The Real 4 Vs of Unstructured Data
by Ivo Everts
With the advancements of powerful big data processing platforms and algorithms come the ability to analyze increasingly large and complex datasets. This goes well beyond the structured and semi-structured datasets that are compatible with a data warehouse, as there is considerable business value to attain from unstructured data analytics.
Why organizations need the ability to process unstructured data
The quantity and diversity of unstructured data continues to grow. The share of unstructured data is between 70% and 90% of all data generated. Its growth is estimated to be around 60% YoY amounting to hundreds of zetabytes of data. And while it is certainly valuable to govern the storage and access to such data in a cloud data warehouse, most of the value comes from the custom processing of unstructured data for specific use cases.
Use cases of unstructured data analytics
The most well known examples of unstructured data analytics come from the medical and automotive fields. The value in unstructured medical data is clear: lives are saved through a deep understanding of the imaging data from the human body for example. However, in other industries, there are also many real-world use cases for unstructured data such as sentiment analysis, predictive analytics and real-time decision-making. There are, of course, no restrictions to the type of data: images, audio and text all may contain valuable information.
On Databricks, any type of data can be processed in a meaningful way without having to move or copy data, as the most recent machine learning libraries are natively supported. This allows for our customers to include all properties of unstructured datasets – from social media posts and metadata to catalog images – in their analysis and models.
That brings us to the real 4 Vs of unstructured data: value, value, value and value. Here, we have curated a set of example use cases from various industries based on unstructured data, along with the attained business value.
|
Industry |
Use case |
Solution on Databricks |
Value |
|---|---|---|---|
|
Materials |
→ Batch ingestion of drone imagery → Training of custom image recognition algorithms → Computer-assisted image annotation. |
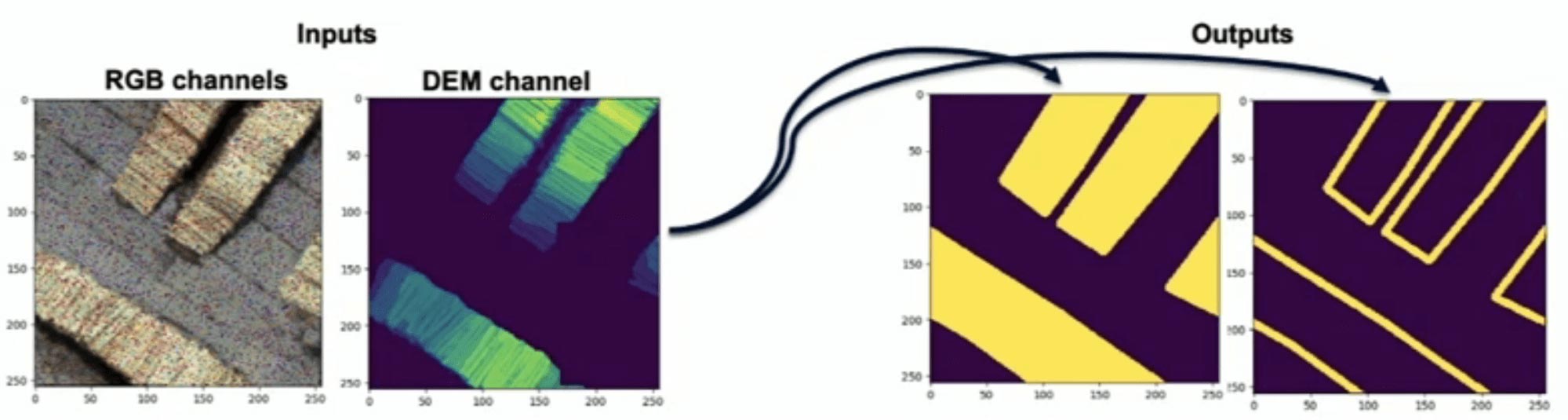
Saving ~2 days of manual data labeling per month |
|
|
Media & Entertainment |
→ Streaming ingestion of speech samples → Periodic training of custom speech recognition (NLP) models → Voice control for improved customer engagement |
10x cost reduction of data processing pipelines attributable to Delta
|
|
|
E-commerce |
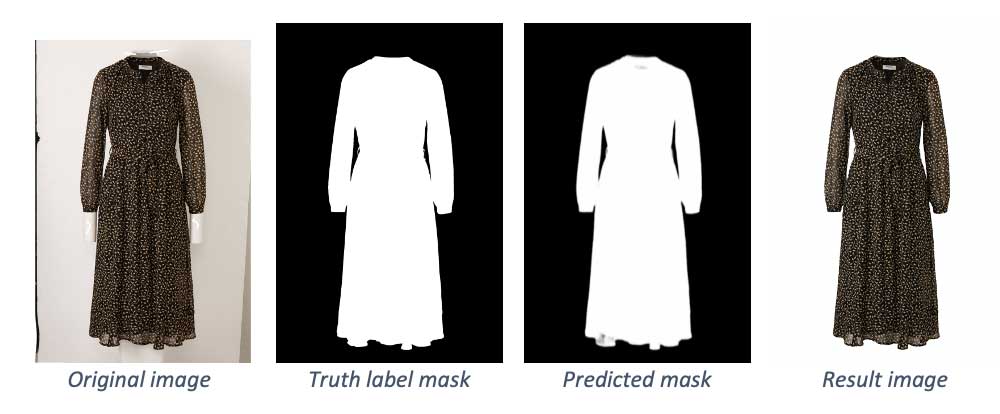
→ Batch ingestion of clothing photos → GPU-accelerated training of custom foreground/background image segmentation models → High quality stock photos ready for e-commerce presentation |
10x TCO savings due to custom processing instead of outsourcing
|
|
|
Automotive |
→ Batch ingestion of ~35000 hours of video footage from trucks → Apply visual recognition algorithms → Towards autonomous driving trucks |
75x increase in analyzed data volumes
|
|
|
Life Sciences |
→ 10TB of genomic sequencing data → Spark on Databricks for performant and reliable distributed processing → Accelerated drug target identification |
600x query runtime performance
|



Processing unstructured data on the Databricks Lakehouse Platform
Most use cases based on unstructured data follow a similar computational pattern. Compared to analysis and modeling of structured data, it is typically required to have a relatively profound feature extraction step preceding such modeling. In other words, the unstructured data needs structuring. But besides that, there is no fundamental difference compared to rudimentary machine learning.
The Databricks Lakehouse Platform natively allows for processing unstructured data, as the data can be ingested in the same way as (semi-)structured data. Here, we follow the medallion architecture in which raw data is progressively refined up to a consumable form:
- Create a cluster with the Databricks ML Runtime to have the relevant Python libraries for feature extraction and machine learning available on the driver and worker nodes.
- Pick up data files from cloud storage in a batch or streaming ingestion scheme and append to the bronze (a.k.a. ‘raw’) Delta table.
- Exploit Apache Spark’s™ distributed processing capability by having the cluster workers perform the feature extraction in parallel, and combine these features with other datasets containing additional information that is needed for meaningful modeling and analysis. The resulting dataset is typically stored in a silver Delta table.
- The silver table now contains the features and target variable(s) that can be used by a machine learning algorithm for training a model for tasks such as speech recognition, image classification, natural language processing or any of the use cases listed above. Typically, these inference results are extracted from new data files (i.e., other than the data that was used for model training) and stored in golden tables.
For a detailed explanation of the general approach to modeling unstructured data using deep learning on Databricks, see the article How to Manage End-to-end Deep Learning Pipelines with Databricks.
Did you know that in addition to its native support for unstructured data analytics, Databricks has set a world record when it comes to data warehousing performance? That is what we mean with a Lakehouse: where data engineers, data scientists and data analysts work together on any data driven use case, from advanced machine learning to performant and reliable BI workloads, delivering business value to our customers.
If you are looking specifically for best practices around image processing on Databricks, check out this past Data + AI Summit session on image processing. See the Similiarlity-based Image Recognition System blog to find out how to use images in a recommender system. For natural language processing, there is this recent blog post that contains a solution accelerator for adverse drug event detection.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.