Unlocking the Power of Data: AT&T’s Modernization Journey to the Lakehouse
by Kate Hopkins
This is a guest post from Kate Hopkins, Vice President of Data Platforms at AT&T.
The beginning: Moving and managing petabytes of data with care
AT&T started its data transformation journey in late 2020 with a sizable mission: to move from our core on-premises Hadoop data lake to a modernized cloud architecture. Our strategy was to empower data teams by democratizing data, as well as scale AI efforts without overburdening our DevOps team. We saw enormous potential in increasing our use of insights for improving the AT&T customer experience, growing the AT&T business and operating more efficiently.
While some businesses might accomplish smaller migrations more readily, we at AT&T had a lot to consider. Our data platform ecosystem of technologies ingests over 10 petabytes of data per day, and we manage over 100 million petabytes of data across the network. It was extremely important for us to take our time selecting the right tool for the job. Not only because of the large data volumes but also because we have 182 million wireless subscribers and 15 million broadband households to support who are using data. In addition, we have important systems that protect our customers against breaches and fraud. Essentially, we needed to democratize our data in order to use it to its full potential but balance that democratization with privacy, security, and data governance.
Our legacy architecture, which includes over six different data management platforms, enabled data teams to work closely with data and act on it quickly. But at the same time, it locked those efforts in silos. These distributed pockets of work led to challenges accessing and acquiring data, as well as data duplication and latency issues. Without a single truth from which to draw information, metrics were created out of different versions of data that reflected different points in time and levels of quality.
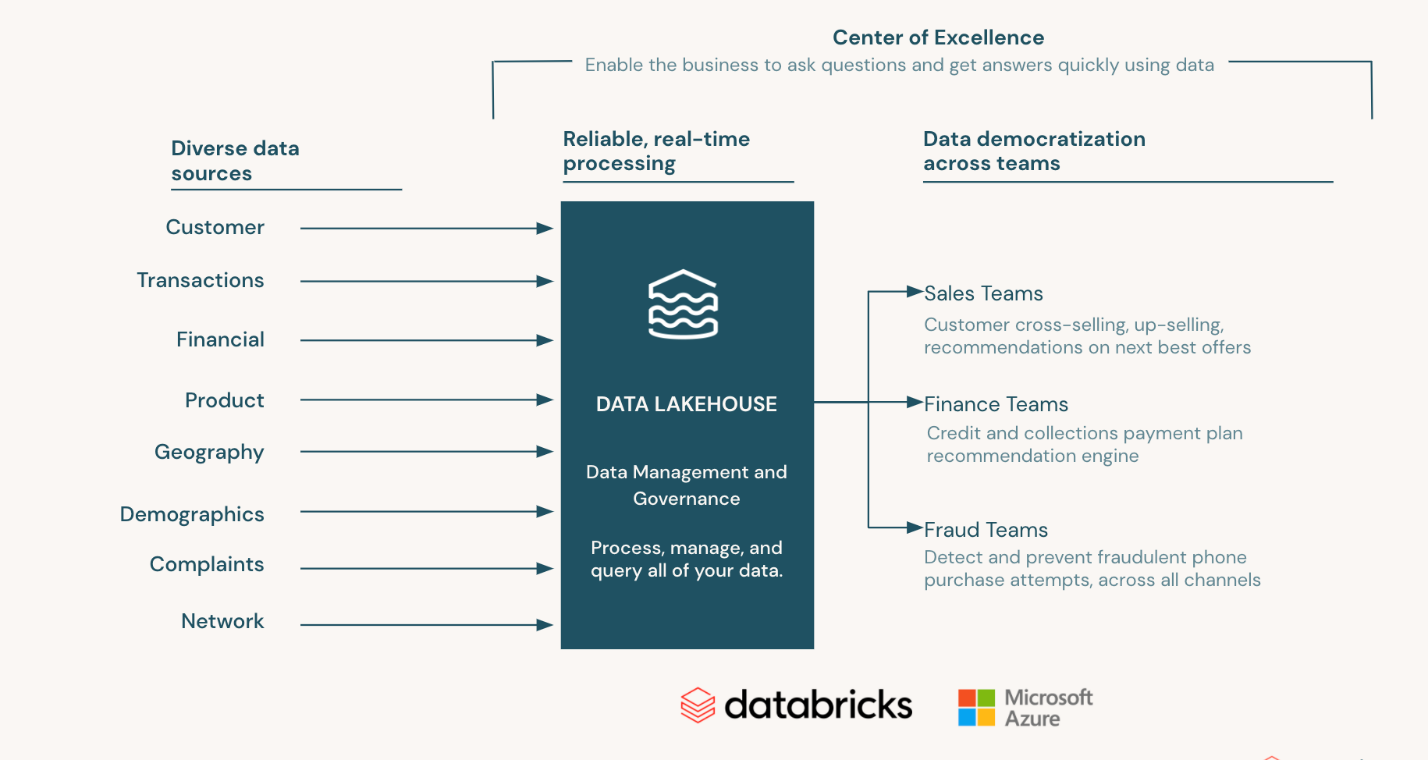
Ultimately, to realize the data-driven innovations we desired, we needed to modernize our infrastructure by moving to the cloud and adopting a data architecture built on the premise of open formats, simplicity, and cross-team collaboration. We chose Databricks Lakehouse as a critical component for this monumental initiative.
Accessible data leads to better insights and a center of excellence
2021 was all about getting AT&T’s on-premises data into the Databricks Lakehouse Platform. I’m excited to say that with Lakehouse as our unified platform, we’ve successfully moved all our core data lake data to the cloud.
Our data science team, who were the first adopters, adjusted to this change with ease. They have since been able to move their machine learning (ML) workloads to the cloud. This has enabled faster data retrieval, more data (if you can believe it), and accessibility to modernized technologies that have brought fraud down to the lowest level in years. For example, we’ve been able to train and deploy models that detect fraudulent phone purchase attempts and then communicate that fraud across all channels to stop it completely. We’ve also seen a significant increase in operational efficiency, a reduction in customer churn, and an increase of customer LTV.
Within CDO, we’ve been onboarding a large data engineering and data science community. We’re ingesting both structured customer data into Delta Lake, as well as a large amount of raw, unstructured, real-time data to help continue powering these important use cases.
But the value doesn’t stop at our ability to scale data science. Our business users have also been able to extract data insights through integrations that run Power BI and Tableau dashboards off the data in Delta Lake. The sales organization uses data-driven insights fed through Tableau to uncover new upsell opportunities. They are also able to generate recommendations on ideal responses based on the questions customers are asking.
Most importantly, moving to Databricks Lakehouse has enabled AT&T to move to the analytics center of excellence (COE) model. As we decentralize our technology team to support businesses more closely, we’re ultimately aiming to empower each business unit to serve themselves. This includes knowing who to reach out to if they have a question, where to find training, how to get a deeper understanding of how much they’re spending, and more. And for all of those reasons, the center of excellence has been key. It’s led to greater product adoption, and so much meaningful trust and appreciation from our partners.
Retiring on-prem entirely, making cost-saving gains, and accelerating success in 2022
In 2020, we succeeded in making the case and proving the benefits of moving to the cloud. The ability to rapidly execute our transformation plan helped us exceed our savings targets for 2021, and I'm expecting to do the same in 2022. The real win, however, is going to be the increased business benefits we expect to see this year as we continue moving our data over to Delta Lake so we can retire our on-prem system entirely.
This move will enable us to do really exciting things, like standardize our artificial intelligence (AI) tooling, scale data science and AI adoption across the business, support business agility through federation, and leverage more capabilities as our roadmap evolves.
I’m certain that the Databricks Lakehouse architecture will enable our future here at AT&T. It’s the target architecture for our AI use cases, and we are confident it will increase our business agility because in less than a year we have already seen the results of the federation and business value it enables. Critically, it also supports required data security and the governance for a single version of truth across our complex data ecosystem.
Related Content: AI Modernization at AT&T and the Application to Fraud with Databricks
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.