“...incorporating machine learning into a company’s application development is difficult…”
It’s been almost a decade since Marc Andreesen hailed that software was eating the world and, in tune with that, many enterprises have now embraced agile software engineering and turned it into a core competency within their organization. Once ‘slow’ enterprises have managed to introduce agile development teams successfully, with those teams decoupling themselves from the complexity of operational data stores, legacy systems and third-party data products by interacting ‘as-a-service’ via APIs or event-based interfaces. These teams can instead focus on the delivery of solutions that support business requirements and outcomes seemingly having overcome their data challenges.
Of course, little stays constant in the world of technology. The impact of cloud computing, huge volumes and new types of data, and more than a decade of close collaboration between research and business has created a new wave. Let’s call this new wave the AI wave.
Artificial intelligence (AI) gives you the opportunity to go beyond purely automating how people work. Instead, data can be exploited to automate predictions, classifications and actions for more effective, timely decision making - transforming aspects of your business such as responsive customer experience. Machine learning (ML) goes further to train off-the-shelf models to meet requirements that have proven too complex for coding alone to address.
But here's the rub: incorporating ML into a company’s application development is difficult. ML right now is a more complex activity than traditional coding. Matei Zaharia, Databricks co-founder and Chief Technologist, proposed three reasons for that. First, the functionality of a software component reliant on ML isn’t just built using coded logic, as is the case in most software development today. It depends on a combination of logic, training data and tuning. Second, its focus isn’t in representing some correct functional specification, but on optimizing the accuracy of its output and maintaining that accuracy once deployed. And finally, the frameworks, model architectures and libraries a ML engineer relies on typically evolve quickly and are subject to change.
Each of these three points bring their own challenges, but within this article I want to focus on the first point, which highlights the fact that data is required within the engineering process itself. Until now, application development teams have been more concerned with how to connect to data at test or runtime, and they solved problems associated with that by building APIs, as described earlier. But those same APIs don’t help a team exploiting data during development time. So, how do your projects harness less code and more training data in their development cycle?
The answer is closer collaboration between the data management organization and application development teams. There is currently much discussion reflecting this, perhaps most prominently centered on the idea of data mesh (Dehghani 2019). My own experience over the last few decades has flip-flopped between the application and data worlds, and drawing from that experience, I position seven practices that you should consider when aligning teams across the divide.
Use a design first approach to identify the most important data products to build
Successful digital transformations are commonly led by transforming customer engagement. Design first - looking at the world through your customer’s eyes - has been informing application development teams for some time. For example, frameworks such as ‘Jobs to be Done’ introduced by Clayton Christensen et al focuses design on what a customer is ultimately trying to accomplish. Such frameworks help development teams identify, prioritize and then build features based on the impact they provide to their customers achieving their desired goals.
Likewise, the same design first approach can identify which data products should be built, allowing an organization to challenge itself on how AI can have the most customer impact. Asking questions like ‘What decisions need to be made to support the customer’s jobs-to-be-done?’ can help identify which data and predictions are needed to support those decisions, and most importantly, the data products required, such as classification or regression ml models.
It follows that both the backlogs of application features and data products can derive from the same design first exercise, which should include data scientist and data architect participation alongside the usual business stakeholder and application architect participants. Following the exercise, this wider set of personas must collaborate on an ongoing basis to ensure dependencies across features and data product backlogs are managed effectively over time. That leads us neatly to the next practice.
Organize effectively across data and application teams
We’ve just seen how closer collaboration between data teams and application teams can inform the data science backlog (research goals) and associated ML model development carried out by data scientists. Once a goal has been set, it’s important to resist progressing the work independently. The book Executive Data Science by Caffo and colleagues highlights two common organizational approaches - embedded and dedicated - that inform the team structures adopted to address common difficulties in collaboration. On one hand, in the dedicated model, data roles such as data scientists are permanent members of a business area application team (a cross functional team). On the other hand, in the embedded model, those data roles are members of a centralized data organization and are then embedded in the business application area.
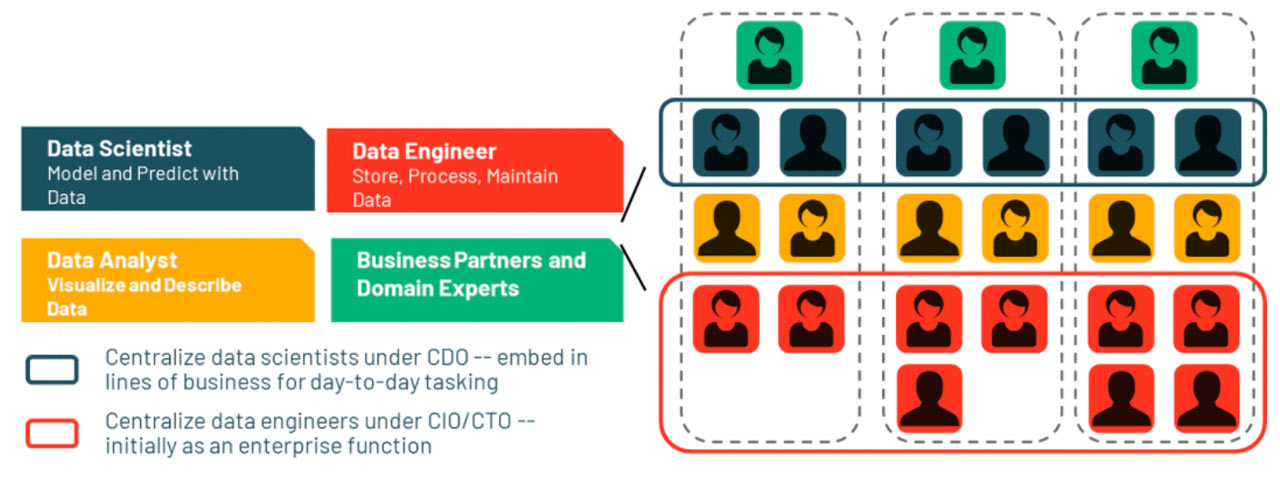
Figure 1 COEs in a federated organization
In a larger organization with multiple lines of business, where potentially many agile development streams require ML model development, isolating that development into a dedicated center of excellence (COE) is an attractive option. Our Shell case study describes how a COE can drive successful adoption of AI, and a COE combines well with the embedded model (as illustrated in Figure 1). In that case, COE members are tasked with delivering the AI backlog. However, to support urgency, understanding and collaboration, some of the team members are assigned to work directly within the application development teams. Ultimately, the best operating model will be dependent on the maturity of the company, with early adopters maintaining more skills in the ‘hub’ and mature adopters with more skills in the ‘spokes.’
Support local data science by moving ownership and visibility of data products to decentralized business focused teams
Another important organizational aspect to consider is data ownership. Where risks around data privacy, consent and usage exist, it makes sense that accountability for the ownership and managing of those risks is accepted within the area of the business that best understands the nature of the data and its relevance. AI introduces new data risks, such as bias, explainability and ensuring ethical decisions. This creates a pressure to build siloed data management solutions where a sense of control and total ownership is established, leading to siloes that resist collaboration. Those barriers inevitably lead to lower data quality across the enterprise, for example affecting the accuracy of customer data through siloed datasets being developed with overlapping, incomplete or inconsistent attributes. Then that lower quality is perpetuated into models trained by that data.
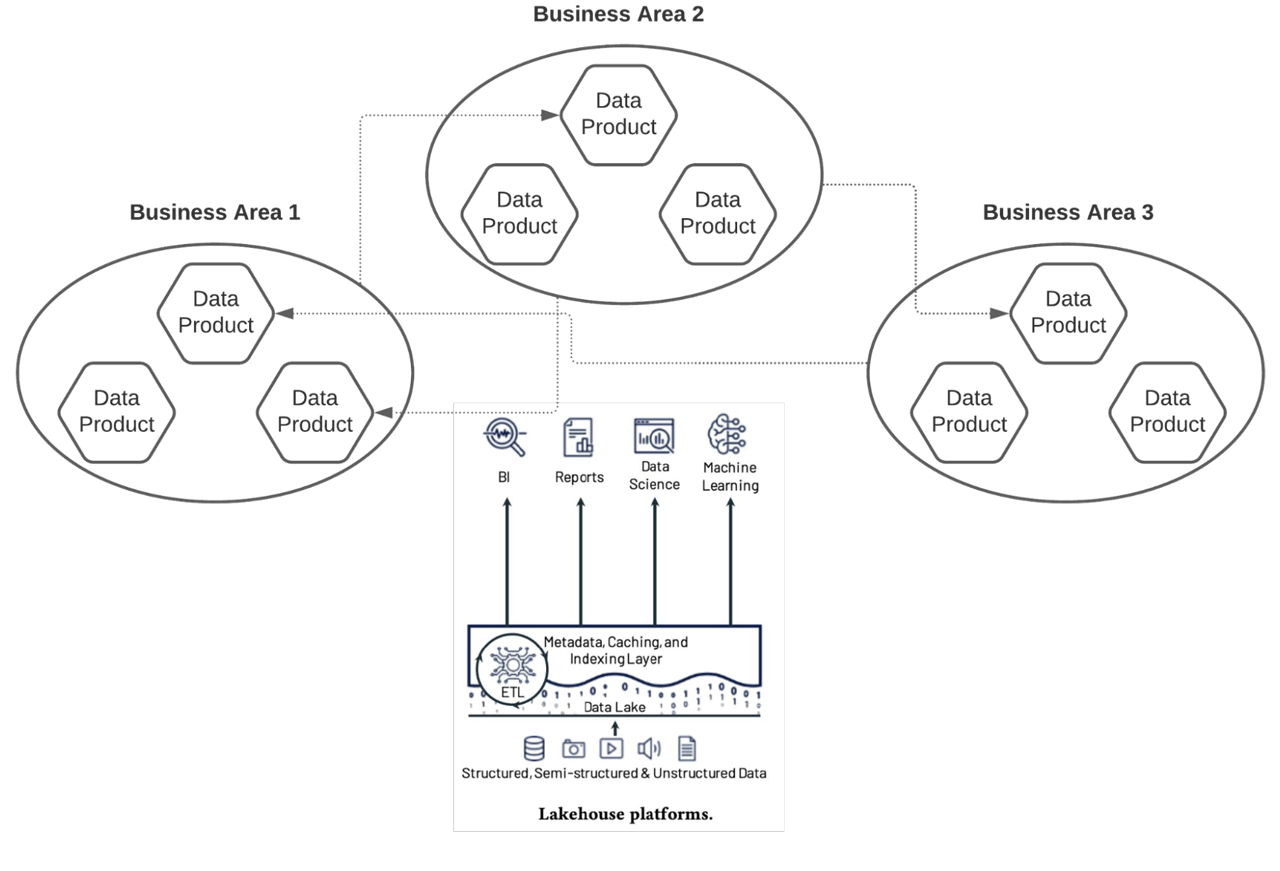
Figure 2 Local ownership of data products in a data mesh
The concept of a data mesh has gained traction as an approach for local business areas to maintain ownership of data products while avoiding the pitfalls of adopting a siloed approach. In a data mesh, datasets can be owned locally, as pictured in Figure 2. Mechanisms can then be put in place allowing them to be shared in the wider organization in a controlled way, and within the risk parameters determined by the data product’s owner. Lakehouse provides a data platform architecture that naturally supports a data mesh approach. Here, an organization’s data supports multiple data product types - such as models, datasets, BI dashboards and pipelines - on a unified data platform that enables independence of local areas across the business. With lakehouse, teams create their own curated datasets using the storage and compute they can control. Those products are then registered in a catalog allowing easy discovery and self-service consumption, but with appropriate security controls to open access only to other permitted groups in the wider enterprise.
Minimize time required to move from idea to solution with consistent DataOps
Once the backlog is defined and teams are organized, we need to address how data products, such as the models appearing in the backlog, are developed … and how that can be built quickly. Data ingestion and preparation are the biggest efforts of model development, and effective DataOps is the key to minimize them. For example, Starbucks built an analytics framework, BrewKit, based on Azure Databricks, that focuses on enabling any of their teams, regardless of size or engineering maturity, to build pipelines that tap into the best practices already in place across the company. The goal of that framework is to increase their overall data processing efficiency; they’ve built more than 1000 data pipelines with up to 50-100x faster data processing. One of the framework’s key elements is a set of templates that local teams can use as the starting point to solve specific data problems. Since the templates rely on Delta Lake for storage, solutions built on the templates don’t have to solve a whole set of concerns when working with data on cloud object storage, such as pipeline reliability and performance.
There is another critical aspect of effective DataOps. As the name suggests, DataOps has a close relationship with DevOps, the success of which relies heavily on automation. An earlier blog, Productionize and Automate your Data Platform at Scale, provides an excellent guide on that aspect.
It’s common to need whole chain of transformations to take raw data and turn it into a format suitable for model development. In addition to Starbucks,, we’ve seen many customers develop similar frameworks to accelerate their time to build data pipelines. With this in mind, Databricks launched Delta Live Tables, which simplifies creating reliable production data pipelines and solves a host of problems associated with their development and operation
Be realistic about sprints for model development versus coding
It’s an attractive idea that all practices from the application development world can translate easily to building data solutions. However, as pointed out by Matei Zaharia, traditional coding and model development have different goals. On one hand, coding’s goal is the implementation of some set of known features to meet a clearly defined functional specification. On the other hand, the goal of model development is to optimize the accuracy of a model’s output, such as a prediction or classification, and then maintaining that accuracy over time. With application coding, if you are working on fortnightly sprints, it’s likely you can break down functionality into smaller units with a goal to launch a minimal viable product and then incrementally, sprint by sprint, add new features to the solution. However, what does ‘breaking down’ mean for model development? Ultimately, the compromise would require a less optimized, and correspondingly, less accurate model. A minimal viable model here means a less optimal model, and there is only so low in accuracy you can go before a sub optimal model doesn’t provide sufficient value in a solution, or drives your customers crazy. So, the reality here is some model development will not fit neatly into the sprints associated with application development.
So, what does that dose of realism mean? While there might be an impedance mismatch between the clock-speed of coding and model development, you can at least make the ML lifecycle and data scientist or ML engineers as effective and efficient as possible, thereby reducing the time to arriving at a first version of the model with acceptable accuracy - or deciding acceptable accuracy won’t be possible and bailing out. Let’s see how that can be done next.
Adopt consistent MLOps and automation to make data scientists zing
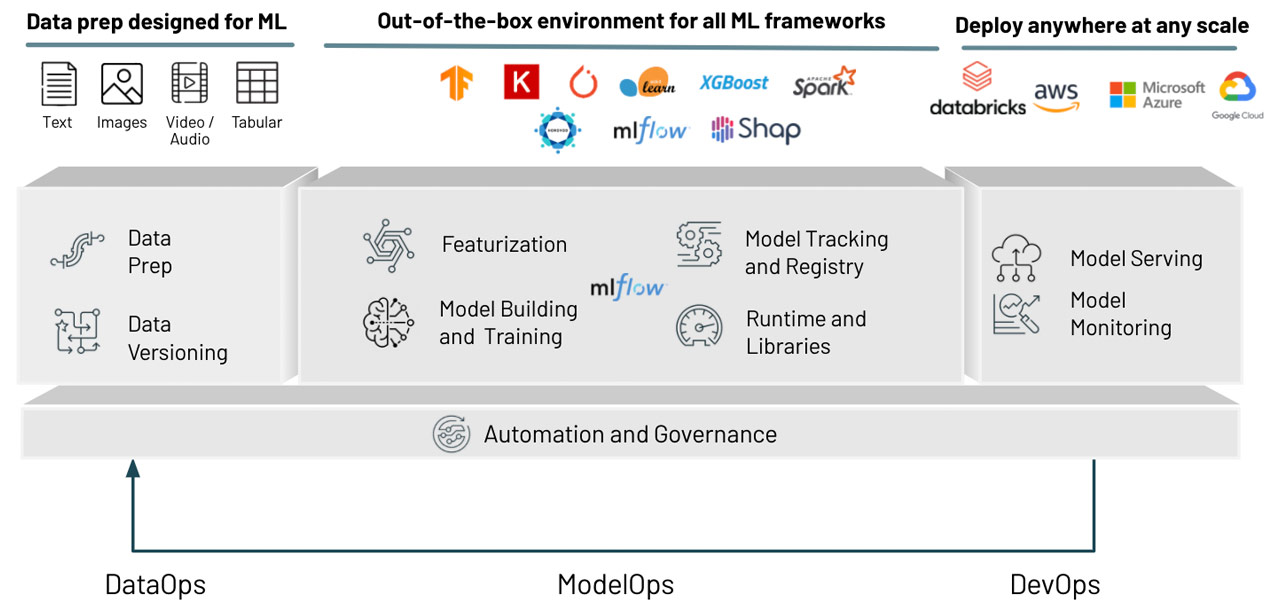
Efficient DataOps described in practice #4 provides large benefits for developing ML models - the data collection, data preparation and data exploration required, as DataOps optimizations will expedite prerequisites for modeling. We discuss this further in the blog The Need for Data-centric ML Platforms, which describes the role of a lakehouse approach to underpin ML. In addition, there are very specific steps that are the focus of their own unique practices and tooling in ML development. Finally, once a model is developed, it needs to be deployed using DevOps-inspired best practices. All these moving parts are captured in MLOps, which focuses on optimizing every step of developing, deploying and monitoring models throughout the ML model lifecycle, as illustrated on the Databricks platform in figure 3.
Figure 3 The component parts of MLOps with Databricks
It is now commonplace in the application development world to use consistent development methods and frameworks alongside automating CI/CD pipelines to accelerate the delivery of new features. In the last 2 to 3 years, similar practices have started to emerge in data organizations that support more effective MLops. A widely-adopted component contributing to that growing maturity is MLflow, the open source framework for managing the ML lifecycle, which Databricks provides as a managed service. Databricks customers such as H&M have industrialized ML in their organizations building more models, faster by putting MLflow at the heart of their model operations. Automation opportunities go beyond tracking and model pipelines. AutoML techniques can further boost data scientists’ productivity by automating large amounts of the experimentation involved in developing the best model for a particular use case.
To truly succeed with AI at scale, it’s not just data teams – application development organizations must change too
Much of the change related to these seven points will most obviously impact data organizations. That’s not to say that application development teams don’t have to make changes too. Certainly, all aspects related to collaboration rely on commitment from both sides. But with the emergence of lakehouse, DataOps, MLOps and a quickly-evolving ecosystem of tools and methods to support data and AI practices, it is easy to recognise the need for change in the data organization. Such cues might not immediately lead to change though. Education and evangelisation play a crucial role in motivating teams how to realign and collaborate differently. To permeate the culture of a whole organization, a data literacy and skills programme is required and should be tailored to the needs of each enterprise audience including application development teams.
Hand in hand with promoting greater data literacy, application development practices and tools must be re-examined as well. For example, ethical issues can impact application coders’ common practices, such as reusing APIs as building blocks for features. Consider the capability ‘assess credit worthiness’, whose implementation is built with ML. If the model endpoint providing the API’s implementation was trained with data from an area of a bank that deals with high wealth individuals, that model might have significant bias if reused in another area of the bank dealing with lower income clients. In this case, there should be defined processes to ensure application developers or architects scrutinize the context and training data lineage of the model behind the API. That can uncover any issues before making the decision to reuse, and discovery tools must provide information on API context and data lineage to support that consideration.
In summary, only when application development teams and data teams work seamlessly together will AI become pervasive in organizations. While commonly those two worlds are siloed, increasingly organizations are piecing together the puzzle of how to set the conditions for effective collaboration. The seven practices outlined here capture best practices and technology choices adopted in Databricks’ customers to achieve that alignment. With these in place, organizations can ride the AI wave, changing our world from one eaten by software to a world instead where machine learning is eating software.
Find out more about how your organization can ride the AI wave by checking out the Enabling Data and AI at Scale strategy guide, which describes the best practices building data-driven organizations. Also, catch up with the 2021 Gartner Magic Quadrants (MQs) where Databricks is the only cloud-native vendor to be named a leader in both the Cloud Database Management Systems and the Data Science and Machine Learning Platforms MQs.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.