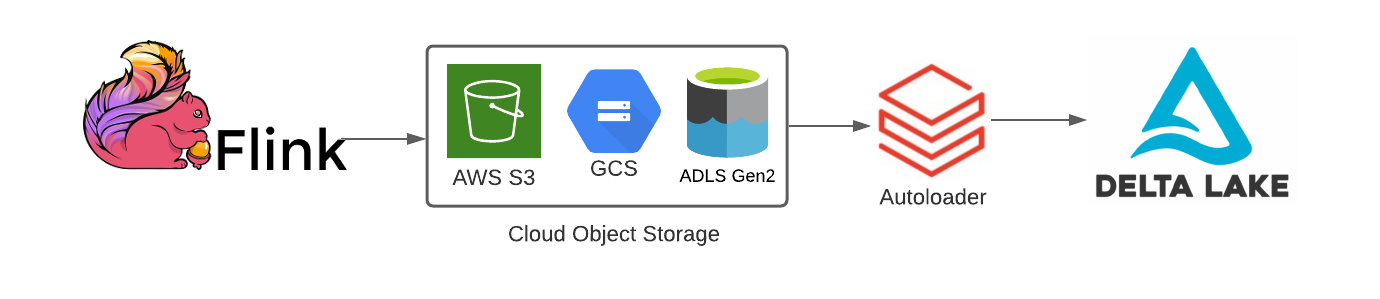
Fortunately, Databricks Auto Loader makes it easy to stream data landed into object storage from Flink applications into Delta Lake tables for downstream ML and BI on that data.
Delta Lake tables automatically optimize the physical layout of data in cloud storage through compaction and indexing to mitigate the small file problem and enable performant downstream analytics.
Much like Auto-Loader can transform a static source like cloud storage into a streaming datasource, Delta Lake tables also function as streaming sources despite being stored in object storage. This means that organizations using Flink for operational use cases can leverage this architectural pattern for streaming analytics without sacrificing their real-time requirements.
Integrating Flink applications using Apache Kafka and Delta Lake
Let’s say the credit card company wanted to use their fraud detection model that they built in Databricks, and the model to score the data in real-time. Pushing files to cloud storage might not be fast enough for some SLAs around fraud detection, so they can write data from their Flink application to message bus systems like Kafka, AWS Kinesis, or Azure Event Hub. Once the data is written to Kafka, a Databricks job can read from Kafka and write to Delta Lake.

For Flink developers, there is a Kafka Connector that can be integrated with your Flink projects to allow for DataStream API and Table API-based streaming jobs to write out the results to an organization’s Kafka cluster. Note that as of the writing of this blog, Flink does not come packaged with this connector, so you will need to include the Kafka Connector JAR in your project’s build file (i.e. pom.xml, build.sbt, etc).
Here is an example of how you would write the results of your DataStream in Flink to a topic on the Kafka Cluster:
Now you can easily leverage Databricks to write a Structured Streaming application to read from the Kafka topic that the results of the Flink DataStream wrote out to. To establish the read from Kafka...
Once the data has been schematized, we can load our model and score the microbatch of data that Spark processes after each trigger. For a more detailed example of Machine Learning models and Structured streaming, check this article out in our documentation.
Now we can write to Delta by configuring the writeStream and pointing it to our fraud_predictions Delta Lake table. This will allow us to build important reports on how we track and handle fraudulent transactions for our customers; we can even use the outputs to understand how our model is doing over time in terms of how many false positives it outputs or accurate assessments.
Conclusion
With both of these options, Flink and Autoloader or Flink and Kafka, organizations can still leverage the features of Delta Lake and ensure they are integrating their Flink applications into their broader Lakehouse architecture. Databricks has also been working with the Flink community to build a direct Flink to Delta Lake connector.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.