Production ML Application in 15 Minutes With Tecton and Databricks
Getting machine-learning systems to production is (still) hard. For many teams, building real-time ML systems that operate on real-time data is still a daydream – in most cases, they are tied to building batch prediction systems. There are a lot of challenges on the road to real-time ML, including building scalable real-time data pipelines, scalable model inference endpoints, and integrating it all into production applications.
This blog will show you how you can dramatically simplify these challenges with the right tools. With Tecton and Databricks, you'll be able to build the MVP for a real-time ML system in minutes, including real-time data processing and online inference.
Building a Real-Time ML System in One Notebook
In this example, we'll focus on building a real-time transaction fraud system that decides whether to approve or reject transactions. Two of the most challenging requirements of building real-time fraud detection systems are:
- Real-time inference: predictions need to be extremely fast – typically model inference should happen in
- Real-time features: often the most critical data needed to detect fraudulent transactions describes what has happened in the last few seconds. To build a great fraud detection system, you'll need to update features within seconds of a transaction occurring.
With Tecton and Databricks, these challenges can be greatly simplified:
- Databricks and its native MLflow integration will allow us to create and test real-time serving endpoints to make real-time predictions.
- Tecton helps build performant stream aggregations that will compute features in real-time
Let's walk through the following 4-steps on how to build a real-time production ML system:
- Building performant stream processing pipelines in Tecton
- Training a model with features from Tecton using Databricks and MLflow
- Creating a model serving endpoint in Databricks using MLflow
- Making real-time predictions using the model serving endpoint and real-time features from Tecton
Building stream processing pipelines in Tecton
Tecton's feature platform is built to make it simple to define features, and to help make those features available to your ML models – however quickly you need them. You'll need a few different types of features for a fraud model, for example:
- Average transaction size in a country for the last year (computed once daily)
- Number of transactions by a user in the last 1 minute (computed continuously from a stream of transactions)
- Distance from the point of the transaction to the user's home (computed on-demand at the time of a transaction)
Each type of feature requires a different type of data pipeline, and Tecton can help build all three of these types of features. Let's focus on what would typically be the most challenging type of feature, real-time streaming features.
Here's how you can implement the feature "Number of transactions by a user in the last 1 minute and last 5 minutes" in Tecton:
In this example we take advantage of Tecton's built-in support for low-latency streaming aggregations, allowing us to maintain a count of the number of transactions a user has made in real-time.
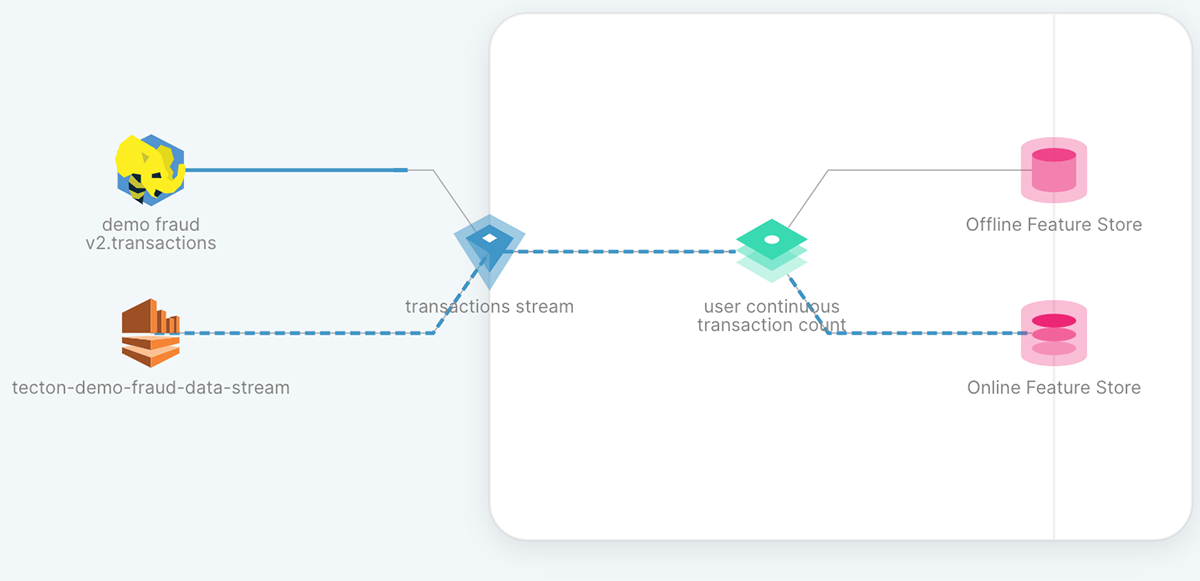
When this feature is applied, Tecton starts orchestrating data pipelines in Databricks to make this feature available in real time (for model inference) and offline (for model training). Historical features are stored in Delta Lake, meaning all of the features you build are natively available in your data lakehouse.
Training a model with features from Tecton using Databricks and MLflow
Once our features are built-in Tecton, we can train our fraud detection model. Check out the notebook below where we:
- Generate training data using Tecton's time-travel capabilities
- Train a SKLearn model to predict whether or not a transaction is fraudulent
- Track our experiments using MLflow
Creating a model serving endpoint in Databricks using MLflow
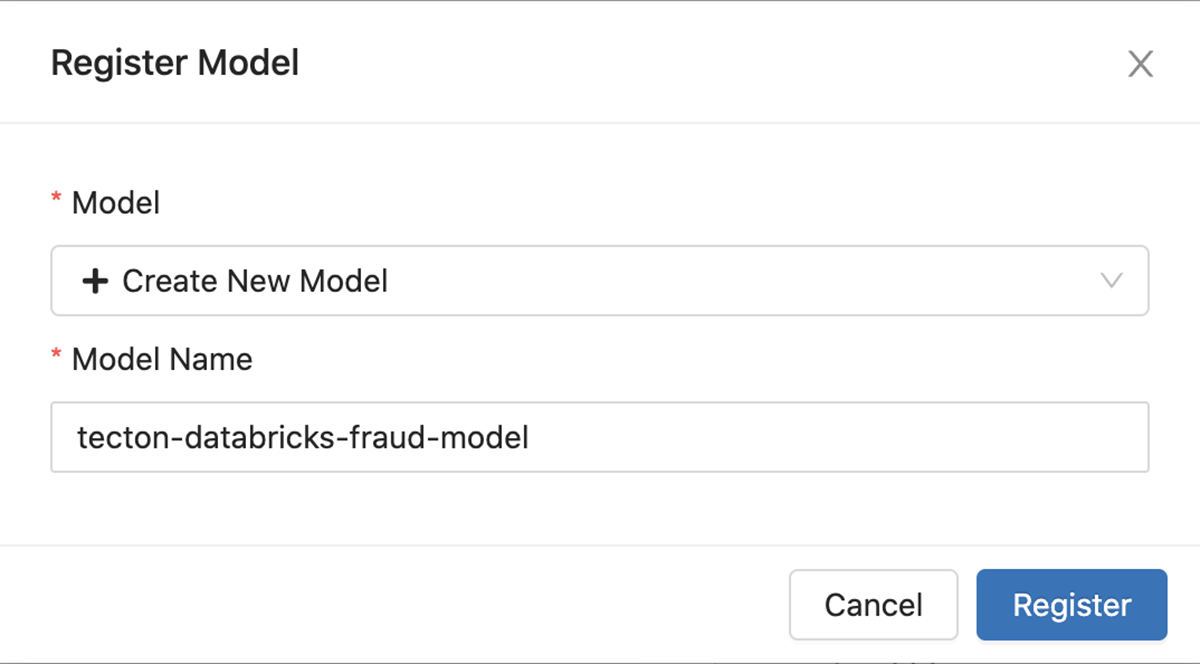
Now that we have a trained model, we'll use MLflow in Databricks to create a model endpoint. First, we'll register the model in the MLflow Model Registry:

Next, we'll use MLflow to create a serving endpoint:
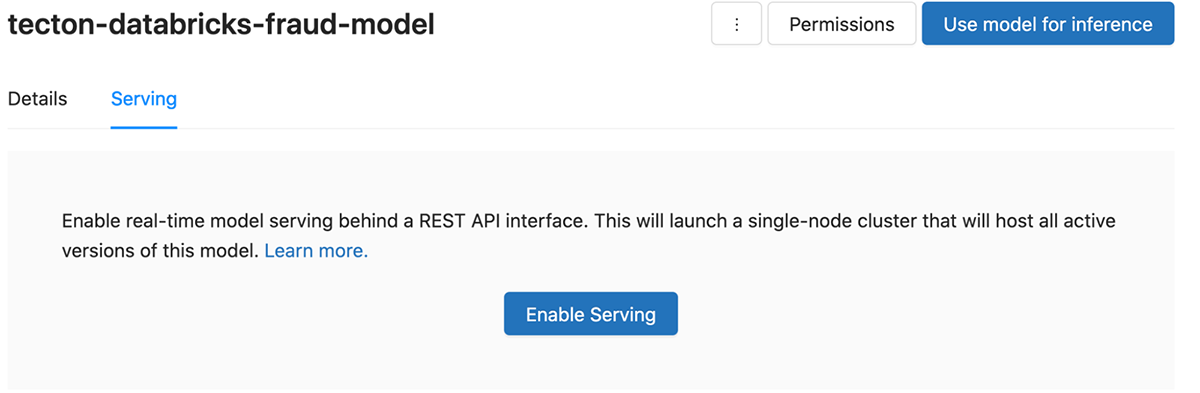
Once our model is deployed, we'll take note of the endpoint url:

Now, we have a prediction endpoint that can perform real-time transaction scoring – the only thing left is collecting the features needed at prediction-time.
Making real-time predictions using the model serving endpoint and real-time features from Tecton
The model endpoint that we just created takes features as inputs and outputs a prediction of the probability that a transaction is fraudulent. Retrieving those features poses some challenging problems:
- Latency constraints: we need to look up (or compute) the features very quickly (
- Feature freshness: we expect the features we defined (like the one-minute transaction count) to be updated in real-time as transactions are occurring.
Tecton provides feature serving infrastructure to solve these challenging problems. Tecton is built to serve feature vectors at high scale and low latency. When we built our features, we already set up the real-time streaming pipelines that will be used to produce fresh features for our models.
Thanks to Tecton, we can retrieve features in real-time with a simple REST call to Tecton's feature serving endpoint:
Check out the rest of the notebook where we'll wire it all together to retrieve features from Tecton and send them to our model endpoint to get back real-time fraud predictions:
Conclusion
Building real-time ML systems can be a daunting task! Individual components like building streaming-data pipelines can be months-long engineering projects if done manually. Luckily building real-time ML systems with Tecton and Databricks can simplify a lot of that complexity. You can train, deploy, and serve a real-time fraud detection model in one notebook – and it only takes about 15 minutes.
To learn more about how Tecton is powering real-time ML systems, check out talks about Tecton at Data and AI Summit: Scaling ML at CashApp with Tecton and Building Production-Ready Recommender Systems with Feature Stores
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.