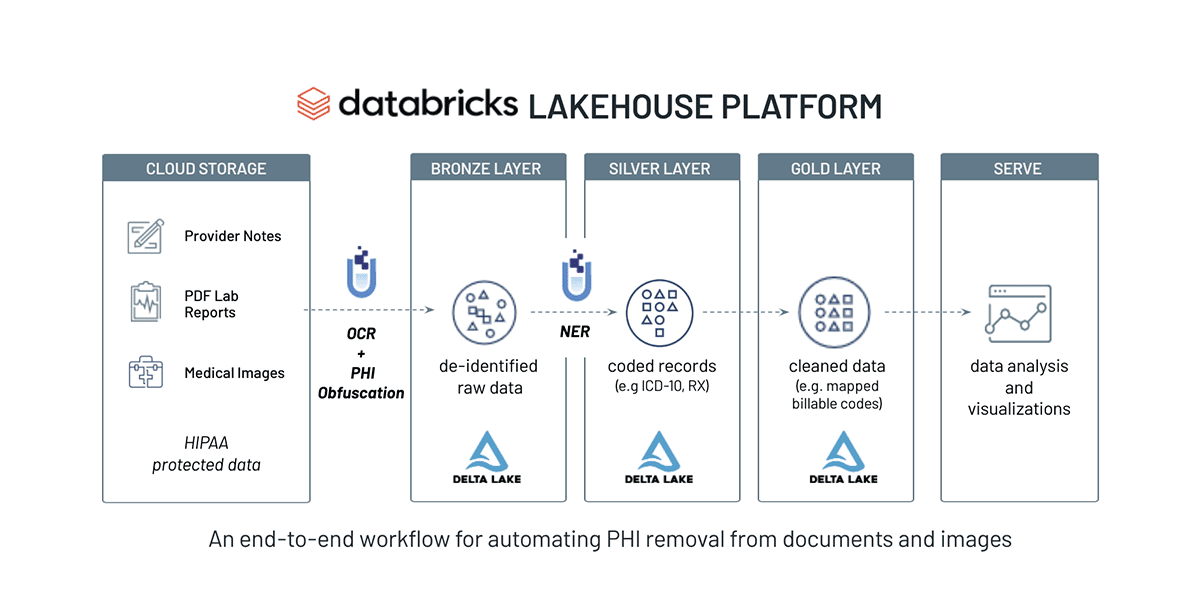
Automating PHI Removal from Healthcare Data With Natural Language Processing
Introducing Databricks and John Snow Labs’ Solution Accelerator for PHI De-Identification and Obfuscation at Scale
by Amir Kermany, Moritz Steller, David Talby, Michael Ortega and Mike Sanky
Minimum necessary standard and PHI in healthcare research
Under the Health Insurance Portability and Accountability Act (HIPAA), minimum necessary standard, HIPAA-covered entities (such as health systems and insurers) are required to make reasonable efforts to ensure that access to Protected Health Information (PHI) is limited to the minimum necessary information to achieve the intended purpose of a particular use, disclosure, or request.
In Europe, the GDPR lays out requirements for anonymization and pseudo-anonymization that companies must meet before they can analyze or share medical data. In some cases, these requirements go beyond US regulations by also requiring that companies redact gender identity, ethnicity, religious, and union affiliations. Almost every country has similar legal protections on sensitive personal and medical information.
The challenges of working with personally identifiable health data
Minimum necessary standards such as these can create obstacles to advancing population-level healthcare research. This is because much of the value in healthcare data is in the semi-structured narrative text and unstructured images, which often contain personally identifiable health information that is challenging to remove. Such PHI makes it difficult to enable clinicians, researchers, and data scientists within an organization to annotate, train, and develop models that have the power to predict disease progression, as an example.
Beyond compliance, another key reason for the de-identification of PHI and medical data before analysis — especially for data science projects — is to prevent bias and learning from spurious correlations. Removing data fields such as patients' addresses, last names, ethnicity, occupation, hospital names, and doctor names prevents machine learning algorithms from relying on these fields when making predictions or recommendations.
Automating PHI removal with Databricks and John Snow Labs
John Snow Labs, the leader in Healthcare natural language processing (NLP), and Databricks are working together to help organizations process and analyze their text data at scale with a series of Solution Accelerator notebook templates for common NLP use cases. You can learn more about our partnership in our previous blog, Applying Natural Language Processing to Health Text at Scale.
To help organizations automate the removal of sensitive patient information, we built a joint Solution Accelerator for PHI removal that builds on top of the Databricks Lakehouse for Healthcare and Life Sciences. John Snow Labs provides two commercial extensions on top of the open-source Spark NLP library — both of which are useful for de-identification and anonymization tasks — that are used in this Accelerator:
- Spark NLP for Healthcare is the world's most widely-used NLP library for the healthcare and life science industries. Optimized to run on Databricks, Spark NLP for Healthcare seamlessly extracts, classifies, and structures clinical and biomedical text data with state-of-the-art accuracy at scale.
- Spark OCR provides production-grade, trainable, and scalable algorithms and models for a variety of visual image tasks, including document understanding, form understanding, and information extraction. It extends the core libraries' ability to analyze digital text to also read and write PDF and DOCX documents as well as extract text from images - either within such files or from JPG, TIFF, DICOM, and similar formats.
A high-level walkthrough of our Solution Accelerator is included below.
PHI removal in action
In this Solution Accelerator, we show you how to remove PHI from medical documents so that they can be shared or analyzed without compromising a patient's identity. Here is a high-level overview of the workflow:
- Build an OCR pipeline to process PDF documents
- Detect and extract PHI entities from unstructured text with NLP models
- Use obfuscation to de-identify data, such as PHI text
- Use redaction to de-identify PHI in the visual document view
You can access the notebooks for a full walkthrough of the solution.
Parsing the files through OCR
As a first step, we load all PDF files from our cloud storage, assign a unique ID to each one, and store the resulting DataFrames into the Bronze layer of the Lakehouse. Note that the raw PDF content is stored in a binary column and can be accessed in the downstream steps.

In the next step, we extract raw text from each file. Since PDF files can have more than one page, it is more efficient to first transform each page into an image (using PdfToImage()) and then extract the text from the image by using ImageToText() for each image.
Similar to SparkNLP, transform is a standardized step in Spark OCR for aligning with any Spark-related transformers and can be executed in one line of code.
Note that you can view each individual image directly within the notebook, as shown below:

After applying this pipeline, we then store the extracted text and raw image in a DataFrame. Note that the linkage between image, extracted text and the original PDF is preserved via the path to the PDF file (and the unique ID) within our cloud storage.

Often, scanned documents are low quality (due to skewed image, poor resolution, etc.) which results in less accurate text and poor data quality. To address this problem, we can use built-in image pre-processing methods within sparkOCR to improve the quality of the extracted text.
Skew correction and image processing
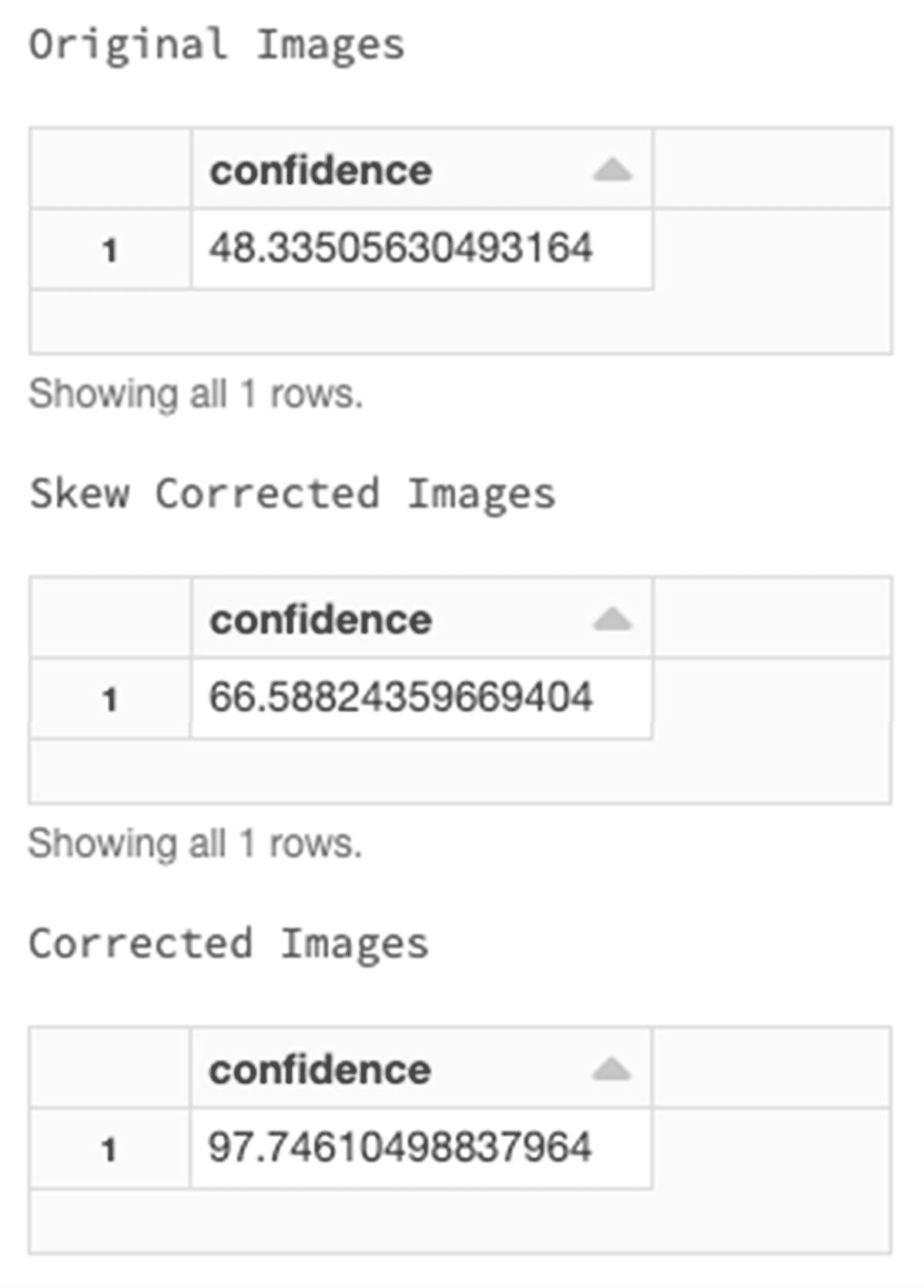
In the next step, we process images to increase confidence. Spark OCR has ImageSkewCorrector which detects the skew of the image and rotates it. Applying this tool within the OCR pipeline helps to adjust images accordingly. Then, by also applying the ImageAdaptiveThresholding tool, we can compute a threshold mask image based on a local pixel neighborhood and apply it to the image. Another image processing method that we can add to the pipeline is the use of morphological operations. We can use ImageMorphologyOperation which supports Erosion (removing pixels on object boundaries), Dilation (adding pixels to the boundaries of objects in an image), Opening (removing small objects and thin lines from an image while preserving the shape and size of larger objects in the image) and Closing (the opposite of opening and useful for filling small holes in an image).
Removing background objects ImageRemoveObjects can be used as well as adding ImageLayoutAnalyzer to the pipeline, to analyze the image and determine the regions of text. The code for our fully developed OCR pipeline can be found within the Accelerator notebook.
Let's see the original image and the corrected image.

After the image processing, we have a cleaner image with an increased confidence of 97%.
Now that we have corrected for image skewness and background noise, and extracted the corrected text from images we write the resulting DataFrame into the Silver layer in Delta.
Extracting and obfuscating PHI entities
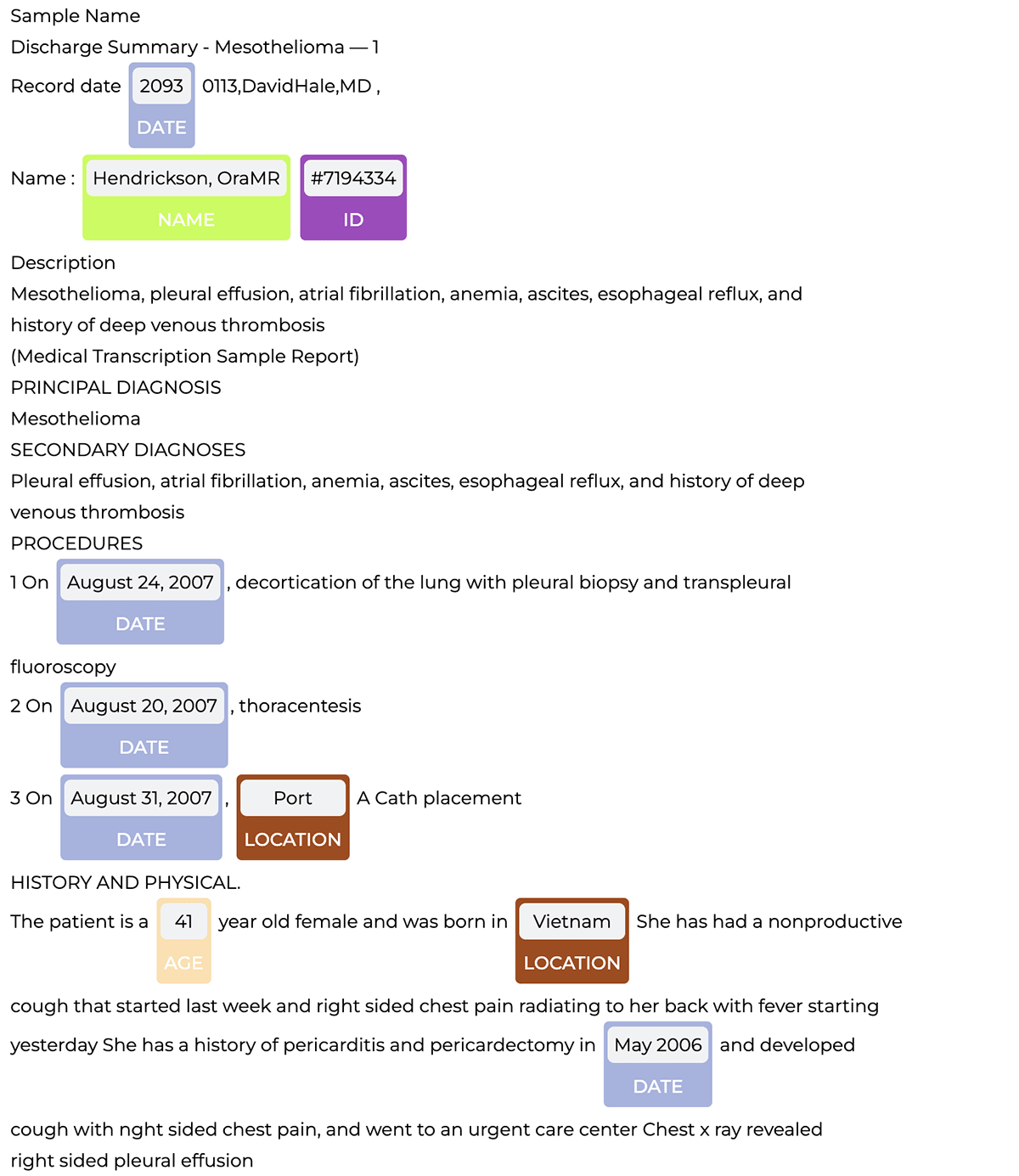
Once we've finished using Spark OCR to process our documents, we can use a clinical Named Entity Recognition (NER) pipeline to detect and extract entities of interest (like name, birthplace, etc.) in our document. We covered this process in more detail in a previous blog post about extracting oncology insights from lab reports.
However, there are often PHI entities within clinical notes that can be used to identify and link an individual to the identified clinical entities (for example disease status). As a result, it is critical to identify PHI within the text and obfuscate those entities.
There are two steps in the process: extract the PHI entities, and then hide them; while ensuring that the resulting dataset contains valuable information for downstream analysis.
Similar to clinical NER, we use a medical NER model (ner_deid_generic_augmented) to detect PHI and then we use the "faker method" to obfuscate those entities. Our full PHI extraction pipeline can also be found in the Accelerator notebook.
The pipeline detects PHI entities, which we can then visualize with the NerVisualizer as shown below.
Now to construct an end-to-end deidentification pipeline, we simply add the obfuscation step to the PHI extraction pipeline which replaces PHI with fake data.
In the following example, we redact the birthplace of the patient and replace it with a fake location:

In addition to obfuscation, SparkNLP for Healthcare offers pre-trained models for redaction. Here is a screenshot showing the output of those redaction pipelines.

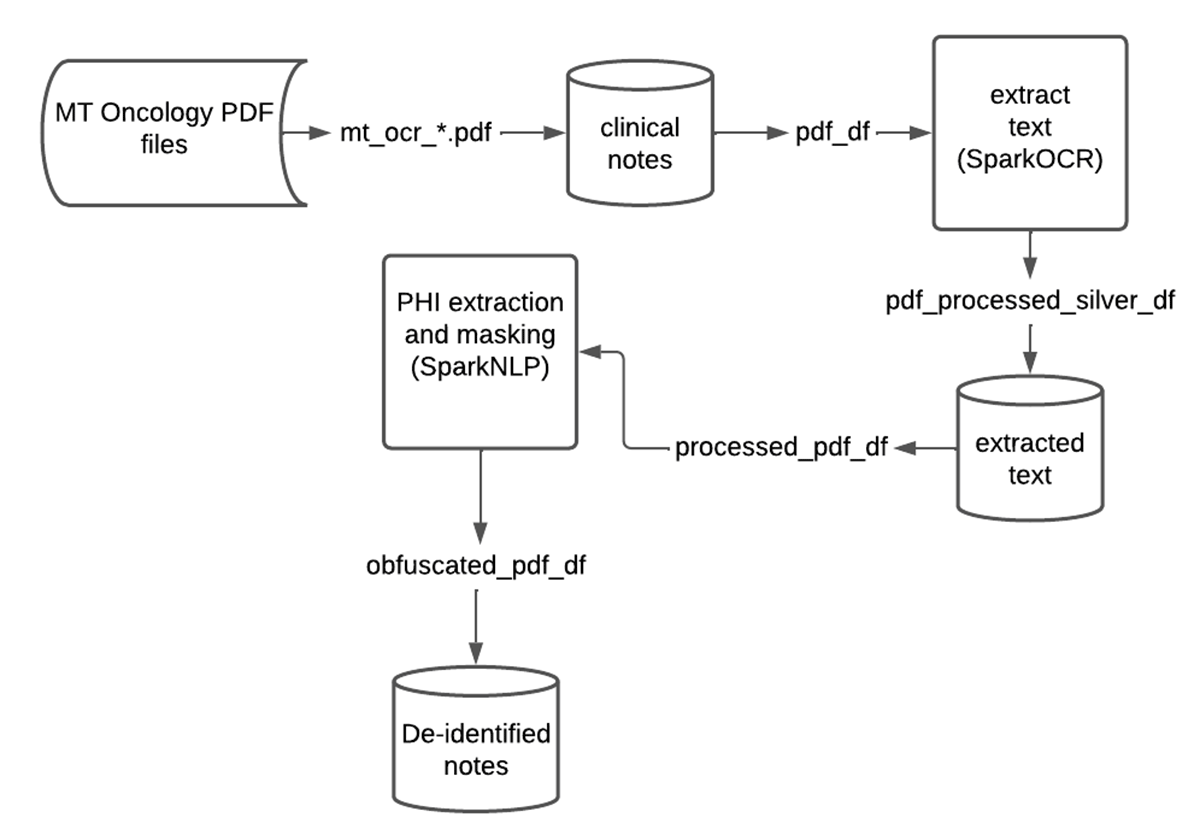
SparkNLP and Spark OCR work well together for de-identification of PHI at scale. In many scenarios, Federal and industry regulations prohibit the distribution or sharing of the original text file. As demonstrated, we can create a scalable and automated production pipeline to classify text within PDFs, obfuscate or redact PHI entities, and write the resulting data back into the Lakehouse. Data teams can then comfortably share this "cleansed" data and de-identified information with downstream analysts, data scientists, or business users without compromising a patient's privacy. Included below is a summary chart of this data flow on Databricks.
Start building your PHI removal pipeline
With this Solution Accelerator, Databricks and John Snow Labs make it easy to automate the de-identification and obfuscation of sensitive data contained within PDF medical documents.
To use this Solution Accelerator, you can preview the notebooks online and import them directly into your Databricks account. The notebooks include guidance for installing the related John Snow Labs NLP libraries and license keys.
You can also visit our Lakehouse for Healthcare and Life Sciences page to learn about all of our solutions.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.